
Roughly ~10 minutes from now, you could have a large language model (LLM) running locally on your computer which is completely free and requires exactly zero lines of code to use in KNIME Analytics Platform 5.3. Here’s how!
KNIME Analytics Platform is free and open-source software that you can download to access, blend, analyze, and visualize their data, without any coding. Its low-code, no-code interface makes analytics accessible to anyone, offering an easy introduction for beginners, and an advanced data science set of tools for experienced users.
For the purpose of demonstration, I’m going to use GPT4All. GPT4All is free software for running LLMs privately on everyday desktops & laptops. There are many different approaches for hosting private LLMs, each with their own set of pros and cons, but GPT4All is very easy to get started with.
- If you want to dive straight into the example workflow I’ve put together, here’s the link: Local GPT4All Integration Example
- For a more comprehensive set of examples, please check out the KNIME for Generative AI collection on KNIME Hub.
Additional context
As a cloud-native developer and automation engineer at KNIME, I’m comfortable coding up solutions by hand. That being said, I’m always looking for the cheapest, easiest, and best solution for any given problem. I’ve looked at a number of solutions for how to host LLMs locally, and I admit I was a bit late to start testing GPT4All and the new KNIME AI Extension nodes, but I’m very impressed at what the KNIME team has put together so far and the integration between GPT4All and KNIME is very straightforward.
So far I’ve tried KNIME, Python, and Golang for a couple of personal LLM use cases. Through my experiences I’ve gained a few key insights:
- The open source models I’m using (Llama 3.1 8B Instruct 128k and GPT4All Falcon) are very easy to set up and quite capable, but I’ve found that ChatGPT’s GPT-3.5 and GPT-4+ are superior and may very well be “worth the money”. The main difference I’ve noticed for my own use cases is that ChatGPT’s models are performant and very consistent in terms of the results returned, especially when the prompts are short/minimal.
- Responses from these open source models are a bit slow when being hosted locally. However, they are completely free to use. That’s a pretty significant benefit when considering the trade-offs. If you’re looking for an open source option that can handle more throughput, I’d recommend looking into hosting models locally in a Kubernetes cluster (minikube is a great option for getting started). The advantage of using Kubernetes is that your local development solution would look & feel very similar to a larger-scale production solution.
- I really enjoy GPT4All’s feature for hosting models on a local server (http://localhost:4891 by default) and honestly prefer it in terms of connectivity with KNIME Analytics Platform 5.3. However, there is apparently some amount of resource overhead for calling models this way. Optimizing throughput and/or energy footprint is something to consider.
- For the coders among us: Coding a similar solution in a programming language such as Golang or Python is still a perfectly valid option— in particular, Python has an excellent OpenAI library. Golang also has an OpenAI package, but the Python library is likely more attractive to readers of this publication. One key advantage to using KNIME Analytics Platform over Python/Golang (in my personal opinion) is that KNIME has unparalleled support for connecting quickly to other data sources, e.g. Google Sheets, which may be very useful for building a solution that integrates multiple data sources together.
If you end up referencing this article/workflow for your own purposes, please leave a comment to share your experiences! I’d be curious to hear how it worked out for you.
Getting started with GPT4All
Firstly, we’ll need to install GPT4All. Please check out the GPT4All documentation link below which should lead directly to a page for downloading a version compatible with your operating system.
The software is easy to install; no in-depth instructions necessary.
Once you have downloaded GPT4All, start it up and you should see a screen like this:
By default, no models will be installed. We’ll navigate to the Models tab and add a new model.
Feel free to use any model you’d like, but for my example workflow I’ve downloaded both the Llama 3.1 8B Instruct 128k and GPT4All Falcon models. Each model is ~8GB in size, so please keep disk space in mind.
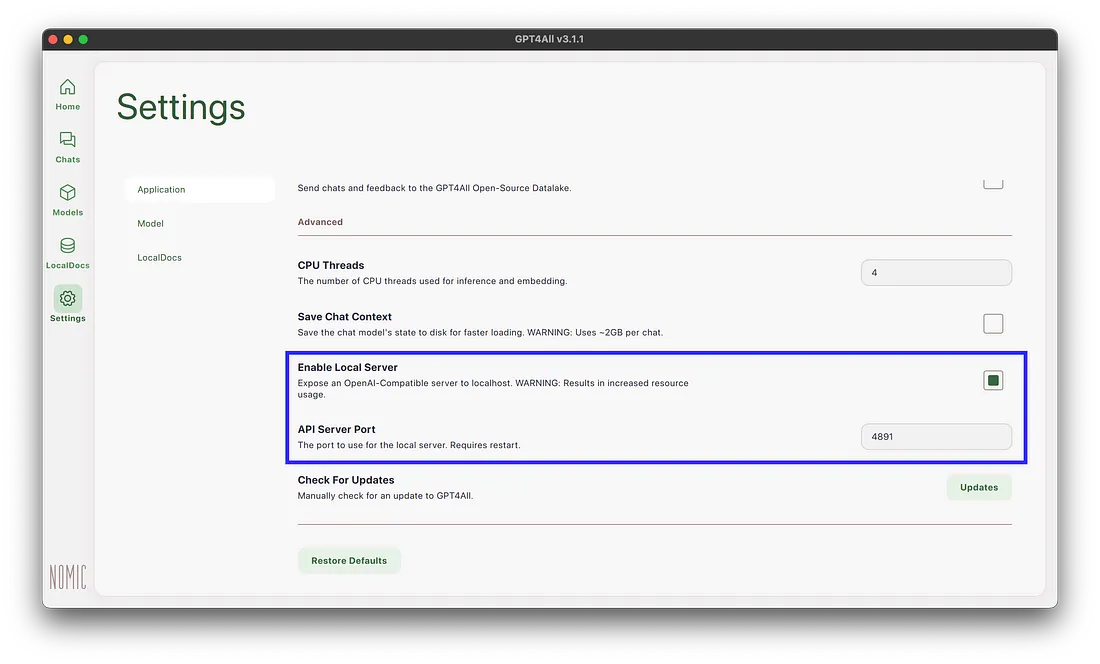
Lastly, we’ll navigate to the Settings tab and check the Enable Local Server option. This will host the models on our computer as a local server (http://localhost:4891 by default). The local server implements a subset of the OpenAI API specification.
Of course, you can customize the localhost port that models are hosted on if you’d like. My example workflow uses the default value of 4891.
You may need to restart GPT4All for the local server to become accessible.
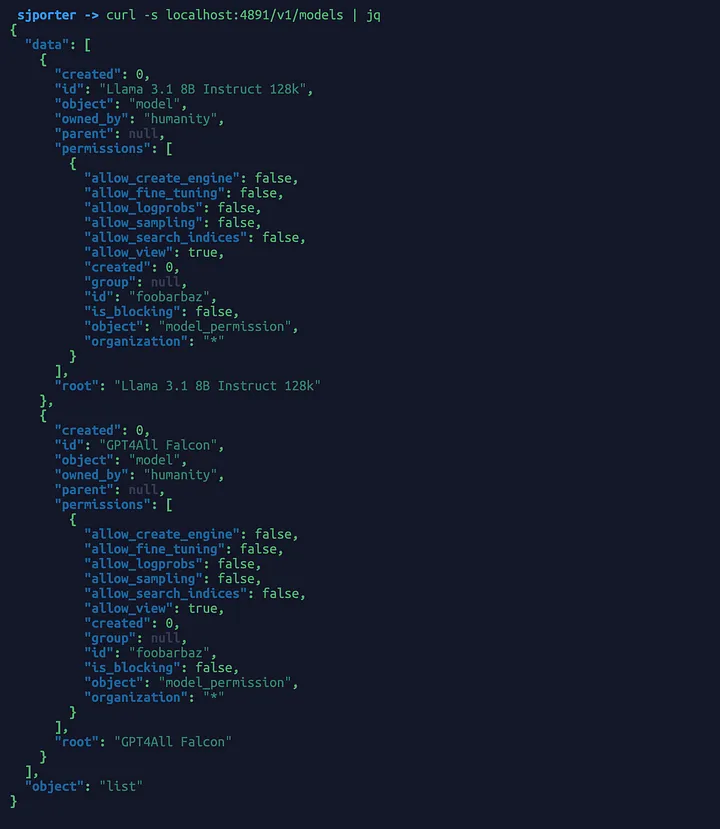
Optional Step: We can verify that our model is available on localhost by running the following command in a terminal (remember to update the port number if you’ve customized it in the GPT4All Settings tab).
## Verify which model(s) are hosted locally.
curl -s localhost:4891/v1/models
## Beautify the JSON output with jq.
## Install jq via `brew install jq` on macos.
curl -s localhost:4891/v1/models | jq
Integrating with KNIME Analytics Platform 5.3
Now that GPT4All is configured, we can begin to call models from KNIME Analytics Platform 5.3. Please start by downloading my example workflow from KNIME Hub:
In my example workflow, I provide two ways to call a local LLM and one way to call a premium OpenAI model:
- Calling a locally hosted LLM via the OpenAI LLM Connector node.
- Calling a local LLM via the Local GPT4All Chat Model Connector node and a local file path reference (/Users/sjporter/Library/Application Support/nomic.ai/GPT4All/gpt4all-falcon-newbpe-q4_0.gguf in my case). Please note, I’m simply referencing the file path that GPT4All uses for downloaded models. It may take a bit of digging to find the right path for your computer.
- Calling ChatGPT (premium, requires an OpenAI API key).
If you followed my steps exactly, your copy of the workflow should already be able to be executed for the top two examples. You can reconfigure the model connector nodes to point to custom URLs or file paths. The credentials nodes define api_key flow variables which are used for authentication (even through the local LLMs don’t require an API key, an api_key variable must be specified anyways when making requests).

Please note that in the first example, you can select which model you want to use by configuring the OpenAI LLM Connector node. As you can see below, I have selected Llama 3.1 8B Instruct 128k as my model. In the second example, the only way to “select” a model is to update the file path in the Local GPT4All Chat Model Connector node.

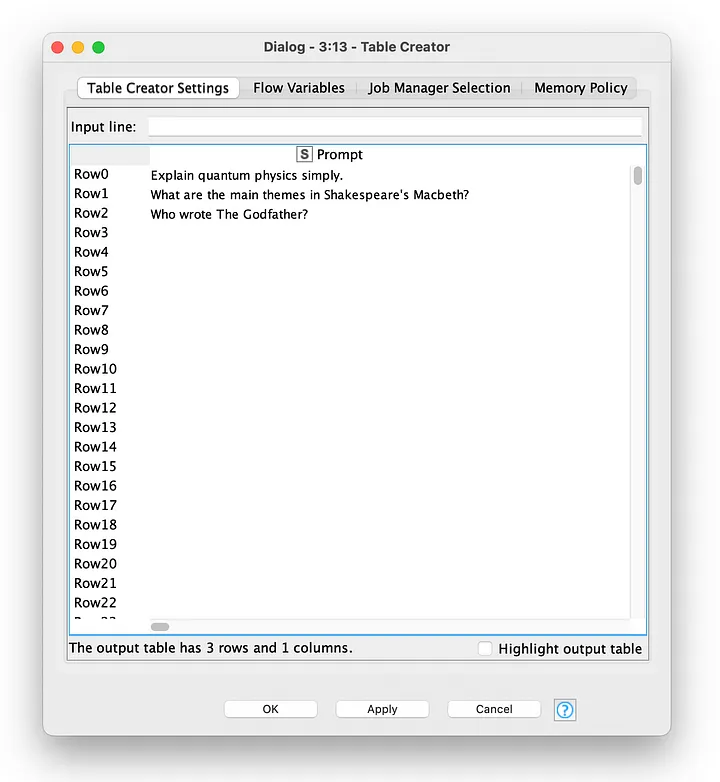
For the sake of keeping the example workflow as simple as possible, I use a Table Creator node to define my prompts. This node could/should be replaced with data coming from an external data source such as a Google Sheets spreadsheet or a SQL database.
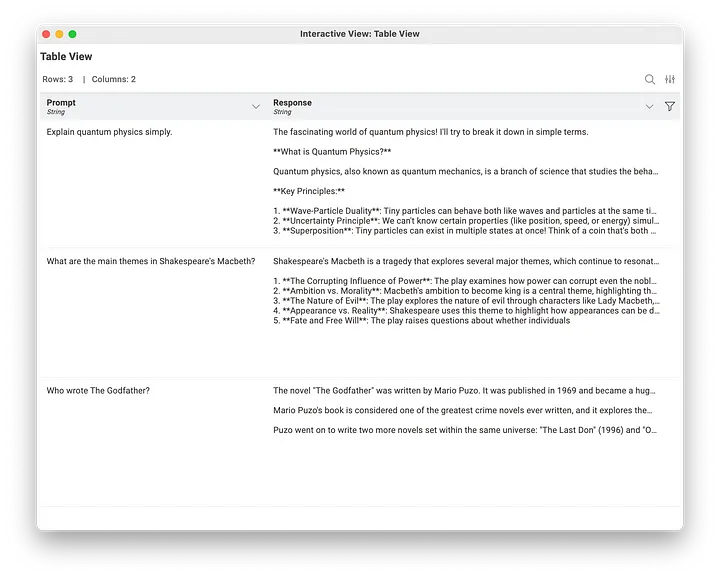
All that remains is to execute the workflow and inspect the responses. In my example workflow, I render the model responses in Table View nodes.
That’s all there is to it! Again, please check out the KNIME for Generative AI collection on KNIME Hub for more advanced examples and use cases.
Conclusion
Hosting an LLM locally and integrating with it sounds challenging, but it’s quite easy with GPT4All and KNIME Analytics Platform 5.3. I hope you found this article to be useful! See you on the KNIME Forum or perhaps at the next KNIME Summit.