
AI hallucinations occur when a Large Language Model (LLM) generates inaccurate, misleading or inconsistent responses that are not rooted in actual data or factual information. Instead, responses stem from learning errors, missing knowledge or misinterpretations of the training data.
They are currently one of LLMs’ most pressing limitations.
A 2023 study investigated the authenticity and accuracy of references in medical articles generated by ChatGPT. Findings indicated that of the 115 references generated by the model, only 7% were authentic and accurate. 47% were entirely fabricated, and 46% were authentic yet completely inaccurate.
The problem with AI hallucinations is that we can easily be fooled by them.
AI hallucinations are hard to detect because LLM output in general is designed to sound coherent, plausible, and well-argumented. An AI hallucination might also contain some accurate information, making it even easier to believe. This can be dangerous if information from the hallucination is used in critical decision-making processes (e.g., assessing risk for insurance companies, assigning or rejecting consumer loans, etc.).
It is assumed that an LLM is less likely to hallucinate if the model provider re-trains the model regularly with new data, improves the accuracy of the generated output, and provides rolling releases.
In reality, however, retraining models often is unfeasible due to exorbitant cost in terms of time, manpower and money. So at some point, training is cut off. For example, OpenAI’s ChatGPT knowledge (in the free version) was last updated with data up to January 2022.
Does this mean that we must accept LLMs’ propensity to hallucinations? Is it possible to identify strategies that mitigate this issue?
In this blog post, we will initially offer a concise perspective on the types of hallucinations LLMs are likely to exhibit. Next, we dive deep into the concept of Retrieval Augmented Generation (RAG), which is a framework to reduce AI hallucinations without having to retrain the model.
Types of AI hallucinations
Hallucinations in LLMs appear in various forms, which are easier or harder for humans to detect. We can address these limitations by categorizing and organizing hallucinations according to how challenging it is to detect them. We can use insight into the different ways LLMs diverge from the intended output to overcome their limitations.
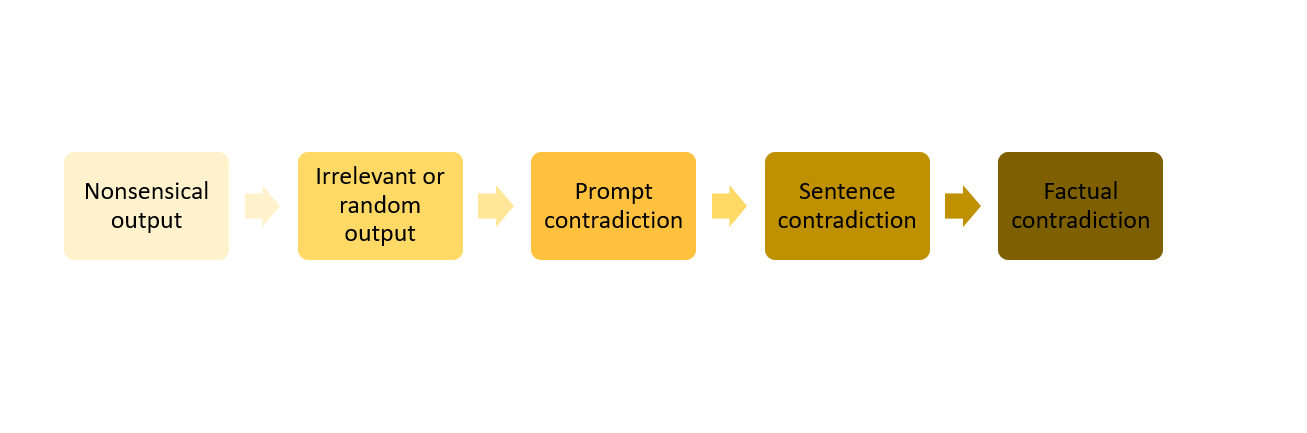
Common AI hallucination types are:
- Nonsensical output. The LLM generates responses that lack logical coherence, comprehensibility or sensical content. This type of hallucination makes the LLM useless.
- Irrelevant or random output. The LLM generates output that holds no pertinence to the input. This type of hallucination impairs the usefulness of LLM-generated text.
- Prompt contradiction. The LLM generates a response that contradicts the prompt used to generate it, raising concerns about reliability and adherence to the intended meaning or context.
- Sentence contradiction. This type of hallucination is similar to the previous one but contradicts a previous statement within the same response. This type introduces inconsistencies that undermine the overall coherence of the content.
- Factual contradiction. This type of hallucination results in the generation of fictional, inaccurate and misleading statements that are presented as factual. Factual contradictions presented as reliable information have profound implications, as they contribute to the spread of misinformation and erode the credibility of LLM-generated content.
Note that the presence of one type does not exclude the co-manifestation of other types. Similarly, the presence of a more severe type does not automatically imply the co-manifestation of less severe ones.
Mitigate AI hallucinations with Retrieval Augmented Generation (RAG)
To tackle the variety of challenges presented by all these different types of AI hallucinations, organizations can utilize different strategies to reduce the likelihood of generating inaccurate or misleading responses. One that researchers have observed to be both effective and simple to implement is Retrieval Augmented Generation.
Retrieval Augmented Generation (RAG) is an AI framework that enhances the generation of human-like responses by incorporating relevant information retrieved from a user-curated knowledge base. (e.g., data sources with specific knowledge, terminology, context, or up-to-date information).
RAG can be used to customize LLM responses for specific applications and significantly mitigate the risk of hallucinations and unfactual statements.
How does RAG work?
Suppose a user is interested in knowing who won the last soccer world cup by prompting her favorite LLM. Depending on the model’s latest knowledge update, the response may point to the lack of information for the specific inquiry or, much worse, hallucinate false or misleading statements regardless of the retraining.
To maximize the chances of LLMs providing accurate responses, the RAG process involves three critical steps.
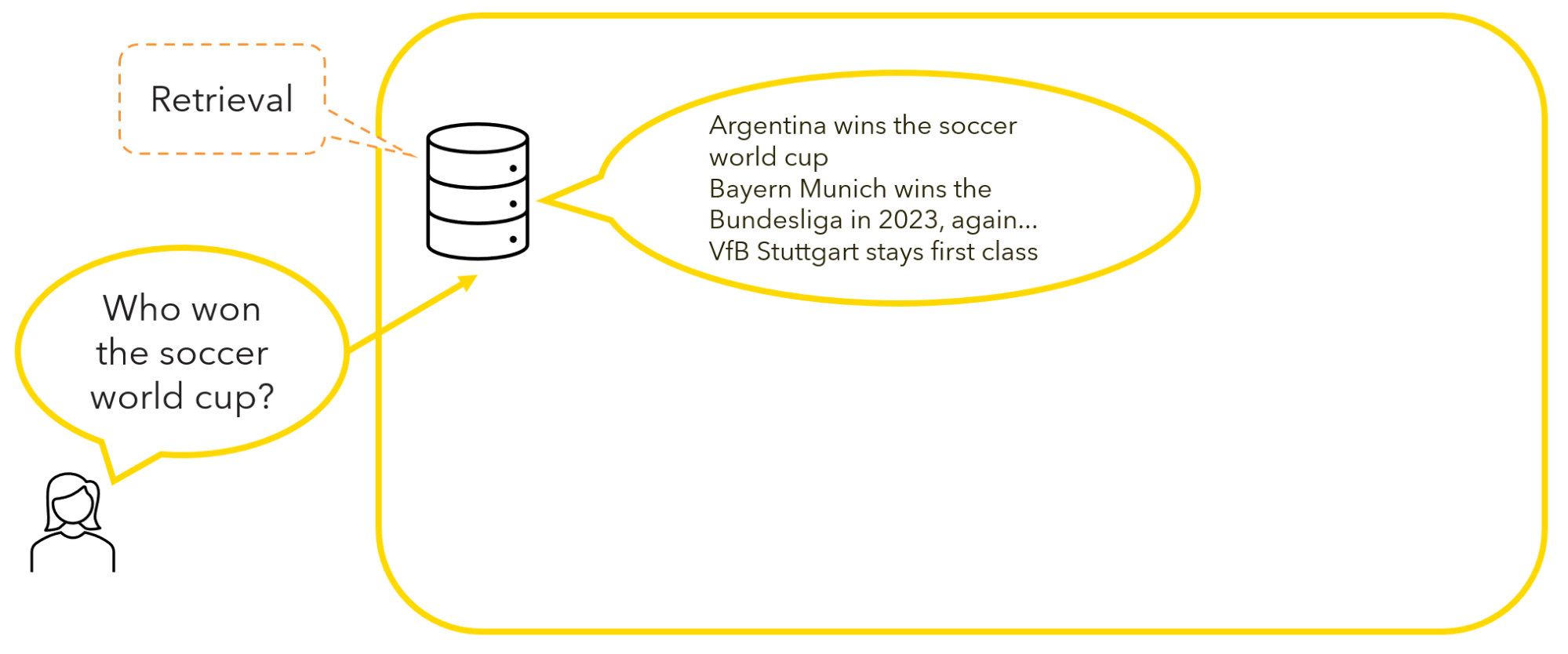
Step 1: Retrieval
This step entails the retrieval of relevant information from a knowledge source based on the user input prompt. In other words, this means querying a domain-specific database where pertinent results are returned based on their similarity (from most similar to least similar) with the input query.
For example, a user interested in knowing who won the last soccer world cup can query a knowledge base containing information about soccer teams and games, and retrieve the most similar matches.
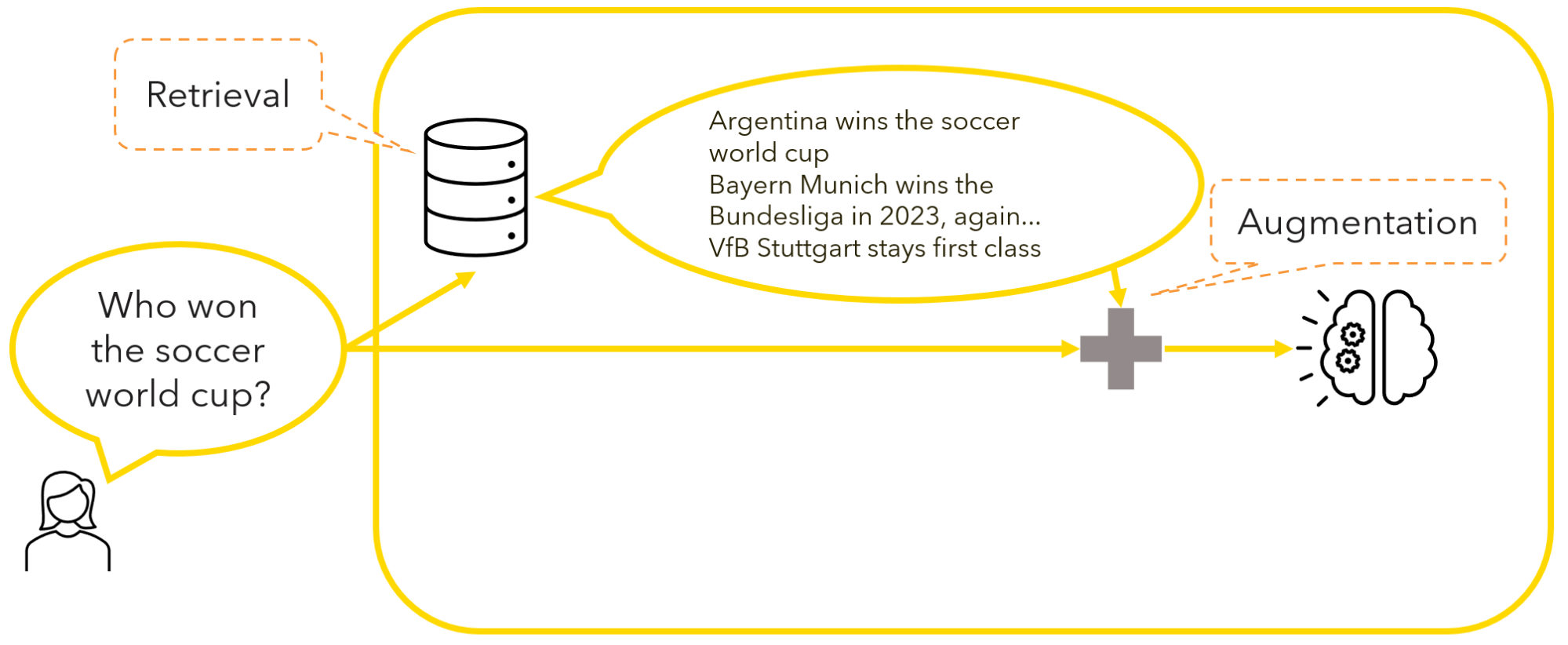
Step 2: Augmentation
Here, the input query is augmented with the retrieved information.
If we go back to the soccer example, the user’s initial query – “Who won the soccer world cup?” – is enriched with the most similar information retrieved from the knowledge base – “Argentina wins the soccer world cup” – before prompting the LLM to generate a response.
This step enhances the LLM’s understanding of the user’s request.
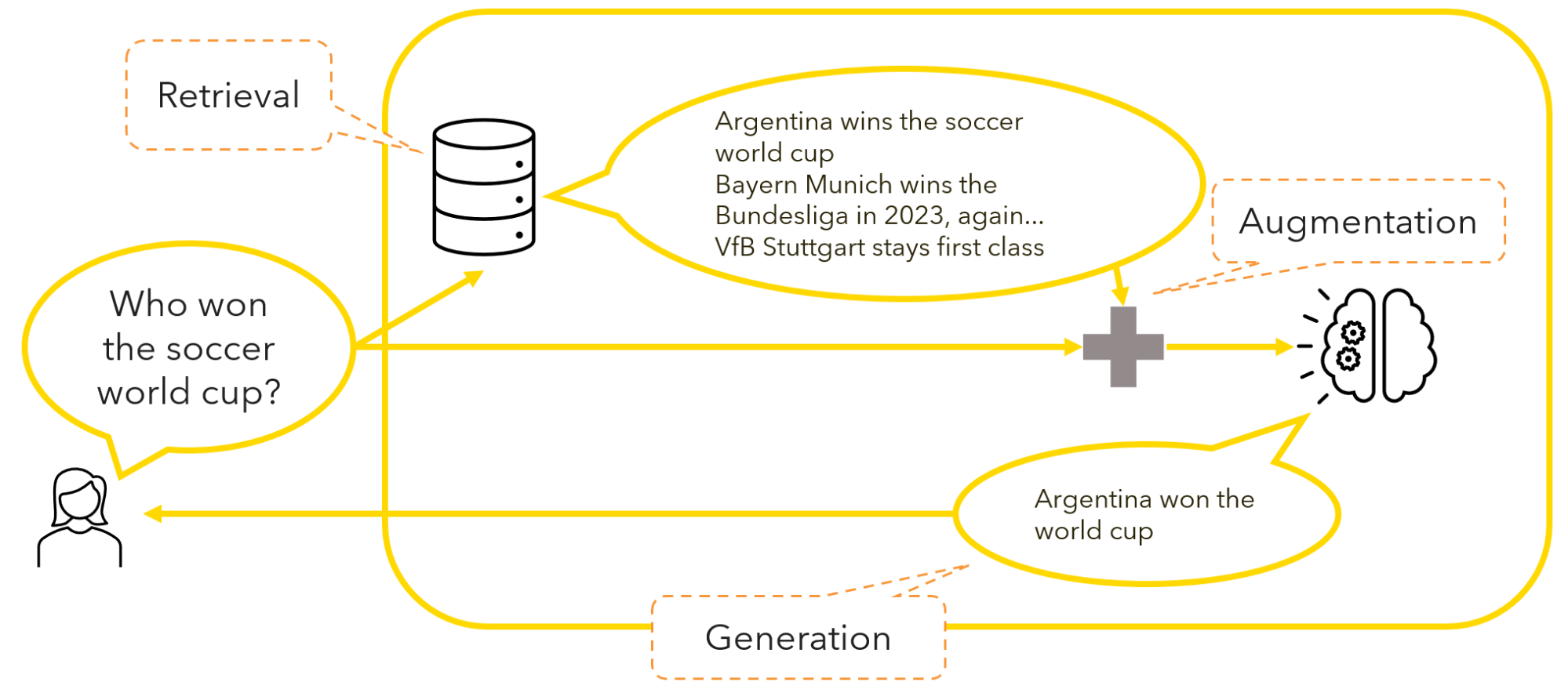
Step 3: Generation
This final step entails the generation of a more informed and contextually rich response based on the augmented input and leveraging the generative power of the model.
In the soccer example, this means that the model is prompted to generate a human-like response based on the augmented prompt.
This final step grounds the LLM-generated response in additional context from the retrieved sources, mitigating the risk of hallucinations in the output.
How to design an effective RAG-based process
We need four key components.
- User prompts: Best practices for prompt engineering maximize the likelihood of getting accurate, relevant, and coherent LLM responses.
- Knowledge base: A user-curated and domain-specific corpus of resources (e.g., dictionaries, text documents, guides, guides, code, images, videos, etc.).
- Embeddings model: A model that is designed to create a vector representation – i.e., an array of numbers – of the user prompt and the resources in the knowledge base within a continuous, high-dimensional space known as embeddings. Embeddings can effectively capture the syntactic and semantic relationships of objects and entities (e.g., words and phrases in a document). Objects that have similar meanings or are used in similar contexts will have vector representations that are closer to each other in the vector space. Because of that, embeddings can be used to identify semantic similarities between the user prompt and the resources in the knowledge base to retrieve.
- Vector Store: Unlike a conventional database, which is usually organized in rows and columns, a vector database specializes in storing and managing objects as vector representations in a multidimensional space. The structure of these stores allows for quick and effective lookup of vectors associated with specific objects, facilitating their retrieval.
With these four components in our pocket, let’s look at how they interact.
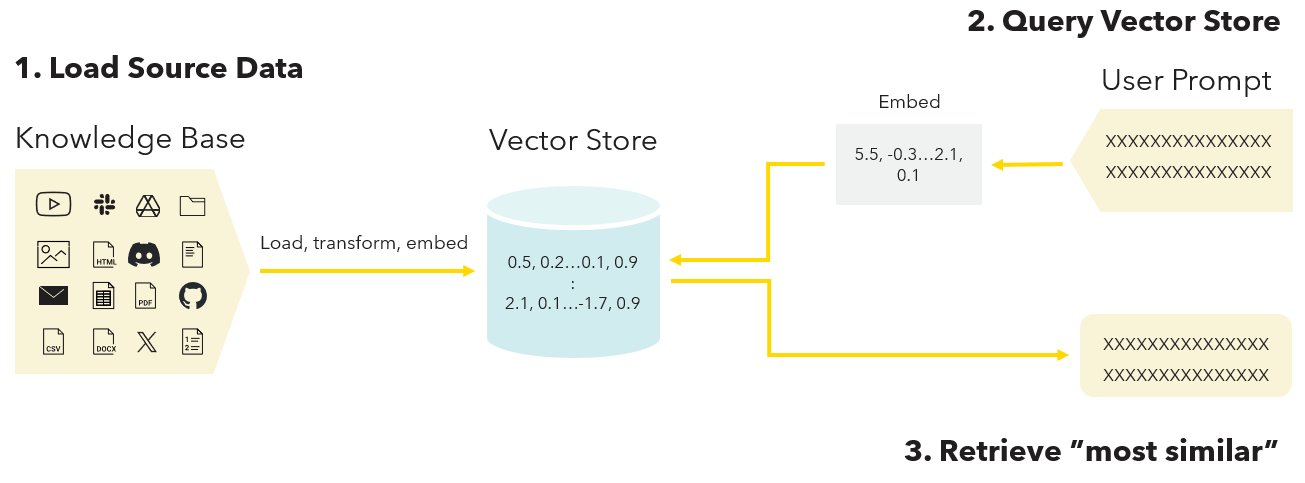
- Load the source data. This step starts off by importing, transforming, cleaning and manipulating a user-curated and domain-specific knowledge base. Next, embeddings of the resources in the knowledge base are created and loaded in a vector store (e.g., Chroma or FAISS).
- Query the vector store. The user queries the vector store via a prompt. For the query to be effectively processed, a vector representation of it is needed.
- Retrieve “most similar”. Leveraging the embeddings of both the resources in the knowledge base and the user prompt, relationships and similarities between objects are identified. Finally, the vector store retrieves the resource(s) that is most similar to the user's request in the prompt.
Use RAG with guardrails
We’ve navigated the complex landscape of mitigating hallucinations in LLM responses and suggested using a RAG-based AI framework as an effective strategy to tackle this issue.
It’s important to bear in mind that this strategy is not without potential caveats. One that stands out is the risk of over-reliance on retrieved information.
The retrieval stage of RAG might return results that are either empty or require further disambiguation, despite the user’s best effort to create a curated knowledge base. This could lead the LLM to generate a response that is no longer grounded in facts but rather to hallucinate an answer for the sake of completion.
In scenarios where void or ambiguous results are returned, a possible solution might involve instructing the model via prompt engineering to opt for caution and explicitly state the lack of relevant data in the knowledge base or unclear query formulation by the user.
The pitfall of over-reliance can be further extended to the scenario where LLMs hallucinate because of incorrect retrieval results. This case is particularly challenging to address because incorrect retrieval results are difficult to identify without an external ground truth.
One inexpensive solution involves designing the user-prompt to be extra precise or cautious in the areas the retrieval engine has displayed more weaknesses.
It can also be worth expanding the knowledge base with more fine-grained resources in the hope for higher accuracy.
A more expensive solution involves annotating retrieval data, where for a given query-document pair, an annotator must determine whether or not the document is relevant to the query. With annotated retrieval data it is possible to craft quantitative metrics to evaluate the goodness of the retriever and take targeted action.
Responsible AI practices to ensure reliability in LLM responses
As ever-more effective frameworks against hallucinations continue to surface, we must maintain a vigilant eye on potential pitfalls and embrace responsible AI practices. The quest for linguistic precision and factual reliability in LLM responses is an ongoing journey.