
In sports, where real-time decisions and precision are critical, the ability to analyze images through object detection and tracking can be a game-changer.
For example, imagine instantly determining the winner in a cycling race or tracking the ball movement in a soccer match—all with the help of AI and visual workflows. These capabilities enable faster decision-making, reduce human error, and deliver detailed performance insights that go beyond the limits of human observation.
In this blog post, we’ll explain how to:
- Use pre-trained vision models to analyze and process visual data efficiently.
- Dive into two specific use cases using KNIME workflows:
- Object detection in cycling: Identify the lead cyclist in a race.
- Object tracking in soccer: Track the ball's movement across video frames.
KNIME Analytics Platform is an open-source, low-code software for data science It enables image processing and integration with Hugging Face’s open-source, pre-trained vision models via REST API requests.
Let’s get started!

Object tracking was performed using KNIME Analytics Platform
Why are pre-trained models useful for computer vision?
Image and video data are heavy and resource-intensive. This means they require significant storage and computational processing power. Training deep learning models from scratch for computer vision applications is often costly and time-consuming. Pre-trained models address this challenge by leveraging knowledge already acquired from extensive training on large image datasets. This approach is known as Transfer Learning. It allows practitioners to adapt these models to similar tasks with minimal fine-tuning. The result is a significant reduction in development costs and streamlines the implementation of new applications.
For our sports analytics use cases, we will use Facebook’s DETR (DEtection TRansformer), an open source, pre-trained vision model. DETR combines an encoder-decoder Transformer architecture with a convolutional neural network (CNN) and a ResNet-50 backbone, providing a robust foundation for identifying and localizing objects within images.
DETR stands out from traditional object detection models by treating object detection as an image-to-set problem. Given an input image, the model predicts an unordered list of all the objects present in the image, each represented by its label, along with bounding box coordinates around each object.
To do that, DETR’s architecture relies on a:
- CNN to extract the local information from the image
- Transformer encoder-decoder to analyze the image comprehensively, enabling global reasoning about the image as a whole, and generate precise predictions.
We’ll source DETR from Hugging Face, a platform that provides a wide range of open source, pre-trained models. These models can be used directly for inference or fine-tuned with our own data.
A convenient way to access these models is via Hugging Face’s Inference API. It allows us to send requests and receive results, without the need of a local infrastructure to run the model. With KNIME, we only need to specify the desired model in the POST Request node and adjust the preprocessing and postprocessing steps based on our task requirements.
Use case 1: Object detection for cycling
In this workflow, we demonstrate how to use a pretrained object detection model within KNIME to analyze a single image from a cycling race. The goal is to detect the position of each cyclist by drawing a bounding box around them and assigning a label (e.g., person or bicycle).
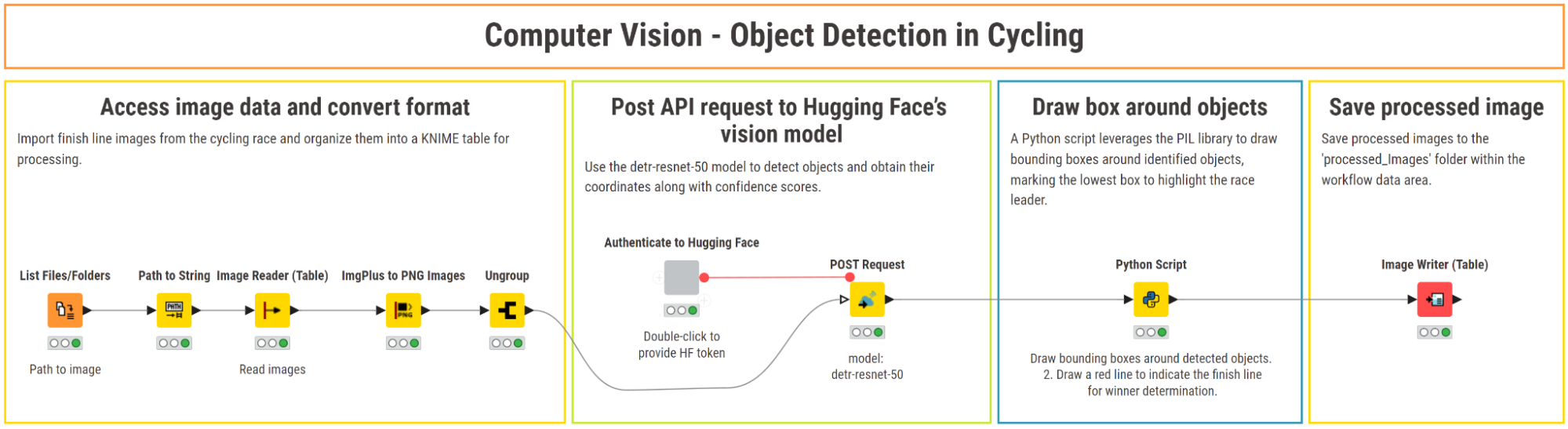
1. Access image data and convert format
We begin by using the List Files/Folders node to import the path of the image that we want to analyze. Next, we use the Image Reader (Table) to load the image into KNIME as ImgPlus format. This node also gives us a preview of the image.
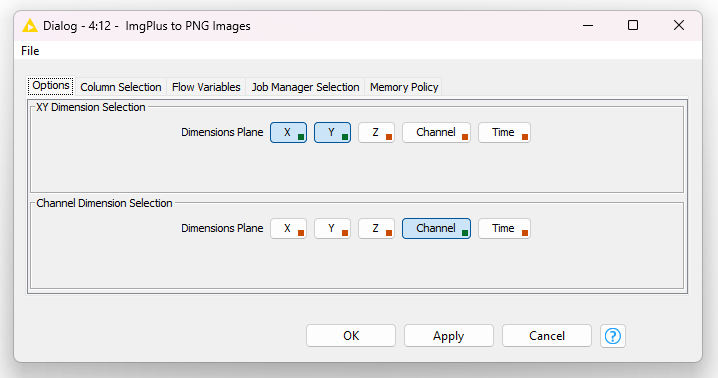
For our use case, the image needs to be in a widely supported format like PNG. To perform this conversion, we use the ImgPlus to PNG Images node. In the configuration window, we keep the default settings:
- X and Y as the image dimensions
- “Channel” as channel dimension.
The node outputs the converted image in a list. We then use the Ungroup node to extract converted images from the list.
2. Post API request to Hugging Face’s vision model
To interact with the DETR model via the Inference API, we first need to authenticate to Hugging Face. For that, we need a Hugging Face’s access token, which we can generate for free from our account settings.
Next, we can input the access token in the “Authenticate to Hugging Face” component. Inside, this component contains the String Configuration node to collect the token, and the String Manipulation (Variable) node, which adds the “Bearer” prefix (e.g., Bearer <your_hf_token_here>) to create the necessary authorization format for the token.
Once the authentication is set, we can send requests to the DETR model via the POST Request. This node requires:
- The API URL of the model: https://api-inference.huggingface.co/models/facebook/detr-resnet-50.
You can find it by clicking on “Deploy > Inference API (serverless)” on the model’s card on Hugging Face.
- A timeout value for processing each request. For image data, this value should be set rather high (e.g., 150 seconds).
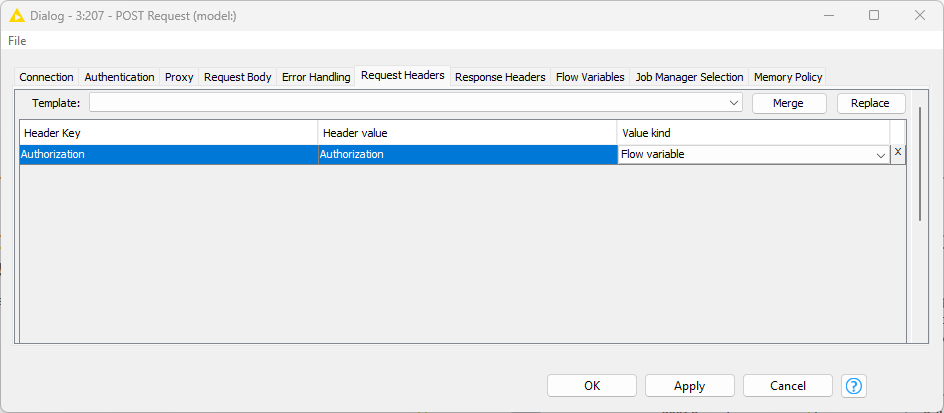
- The access token for authentication passed as a flow variable in the “Request Headers” tab.
Once the node executes successfully, it outputs a response in JSON format that includes a label for each detected object, a confidence score, and coordinates of the detected object on the image.
3. Draw bounding boxes around detected objects
We use the Python Script node to process the results of the REST API and draw bounding boxes. The script parses the JSON output to extract the labels of the detected objects and their respective coordinates. Then, it draws bounding boxes around the identified objects, using different colors to represent specific labels such as "bicycle" or "person".
Additionally, it highlights the object positioned furthest downward in the image by drawing a red horizontal line. This line indicates the first racer in the cycling race. Finally, the modified image is then outputted in PNG format.

4. Save processed image
We use the Image Writer (Table) node to store the edited image in a designated folder within the workflow data area.
Use case 2: Object tracking for soccer
In this workflow, we demonstrate how to apply object detection techniques to track a ball across multiple video frames of a soccer game. Specifically, we analyze the frames showing Cristiano Ronaldo’s iconic bicycle kick goal for Real Madrid during a match against Juventus. By processing the sequence of frames, we can pinpoint the ball's position and visualize its trajectory.
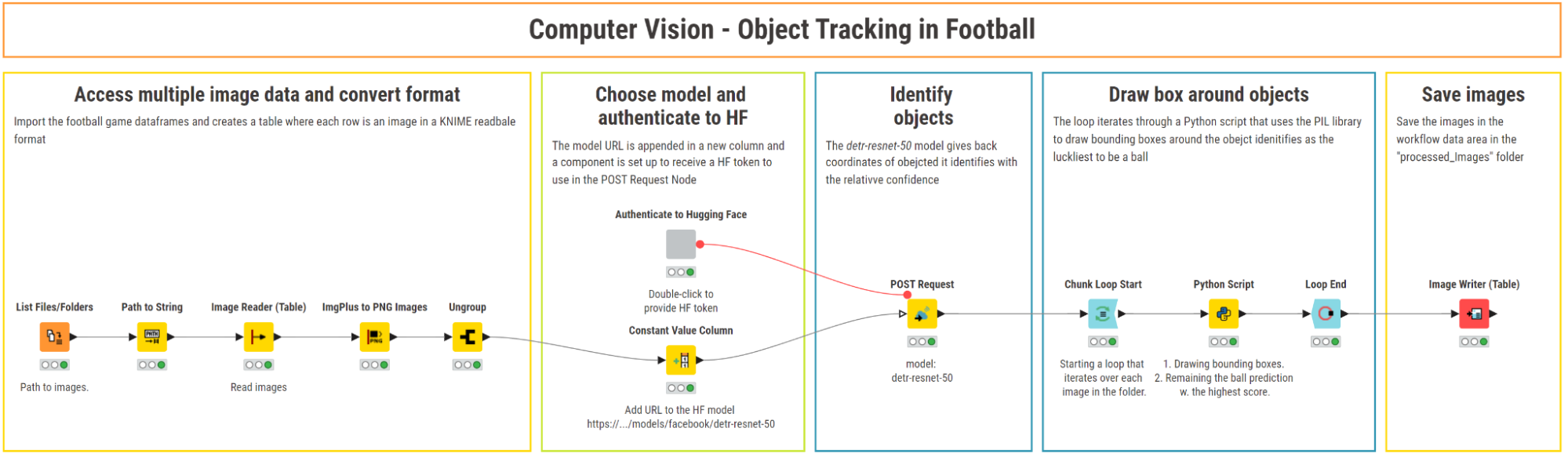
1. Access multiple image data and convert format
Object detection and object tracking are very similar tasks. Therefore, the steps for accessing image data and converting the format to PNG rely on the same nodes and configurations as in the cycling use case.
The key difference here is that we’re working with video frames instead of a single image. Instead of loading one image, we process a folder containing multiple images representing the frames of a soccer video.
2. Post API requests to Hugging Face’s vision model
To access the DETR model, we re-use the “Authenticate to Hugging Face” component described in the first use case.
In a parallel workflow branch, we use the Constant Value Column node to append the model’s API URL as a new column, allowing the POST Request node to reference it row-wise for each frame.
In the configuration of the POST Request node, we provide the model API URL as a column, pass the access token in the request header and set the timeout to 150 seconds. For each frame, the node outputs a JSON response with the labels of each detected object (e.g., “person”, “sport ball”), confidence scores, and object coordinates on the image.
3. Draw bounding boxes around detected objects
Since we are processing multiple frames, we initiate a row-wise loop with the Chunk Loop Start node and draw bounding boxes around each detected object using a Python Script node.
In the Python Script node, we parse the JSON response, extract object labels and their coordinates, and draw bounding boxes around them. To facilitate the visual tracking, we customize the appearance of the boxes to be red with a thicker border around the sport ball, and white with thinner borders around the players.
We then use the Loop End node to end the loop and collect results.

4. Save processed frames and display in motion
We use the Image Writer (Table) node to save the processed frames in a folder within the workflow data area.
Finally, to visualize the tracking in motion, we can use a free GIF tool (e.g., Ezgif, Giphy, etc.). These tools allow us to combine the frames into an animated sequence, showcasing how the ball and the player are tracked across multiple frames.

A GIF displays the tracking of the ball and players.
Sports insights with vision models, the visual way
A significant portion of sports data is in visual formats and to make sense of it, we need highly capable vision models. In this blog post, we explored how KNIME can leverage Hugging Face’s open-source, pre-trained vision models to enhance sports analytics. We demonstrated how to connect KNIME to these models and integrate Python, creating a robust pipeline to handle common computer vision tasks in sports analytics.
KNIME's ability to integrate with various data sources, tools, and programming languages is particularly valuable in sports analytics. By combining diverse data types, such as visual data from images and traditional numerical data, KNIME enables deeper insights and more effective decision-making.