
Business analytics and data science are gaining popularity due to several key factors.
First, there is a growing need to make quick and informed decisions in a highly competitive global market.
Second, the availability and affordability of data have increased with advancements in technology, such as big data and related tools for data capture, storage and retrieval as well as hardware platforms and software/algorithms. These advancements enable organizations to leverage large and complex data sets for analysis.
Third, the adoption of standardized methodologies, known as standard processes, has helped transform analytics and data science from subjective art forms into structured scientific practices. This has allowed for the replication of best practices and increased effectiveness as well as efficiency.
Finally, there has been a cultural shift in organizations moving away from traditional experience-based decision-making toward evidence- and data-driven decision-making [1].
As the demand for analytics and data science professionals has grown, the terminology, roles and job titles associated with these fields have also expanded. Initially, the term “data scientist” encompassed individuals with broad skills, capable of handling all aspects of analytics projects, from problem identification to model deployment.
However, it became apparent that this definition was too broad, and very few individuals could fulfill all the requirements (akin to unicorns). Consequently, the concept of a data scientist evolved into a team-based approach, with individuals possessing complementary skills and experiences.
This shift led to the emergence of various personas and job titles associated with specific tasks within analytics and data science processes. Although the following list is not exhaustive, it provides definitions for some prominent personas.
What is a business analyst?
Business analysts possess extensive business/domain experience and excel at identifying problems, opportunities and continuous improvement initiatives. They primarily focus on management and may not possess strong technical/programming skills. They usually rely on others for analytics tasks. Intuitive, no-code/low-code analytics platforms can greatly help these individuals excel in the workplace as citizen data scientists.
What is a data analyst?
The role of a data analyst or business intelligence analyst has been around for nearly three decades, originating from the business intelligence and data warehousing field. Their responsibilities typically involve utilizing structured query language (SQL) to extract data from transactional and data repositories/warehouses, generating standard or ad hoc reports and creating dashboard-like information portals for managers. They rely on tools such as Excel and other data visualization/reporting tools.
They primarily operate within the descriptive analytics phase of the analytics process.
What is a data engineer?
A data engineer, data wrangler, and data architect are referred to as the “people of data” or even “data whisperers,” these individuals specialize in acquiring and preparing data. Data wranglers locate relevant data sources, often from the internet, and retrieve, standardize and store it. Data engineers handle large volumes of diverse data repositories, employing engineering design and experimentation skills to combine and prepare the data for analytics and data science projects. Data architects design the infrastructure for acquiring, storing and retrieving various types of data.
They contribute to both the descriptive analytics and predictive analytics phases as enablers/supporters rather than key knowledge creators.
What is a data scientist?
A data scientist or machine learning engineer were traditionally the experts considered capable of handling all aspects of business analytics and data science. Their skill set encompassed the roles mentioned previously.
Now, however, data scientists are known for their advanced machine learning and knowledge discovery skills, making them well suited for the predictive analytics phase.
What is an operations research (O.R.) analyst?
Operations research analysts are proficient in utilizing information and alternative solutions produced by the descriptive and predictive analytics phases to derive optimal decisions for pressing problems. Although the popularity of this role is relatively new in the analytics continuum as an enabler of prescriptive analytics, the methods and techniques employed by operations research analysts date back to the 1940s, when optimal use of constrained resources was crucial.
Operations research analysts employ optimization, simulation and multicriteria decision modeling techniques, fitting seamlessly into the prescriptive analytics phase.
Additional job titles/roles in analytics and data science include:
Functional areas or specializations within the organization
- Operations analyst
- Marketing analyst
- Logistics analyst
- Product/design analyst
- Customer analyst
- Supplier analyst
- Decision analysts (for strategic decision support)
Managerial and administrative supporting roles
- IT systems analyst/database administrator
- Data analytics consultant/data analytics manager
- Analytics project manager
- MLOps Engineer
Other job titles/roles in analytics and data science
- Professors/educators
- Students/programmers
- Research scientists
How to conduct analytics projects? Develop a standardized analytics process
As has been the case in many other computational paradigms, extracting knowledge from large and varied data repositories began as trial-and-error experimental processes. Many practitioners approached the problem from the perspective of characterizing what works and what doesn’t. For quite some time, data mining (or more recently, data analytics and data science) projects were carried out as artistic, ad hoc, experimental endeavors.
However, to methodically conduct analytics projects, a standardized process needed to be developed.
Based on best practices, in the early days, data mining researchers in academia and industry proposed several processes as simple step-by-step methodologies to standardize and streamline data analytics projects. These efforts have led to several standardized processes, including (Knowledge Discovery in Databases), SEMMA (Sample, Explore, Modify, Model and Assess), DMAIC (Define, Measure, Analyze, Improve and Control) of Six Sigma and CRISP-DM (Cross-Industry Standard Process for Data Mining).
Among these standard processes, the one that has been dominating the practice is CRISP-DM [2].
CRISP-DM is a widely used and well-established methodology for conducting data analytics projects. It provides a structured approach using a six-step iterative process [3], as shown below.
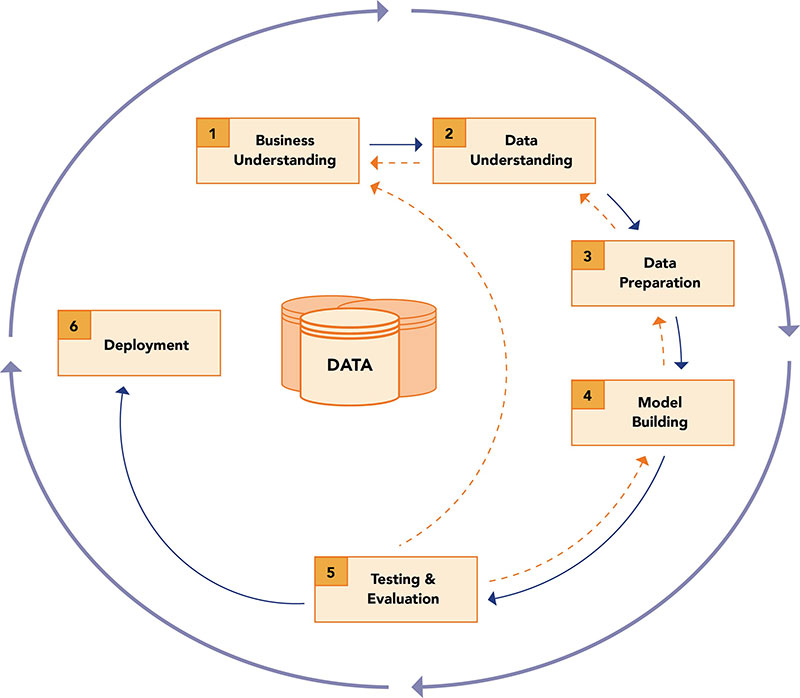
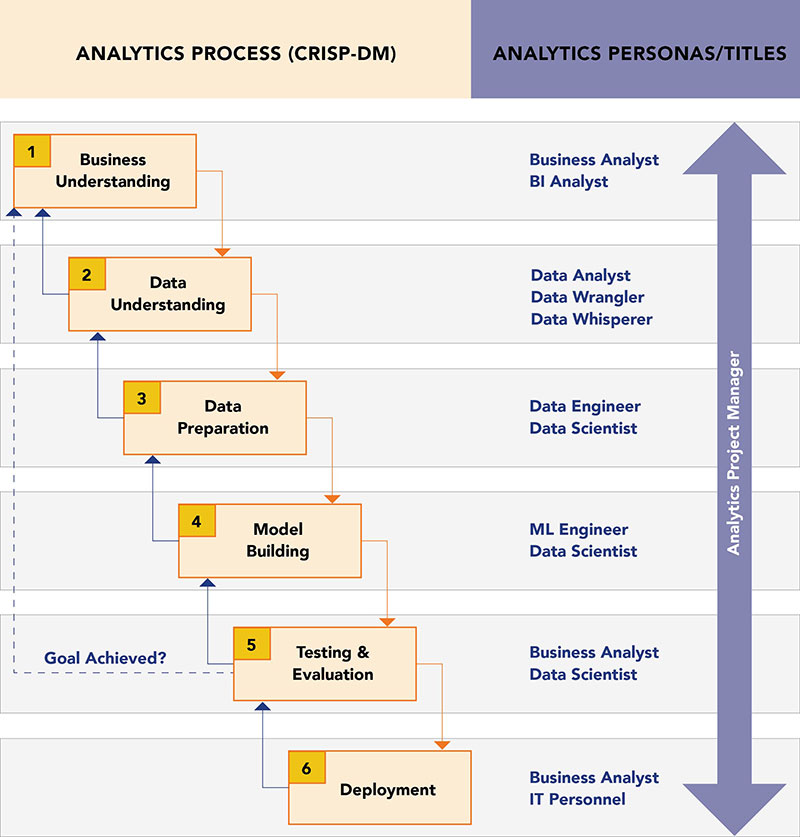
Connecting analytics & data science personas to the CRISP-DM process
Business analytics and data science projects are complex undertakings that necessitate the use of established, standardized and methodologies. The steps and phases in these methodologies are executed by individuals with specific skills, known as analytics personas.
Below, we attempt to illustrate the mapping of the personas in analytics and data science to the CRISP-DM process steps as follows:
Business analysts are crucial during the business understanding phase
Business analysts play a crucial role in the “business understanding” phase of CRISP-DM. They are responsible for identifying business problems and opportunities, defining project goals and establishing success criteria. Their domain expertise and understanding of the business context guide the entire data mining process. They also play a supporting role in evaluation and deployment phases to ensure proper assessment and utilization of the outcomes.
Business intelligence analysts/data analysts extract and analyze data to gain insight and develop reports
The Business Intelligence Analysts and Data Analysts are also closely involved in the “business understanding” phases of CRISP-DM. Focusing on descriptive analytics in which the goal is to define what happened, they extract and analyze data descriptively from various sources, including transactional and data warehouse repositories, to gain insights and develop reports and dashboards based on key performance indicators (KPIs) and scorecards.
Data engineers/data wranglers/data architects are key to data understanding and data preparation
The Data wranglers/data engineers/data architects contribute greatly to the “data understanding” and “data preparation” phases of CRISP-DM. They play a critical role in acquiring, cleaning, integrating and structuring the data for analysis. Data engineers and data architects design the infrastructure and processes for data acquisition, storage and retrieval, ensuring that data is ready and accessible for modeling.
Data scientists/machine learning engineers are pivotal for model building and evaluation
The data scientists/machine learning engineers are involved in multiple phases of the CRISP-DM process, and their main contribution is during the model building and evaluation phases. Data scientists and machine learning engineers apply advanced analytical techniques, develop models and assess their performance against defined objectives. O.R. analysts contribute to the evaluation and deployment phases, utilizing optimization, simulation and decision modeling techniques to support the decision-making process.
Other analytics & data science roles support and coordinate data analytics projects to ensure successful execution
Other Roles: Various other personas, such as functional department analysts, IT systems analysts/professionals, database administrators and analytics project managers, can be connected to different phases of CRISP-DM depending on the analytics project’s specific requirements. They provide support and coordination throughout the data analytics project, ensuring successful execution of the methodology.
Overall, the personas in analytics and data science align with different stages of the CRISP-DM process, working collaboratively to identify and address business needs and objectives by understanding the data, preparing it for analysis, developing various models, evaluating their performance and deploying the results in a real-world context.
Coordination and collaboration of multiple professionals is vital for successful data science projects
It is evident that successful execution of analytics and data science projects relies heavily on the coordination and collaboration of multiple professionals encompassing various data science personas.
How to obtain data analytics and data science skills
There are two main learning paths: programming languages (e.g., Python and R) and visual modeling/programming tools (e.g., IBM Modeler, SAS Enterprise Miner, KNIME, Weka, Orange, etc.).
Learning paths are easier and shorter if they are free of syntactic details of coding and debugging, allowing the analyst to spend more time and focused effort on considering the foundational concepts and applying best practices. Visual modeling tools (e.g., KNIME Analytics Platform) allow this to happen [4].
Obtaining the skills necessary for the personas in analytics and data science typically involves a combination of formal education, practical experience and continuous learning.
Common learning paths for data science upskilling
- Academic education: Many professionals acquire foundational knowledge through specialized certificate programs or, more substantially, from undergraduate or graduate (master’s or doctorate) degree programs in fields such as business analytics, data science, data analytics, applied artificial intelligence, computer science, industrial engineering, statistics, mathematics or other related disciplines. These programs provide a theoretical understanding of key concepts, algorithms and analytical techniques.
- Online courses and MOOCs: Numerous online platforms offer courses and massive open online courses (MOOCs) focused specifically on analytics and data science. These courses cover a wide range of topics and cater to different skill levels, allowing individuals to learn at their own pace.
- Bootcamps and training programs: Bootcamps and intensive training programs provide immersive, hands-on learning experiences. They often focus on practical skills and real-world projects, allowing participants to develop expertise in a shorter time frame.
- Self-study and practice: Many professionals acquire skills through self-study, utilizing online resources, books, tutorials and practice exercises. They explore programming languages, data manipulation tools, visual modeling platforms, statistical techniques and machine learning algorithms on their own. It is a great idea to join some of the data science competitions at online platforms such as Kaggle to gauge your skills against others in the field.
- Industry experience and on-the-job learning: Practical experience working on analytics and data science projects is invaluable for skill development. Individuals learn through real-world applications, collaborating with colleagues and tackling complex challenges encountered in their professional roles.
Expedite data science learning and skill building with visual modeling and programming
To expedite learning and skill building, visual modeling and programming can help. They provide a visual framework for understanding the flow of processes and relationships between different elements. Visual programming environments that employ drag-and-drop functionality with graphical user interfaces make it easier for individuals to build and manipulate models without needing to write extensive lines of code. Therefore, as opposed to spending ample time on figuring out the syntactic details of the code, one can spend that time understanding the foundational concepts and best practices of analytics and data science modeling. This simplification can greatly accelerate the learning process and allow analysts to quickly prototype and experiment.
Visual modeling tools can also facilitate easy collaboration among team members by providing a visual representation of ideas, data flows and algorithms. This improves communication, enabling team members to understand and contribute to the project more effectively. These tools often provide capabilities for rapid prototyping and iteration, allowing individuals and teams to visualize and quickly refine and optimize their models. This iterative process accelerates team-based learning, experimentation and optimization of models to meet and exceed the expectation of the analytics projects.
In summary, learning paths for analytics and data science skills involve a combination of academic education, online courses, practical experience, self-study and on-the-job learning. Visual modeling and programming tools such as KNIME Analytics Platform can enhance learning (of the fundamental concepts and best practices) and skill development by providing intuitive and collaborative environments for better internalization, experimentation, prototyping and communication of complex concepts, processes and end results.
This is a revised version of the original article, published in ORMS Today
Explore learning paths for data scientists, data analysts, and data engineers in the KNIME Learning Center.
References
[1] Delen, D., 2020, “Predictive Analytics: Data Mining, Machine Learning and Data Science for Practitioners,” Upper Saddle River, NJ: FT Press.
[2] Delen, D., 2018, “Data analytics process: An application case on predicting student attrition,” Analytics and Knowledge Management, Boca Raton, FL: Auerbach Publications, pp. 31-65.
[3] Sharda, R., Delen, D. & Turban, E., 2023, “Business Intelligence, Analytics, Data Science, and AI,” 5th edition, London: Pearson.
[4] Delen, D., 2021, “KNIME ANALYTICS PLATFORM - Open-source business analytics and data science tool provides comprehensive capabilities in the classroom,” OR/MS Today, Vol. 48, No. 5, pp. 22-23.