
I guess most of you have heard about web services and many of you will have already used one or more of them. To date there are two main types of web services, SOAP-based and RESTful web services. The KNIME Server has been offering a slim SOAP interface for quite some time but in this blog post I'm going to talk about the new REST interface which will be part of KNIME Server 4.1 in July.
REST
The main reason why RESTful web services are becoming more and more popular is because they are simple to use (compared to SOAP services), and this is due to a number of the criteria that a true RESTful web service has to fulfill (aka Richardson Maturity Model):
- Use HTTP as transfer protocol
- Use resources as endpoints of requests
- Use the standard HTTP verbs for operations on resources
- Use hypermedia to control clients, aka HATEOAS (Hypertext As The Engine Of Application State)
I'm not going to go into detail on all of these points as there are numerous pages and (sometimes even religious) discussions on the web that elaborate on principles of RESTful web services. Instead I want to show you how these criteria are implemented in the REST interface of the new KNIME Server.
HTTP as transfer protocol
This is the easiest criterion and probably also the most important when it comes to deploying web services. HTTP is one of the protocols most used on the internet. As a result the whole network infrastructure knows how to deal with it. This is especially important in corporate setups where firewalls and/or proxies may prevent communication over uncommon protocols, such as the ORB/CORBA protocol used by Glassfish in the 3.x KNIME Server series. KNIME Server 4.x is based entirely on HTTP.
Use resources as endpoints
So what does this mean? If you are used to object-oriented programming you will immediately feel familiar with it as ‘resource’ and ‘object’ are the same in my opinion. Therefore, when you talk to the KNIME Server you are always talking to a certain resource or object and send commands to it (like method calls on an object). Consequently if you wanted to access the workflow repository on the server you'd send a command to http://localhost:8080/com.knime.enterprise.server/rest/v4/repository/. This will give you a list of elements in the repository root (more on the format in a moment). Or if you want to do something with a workflow, you would talk to http://localhost:8080/com.knime.enterprise.server/rest/v4/repository/Group1/Workflow. The resource is uniquely identified by the URL to which you are sending the request (this is different to SOAP services where there is a single URL and everything else in encoded in the message).
Use standard HTTP verbs
Now this gets a bit more technical. HTTP defines a set of "operations" that you can request from a resource, all with pretty well-defined semantics. The most common operation or HTTP verb is GET which returns you the content of the resource to which the URL points (a web page, an image, ..., or the representation of a REST resource). GET is a safe operation which means you can call it as many times as you want and it won't change the resource at all. Thus in order to retrieve the contents of the repository you'd issue a GET http://localhost:8080/com.knime.enterprise.server/rest/v4/repository/. If you type a URL into your browser it will make a GET request, making it very easy to implement such calls by hand. Another HTTP method is POST which is used for sending data from the client to the server (e.g. in web forms). In RESTful web services POST calls are used to either modify existing resources or create new resources. In order to create a new job for a workflow we will perform a POST request to the collection of jobs of a workflow: POST http://localhost:8080/com.knime.enterprise.server/rest/v4/repository/Workflow:jobs (don't get confused about the ":" in the URL, the format of URLs is not important at all as we will see in the next section). This will load the workflow into memory, create a new job, and return you some information about the newly created job resource. POST is a so-called unsafe and non-idempotent operation because it usually changes resources and each call may have different side-effects (such as creating another job every time). There are more HTTP methods such as DELETE for deleting resources (we will see an example later on) or PUT for changing the state of a resource (e.g. name, permission, etc.).
One nice thing about using HTTP to control operations is that many network components also know the semantics of the HTTP methods and may perform certain optimizations such as caching contents (e.g. the results of GET request can usually be cached, but not for POST requests).
Use hypermedia!
This last hurdle on the way to REST heaven is the most debated, most misinterpreted, and most complicated. All of you know hypermedia, you use it every day: every web page is a hypermedia because it contains links to other resources. Your browsing is controlled by these links, nobody types in URLs (except for entry points to web pages). Therefore the hypermedia controls your browsing through a web page. The only thing that you need to know is the meaning of a hyperlink (what the resource that it points to is about). This concept works exceptionally well for humans so one would expect that it works for computers, too.
What does it mean for our KNIME Server REST interface? First of all, except for the entry point, the so-called billboard, the client does not need to know any other URL. Second, all resources and operations on resources are described by links in the responses that are sent by the server. These links have a URL (whose structure doesn't matter at all) and a semantic descriptor that tells the client what they link to or what operation is triggered by e.g. POSTing to the URL. There are two nice things about this: we can change the URLs for resources at any time and proper clients should still work (because they follow the - changed - links that we send) and the client immediately knows which operations for a resource are possible or allowed. So for example, if the above-mentioned jobs collection for a workflow does not contain a link for creating a new job then the user probably doesn't have permissions or server-side execution is disabled. There is no need for the client to check this explicitly, the mere presence or absence of a link gives you this information.
One of the implementation challenges is to choose the "right" hypermedia-aware data format that is sent between client and server. The most popular general purpose data formats these days are XML and JSON. They are widely used, there are lots of libraries out there for processing them, and both are human-readable (which makes debugging easier). However, none of them are hypermedia formats because they don't have the notion of a "link" (HTML for example does with <a>, <img>, or <form>). Therefore there are various extensions (or specializations) of XML and JSON that define a structure with a link concept. After many hours (more like days...) of research we finally settled forr Mason, which is a JSON-based hypermedia format (we are using the Draft 2 version). The nice thing about Mason is that you don't need to change the application data format you simply add a few more elements to it.
Let's play
Enough theory, let's have a look. I'm using the command line application curl to talk to the KNIME Server, which is a very nice way of debugging and exploring the API. As I said, there is a single entry point to the server, the billboard:
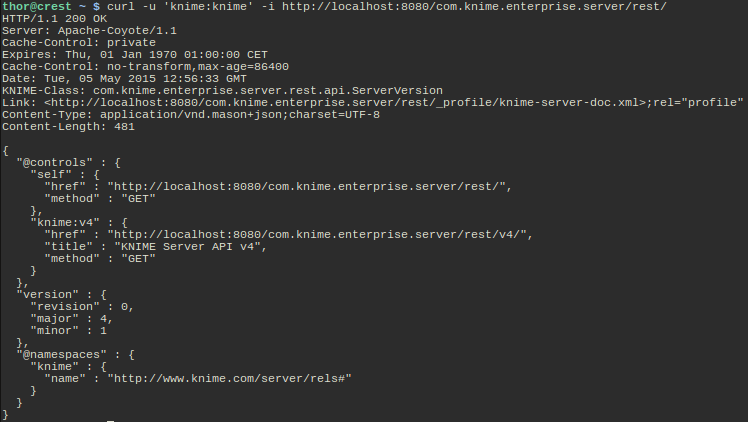
What do we see here?
- The server tells us that the Content-Type of the response is application/vnd.mason-json. This is important for the client in order to be able to interpret the data that is being sent.
- If you are using our Java API, you know that the class corresponding to the resource in the body of the response is com.knime.enterprise.server.rest.api.ServerVersion. If you don't want to parse Mason by hand you can simply create an object of this class from the content using JAX-RS.
- The body contains the server's version as the actual resource data (the "version" block in the middle).
- All elements prefixed with "@" are Mason specific elements. The most important element is @controls which represents the links a client can follow.
- One control is always the "self" link which points to the resource itself.
- The "knime:v4" link points to another billboard, in this case the one for the 4.x series. Later server versions may add a link for 5.x if the interface changes in an incompatible way.
- If the client knows the meaning of "knime:v4" he can follow it and thereby perform the desired operation. The meaning of the link relations (and the application specific data parts of the Mason document) is described in the profile linked in the header (see the "Link"). I.e. the documentation is part of the server installation.
Let's look at another example: executing a workflow job. By following the links in the server responses I have reached a workflow that I want to use as a web service:
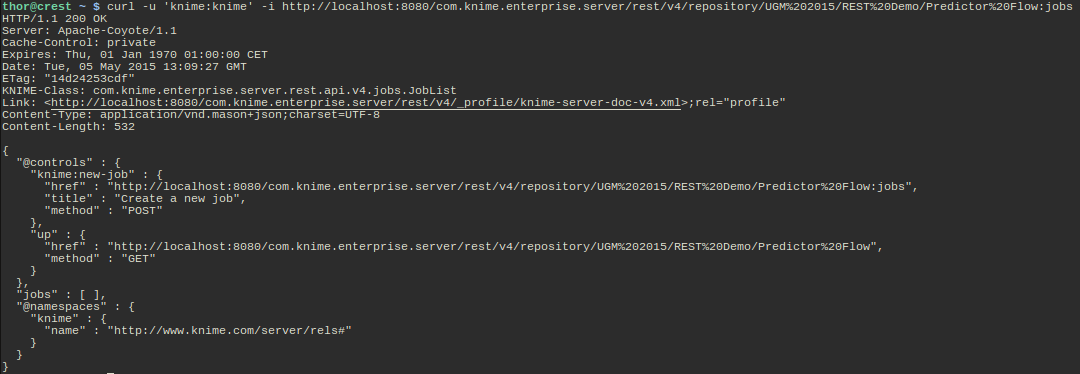
GETing the URL returns me the "jobs" resource for this particular workflow. As you can see there are currently no jobs (the array "jobs" is empty) but there is a link in the @controls block that lets me create a new job. Therefore I POST to this URL and see what happens (I have shortened the response a bit for better readability):
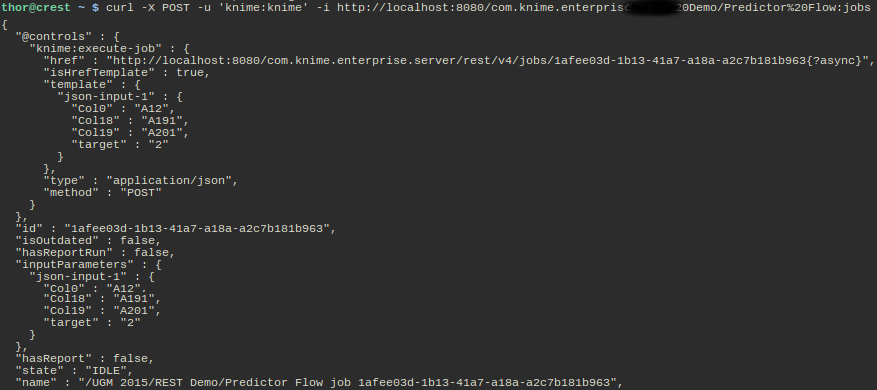
The server sends us some data about the new job (id, if it has a report, current state, name) and also again a link for executing the job specified by the "knime:execute-job" relation. This time the link is a URI template with an optional part that indicates whether execution should occur synchronously or asynchronously (the meaning of the parameter is explained in the profile). The control also specifies a template for the data that are sent with the POST request for executing the workflow. The client can now read the template, change the values to its needs, and then POST it:
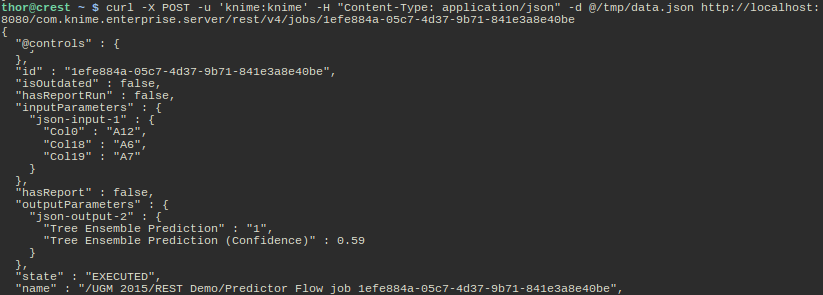
I didn't specify the "async" query parameter in the URL so the call waits until the workflow is executed and returns the results, which in this case is the current representation of the job resource. Notice the new state EXECUTED and the new "outputParameters" block which contains the results of the workflow execution (a prediction using some static model and the supplied input parameters). I can now re-execute this workflow again with different input parameters several times. If I don't need the job anymore, I simply DELETE it:

Please ignore the different job ID, as I forgot to include the HTTP headers while deleting the job from above - I hope you get the concept anyway.
Coming to an end
I hope you are still with me and have gained an impression about the new functionality in KNIME Server 4.1. This version will enable you to browse the workflow repository, create and execute jobs, and fetch reports via REST calls. Future versions will add workflow up- and downloads, and the ability to change permissions, create scheduled jobs, etc. Our goal is to provide full server functionality via the REST interface.
If you have been infected by the REST virus, I can highly recommend three books that helped us a lot during the specification and implementation phases:
- RESTful Web APIs by Leonard Richardson, Mike Amundsen, Sam Ruby (a MUST read in my opinion)
- RESTful Web Services Cookbook by Subbu Allamaraju
- RESTful Java with JAX-RS 2.0, 2nd Edition by Bill Burke