
Invisible characters are one of the most frustrating problems in data cleaning. They hide in your text data, invisible to the eye but powerful enough to break imports, corrupt searches, and silently ruin your analysis.
These hidden characters sneak in when you copy and paste from emails, websites, spreadsheets, AI-generated outputs, or APIs. The source contains invisible Unicode characters representing formatting instructions that get carried into your data. The result? Data imports fail, searches return nothing, sorting breaks, and filters stop working. Often with error messages that don't tell you what went wrong.
The worst part? You can spend hours hunting for the problem because you literally can't see it.
In this guide, we'll explain what invisible Unicode characters are, show you the most common types, and walk you through how to find and remove them using KNIME.
What are Unicode characters?
Unicode characters belong to the Unicode Standard, a text encoding standard where a unique number (code point) is provided for every character. This is regardless of platform, program, or language. The standard enables consistent representation and handling of text in different languages and scripts on computers and other devices. This means that any text can be encoded and processed in Unicode.
For example, in the Tamil script, the letter "a" is denoted by அ. The Unicode code point for this Tamil character is U+0B85.
The "U+" followed by numbers in Unicode represents a Unicode code point. The "U+" is a notation to indicate that the following numbers are in hexadecimal (base-16) format. A Unicode code point is a unique numerical identifier assigned to each character. In other words, Unicode code points are used to uniquely identify and represent each character, symbol, and emoji.
These codes ensure that characters can be understood and used similarly on different computers, programs, and coding languages. Hexadecimal representation is commonly used because it allows for concise and human-readable representation of large numbers.
There are various categories or classes in Unicode for characters based on their general properties. These categories provide a standardized way to classify characters from different languages and writing systems. The most relevant categories are:
| Category | Regex Pattern | Examples |
| Letter (L) | \p{L} | A, б (Cyrillic), 漢 (Chinese) |
| Number (N) | \p{N} | 1, Ⅳ |
| Symbol (S) | \p{S} | +, $, ♫ (musical note), ☀️ (sun symbol). |
| Format (Cf) | \p{Cf} | Zero-Width Space (U+200B), Zero-Width Joiner (U+200D) |
These categories help for several reasons, for example in text processing- to count letters, and identify punctuations, The Format (Cf) category is the one that contains invisible characters, and the one we'll target to clean your data.
What are invisible Unicode characters?
Invisible Unicode characters are characters that exist in your data but have no visual representation. They take up space, affect how text is processed, and influence how data is sorted, searched, and filtered. But you can't see them on screen.
These hidden characters include whitespace characters (spaces, tabs, line breaks), zero-width characters (Unicode blank characters that appear as no space at all), and control characters that aren't rendered on screen.
Examples of invisible Unicode characters
Invisible Unicode characters come in various types, each having a different purpose.
Some of the common types are:
- Whitespace Characters:
- Space (U+0020): The most familiar invisible character, representing a blank space.
- Tab (U+0009): Used to create horizontal space between characters.
- Zero-Width Characters:
- Zero-Width Space (U+200B): Appears as no space but influences line breaking.
- Zero-Width Joiner (U+200D): Facilitates the joining of adjacent characters.
- Control Characters:
- Carriage Return (U+000D): Moves the cursor to the beginning of the line.
- Line Feed (U+000A): Advances the cursor to the next line.
Often, they will cause data imports to fail with error messages that don't necessarily specify exactly what went wrong. This results in spending a lot of your time trying to figure out how to fix it, only to get an obscure error message that's not helpful.
Common invisible characters at a glance
| Character | Code Point | What It Does | Where It Sneaks In |
| Space | U+0020 | Blank space between words | Everywhere |
| Tab | U+0009 | Horizontal spacing | Spreadsheets, TSV files |
| Zero-Width Space | U+200B | No visible space affects line breaks | Web copy, HTML editors |
| Zero-Width Joiner | U+200D | Joins adjacent characters invisibly | Emoji sequences, multilingual text |
| Carriage Return | U+000D | Moves the cursor to the start of the line | Windows line endings, CSVs |
| Line Feed | U+000A | Advances to the next line | Unix/Mac line endings |
| Byte Order Mark | U+FEFF | Marks encoding type at the file start | CSV exports, UTF-8 files |
| Soft Hyphen | U+00AD | Invisible hyphenation hint | Word processors, web content |
| Non-Breaking Space | U+00A0 | Space that prevents a line break | Web pages, PDFs, AI-generated text |
Where invisible characters come from
Invisible Unicode characters are more common than ever. Here are the most frequent sources:
- AI-generated text: LLM outputs from ChatGPT, Claude, Gemini, and other tools can contain zero-width spaces, non-breaking spaces, and other invisible formatting.
- Web scraping and API responses: HTML source code often includes hidden formatting characters.
- Copy-pasting from websites or PDFs: Different encoding standards (UTF-8, ISO-8859, etc.) introduce invisible characters during conversion.
- Spreadsheet exports: Excel uses ISO-1252 encoding while many tools expect UTF-8. The mismatch injects hidden characters.
- Cross-platform collaboration: Files edited on Windows, Mac, and Linux use different line ending characters.
Find and remove invisible Unicode characters with KNIME
KNIME is a data analytics and AI platform with a visual, drag-and-drop interface that lets you build workflows and gives you three ways to handle invisible characters, depending on how much control you need:
1. Spot invisible characters before you remove them with the String Format Manager node
2. Remove invisible characters without regex using the String Cleaner node
3. Target specific characters with regex using the String Replacer node
Let's start with a common scenario.
Let's say you are a data scientist and you are working with a dataset that is copied from an Excel sheet into a web editor. Since Excel uses an ISO-1252 encoding and a web editor uses a UTF-8 encoding, they don't seamlessly align, and you encounter some problems.
You discover that the sneaky culprit is an invisible Unicode character.
For example, let's say that the dataset in Excel will look like this:

Here, an invisible character (Zero-Width Space) is intentionally inserted in the first row's description.
When this is copied into a text editor, the invisible characters are not correctly represented due to an encoding mismatch. It will look like this:

1. Spot invisible characters before you remove them
One of the trickiest parts of dealing with invisible characters is confirming they're actually there. The String Format Manager node helps with this. It attaches display formatting to your string columns without changing the underlying data. When configured, it shows placeholder symbols for non-printable characters like line breaks, carriage returns, tab stops, and non-breaking spaces directly in the Table View.
This means you can visually inspect your data and see exactly where invisible characters are hiding, without switching to another tool.

To set it up: connect the String Format Manager to your data, select the string columns you want to inspect, and check the option to display non-printable characters as symbols. The output table will look the same, but with visible placeholders where invisible characters exist.
2. Remove invisible characters without regex
If you'd rather skip regular expressions, the String Cleaner node handles invisible character removal through a simple configuration dialog. It can:
- Remove special sequences (accents, diacritics, non-ASCII characters, non-printable characters)

- Remove characters (letters, numbers, punctuation, symbols, emojis or custom characters)
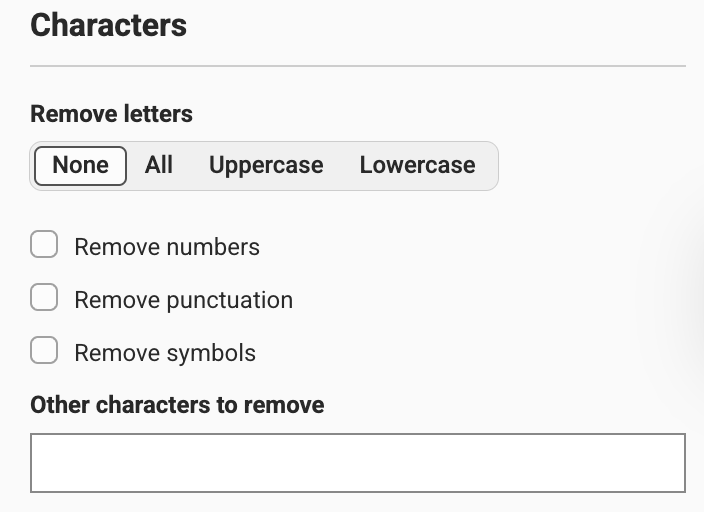
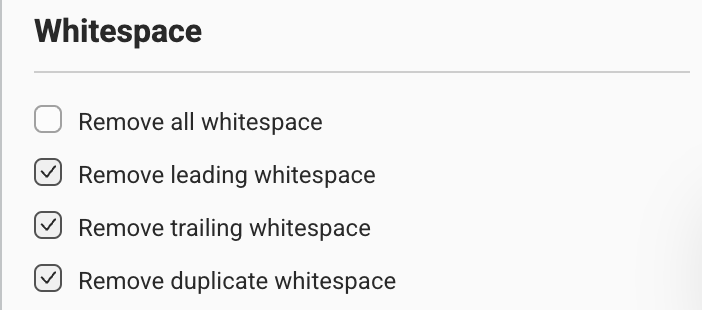
- Clean up whitespace (remove all, leading, trailing, or duplicate whitespace)
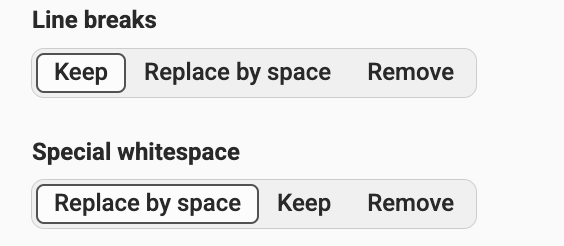
- Handle line breaks and special whitespace (keep, replace with space, or remove)
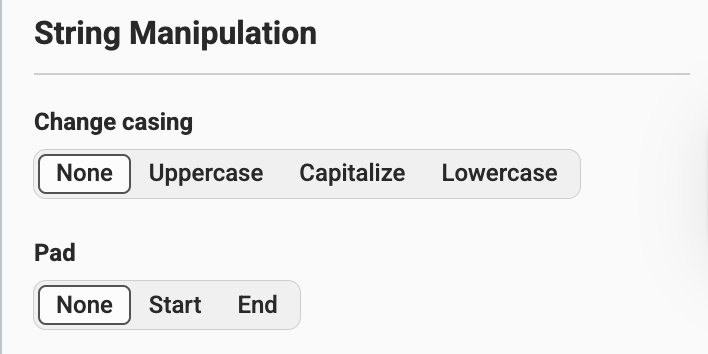
- Change casing and pad strings (uppercase, lowercase, capitalize, pad to minimum length)
To use it: connect the String Cleaner to your data, select the target columns, and enable "Remove non-printable characters" and "Remove special whitespace" (or replace with standard space, depending on your needs). You can choose to modify the column in place or create a new output column.
For more control over exactly which characters to target, you can use the String Replacer with a regex pattern.
3. Target specific characters with the String Replacer node
Step 1: Connect the String Replacer node to your dataset
Connect the String Replacer and open the configuration window.
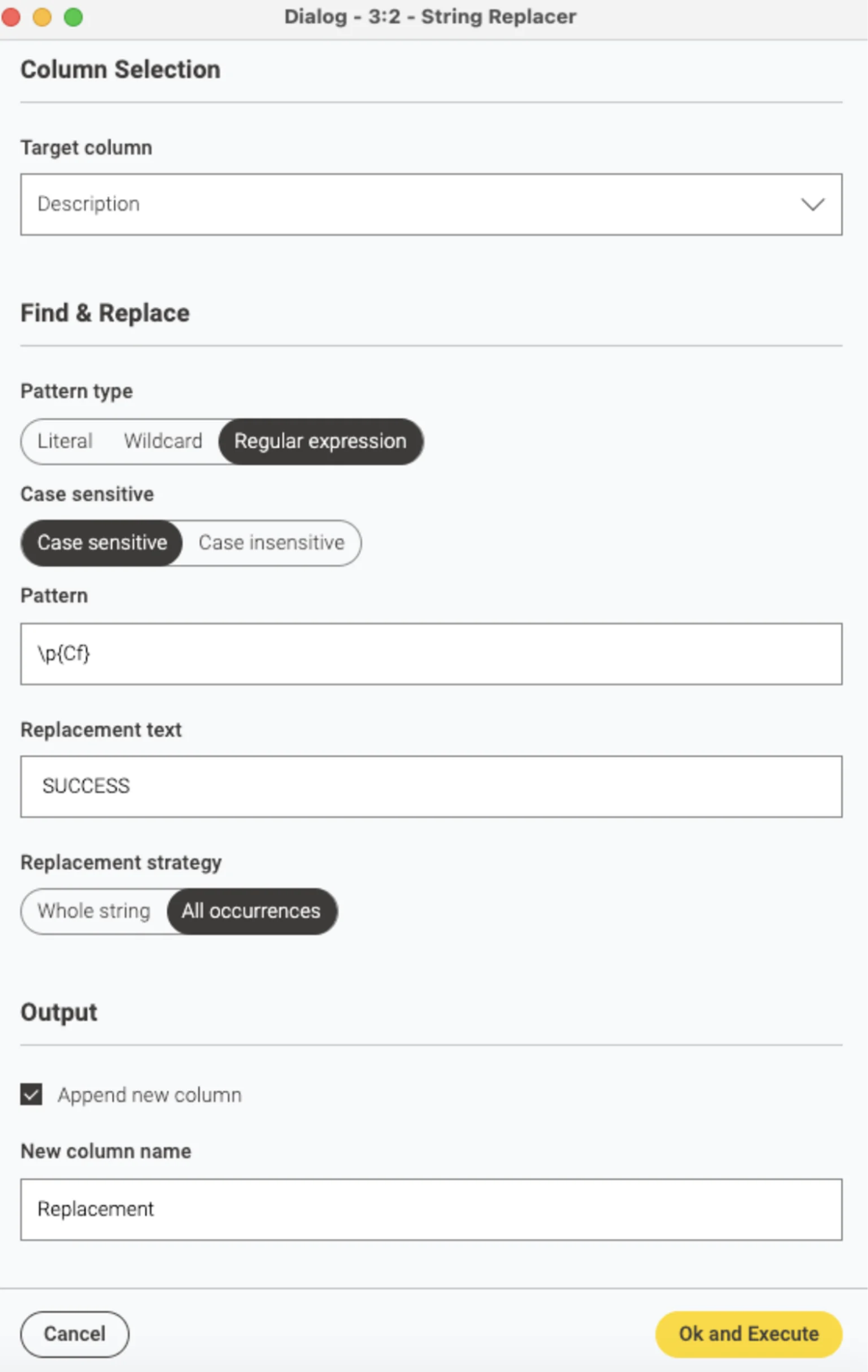
Step 2: Choose the target column
Select the column containing the invisible Unicode characters. In this case, the target column is named "Description".
Step 3: Select "Regular expression" as the pattern type
The String Replacer offers three pattern types: Literal (exact match), Wildcard (flexible match with * and ?), and Regular expressions. Select Regular expression. This lets us target all invisible characters at once using Unicode category patterns.
Step 4: Enter the pattern \p{Cf}
This is the key. The pattern \p{Cf} matches any character in the Unicode "Format" category, which includes all invisible formatting characters like zero-width spaces, joiners, and other hidden characters.
Enter \p{Cf} as the pattern and leave the replacement text empty (or enter a placeholder like "SUCCESS" to verify it worked).
Step 5: Create a new column for the output
Checking the "Append new column" box creates a new column in your dataset. The new column contains the "cleaned" text where the invisible characters are removed and replaced. The new column is named "Replacement".

That's it!
Not sure which approach to use?
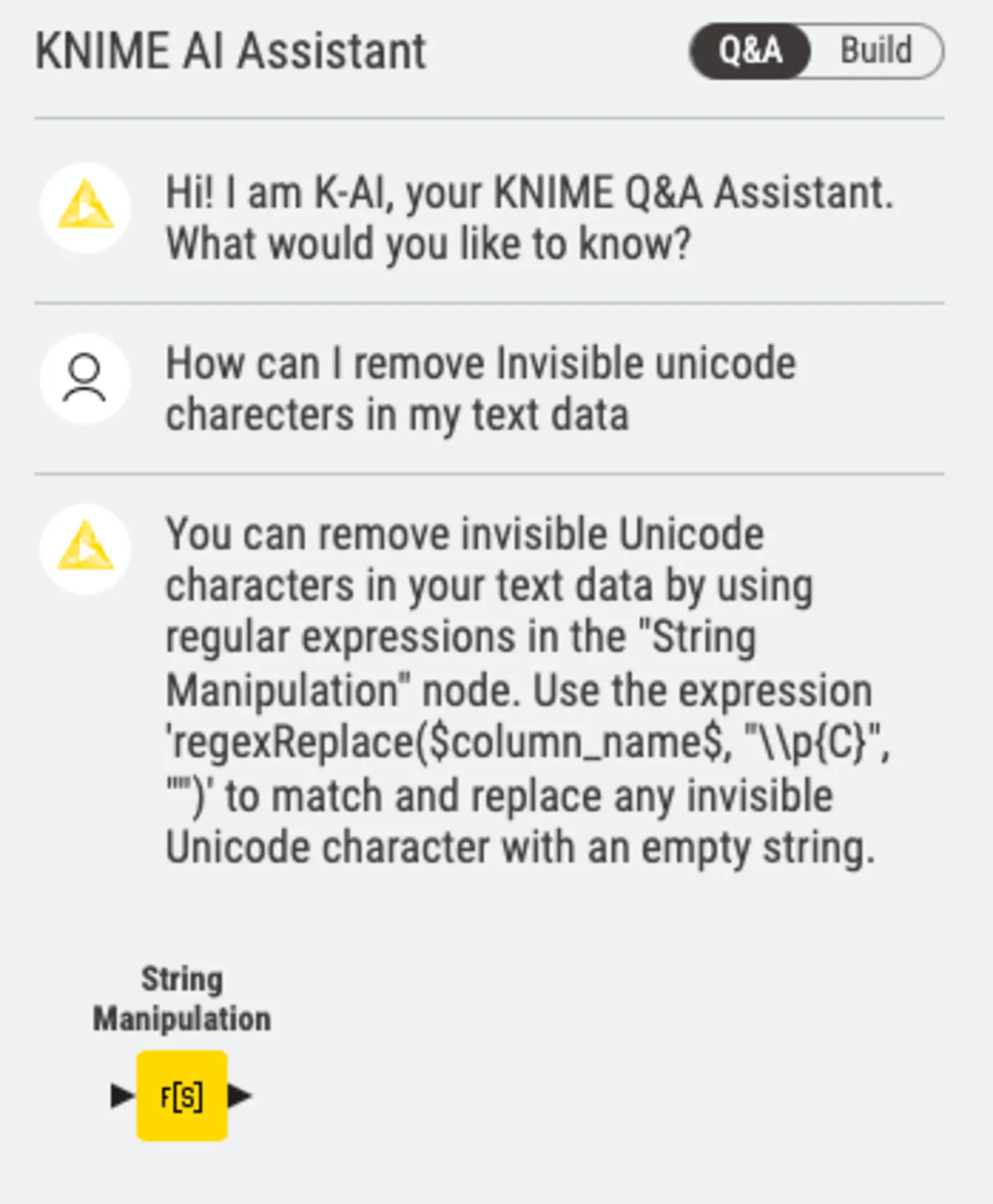
Get tips from K-AI, KNIME's AI Assistant
KNIME has an AI assistant, K-AI, that builds visual workflows for you based on your directions. Using the prompt "How can I remove invisible Unicode characters from my text data?" and following the output of K-AI to configure the String Manipulation node, you get the desired result.
Clean data faster with KNIME
Invisible characters are a common headache, but they don't have to slow you down. With KNIME, you can:
- spot them using the String Format Manager
- clean them up in one click with the String Cleaner
- target specific characters with the String Replacer and a regex pattern.
Pick the approach that fits your situation and get back to the work that actually matters.