
In the age of AI, open source technology has broadened its capabilities to also include LLMs. Open source models have increasingly matched the performance of closed source counterparts, leading many in academia and industry to favor open source LLMs for innovation, scalability, and research.
The appeal of open source LLMs is driven not only by performance but also by concerns over code accessibility, data privacy, model transparency, and cost-effectiveness that are typical of proprietary options. Adding to the appeal of open source LLMs is the possibility of running them locally, successfully addressing corners over data security and privacy that are crucial for sensitive and regulated environments.
In this article we want to show how you can use the low-code tool, KNIME Analytics Platform, to connect to Ollama. Ollama is an open-source project that provides a powerful AI tool for running LLMs locally, including Llama 3, Code Llama, Falcon, Mistral, Vicuna, Phi 3, and many more.
In this tutorial, you'll learn step-by-step how to use KNIME's AI Extension to quickly access open source LLMs locally via Ollama. Download the workflow to work hands-on through the tutorial.
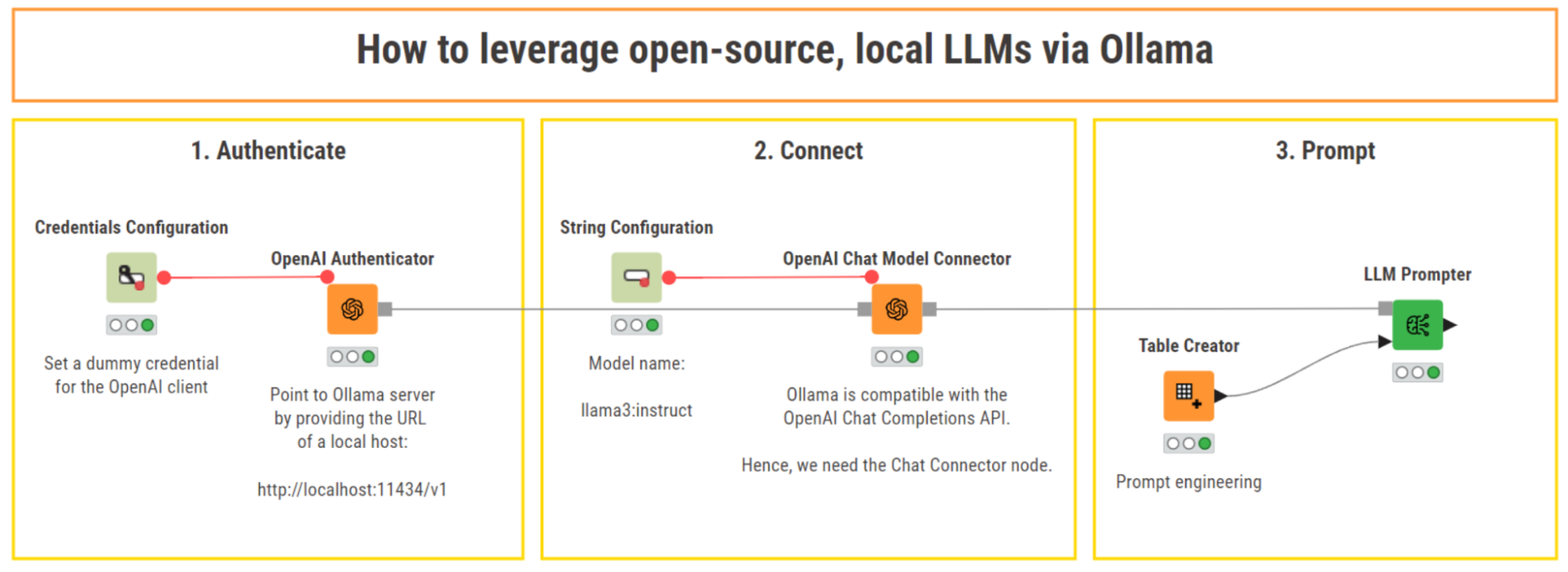
Authenticate – Connect – Prompt using KNIME
The general approach is the usual: Authenticate – Connect – Prompt. This is valid for all API-based LLMs, and for local chat, instruct, and code models available via Ollama from within KNIME.
For some LLMs in KNIME there are pre-packaged Authenticator nodes, and for others you need to first install Ollama and then use the OpenAI Authenticator to point to Ollama.
This means that we have a step 0 to "Install and set up Ollama”.
Let’s get started!
Step 0: Install and set up Ollama
To start using the local LLMs provided by Ollama, we first need to follow a few simple set up and installation steps:
- Download Ollama from the official website: https://ollama.com/download. Ollama is compatible with macOS, Linux and Windows.
After downloading, the installation process is straightforward and similar to other software installations. Upon completion, Ollama provides a local API that enables users to download models and interact with them from their machines.
Browse Ollama’s model library and pick the LLM that fits your needs: https://ollama.com/library. There is plenty of choice in terms of model capabilities (e.g, conversational, instructional, etc.), and size.
For this tutorial, we select “Llama3-instruct” because it is a good trade-off between capabilities and size (4.7 GB). Model size is an important criteria when choosing your local LLM, for larger models require more computational power.
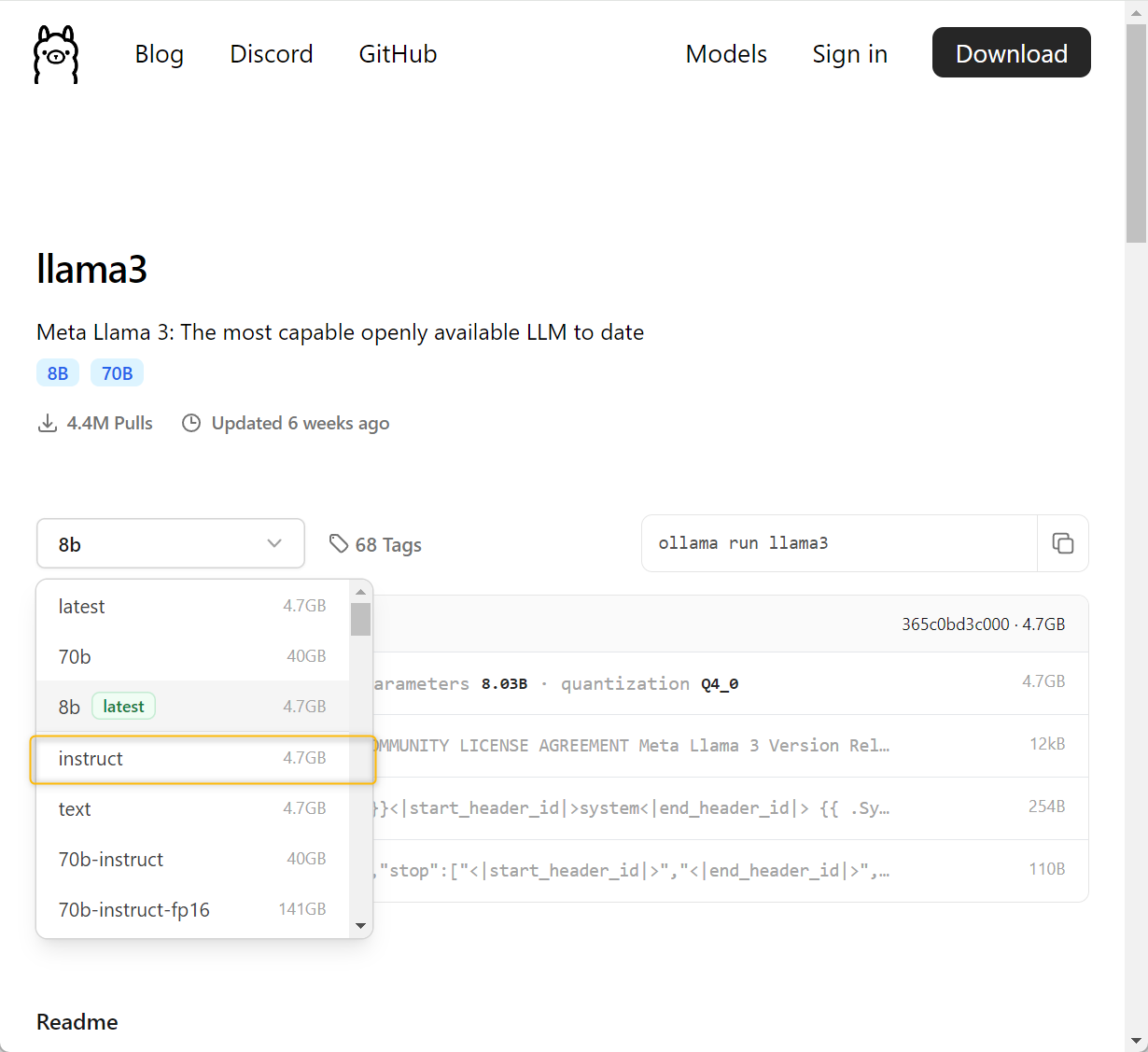
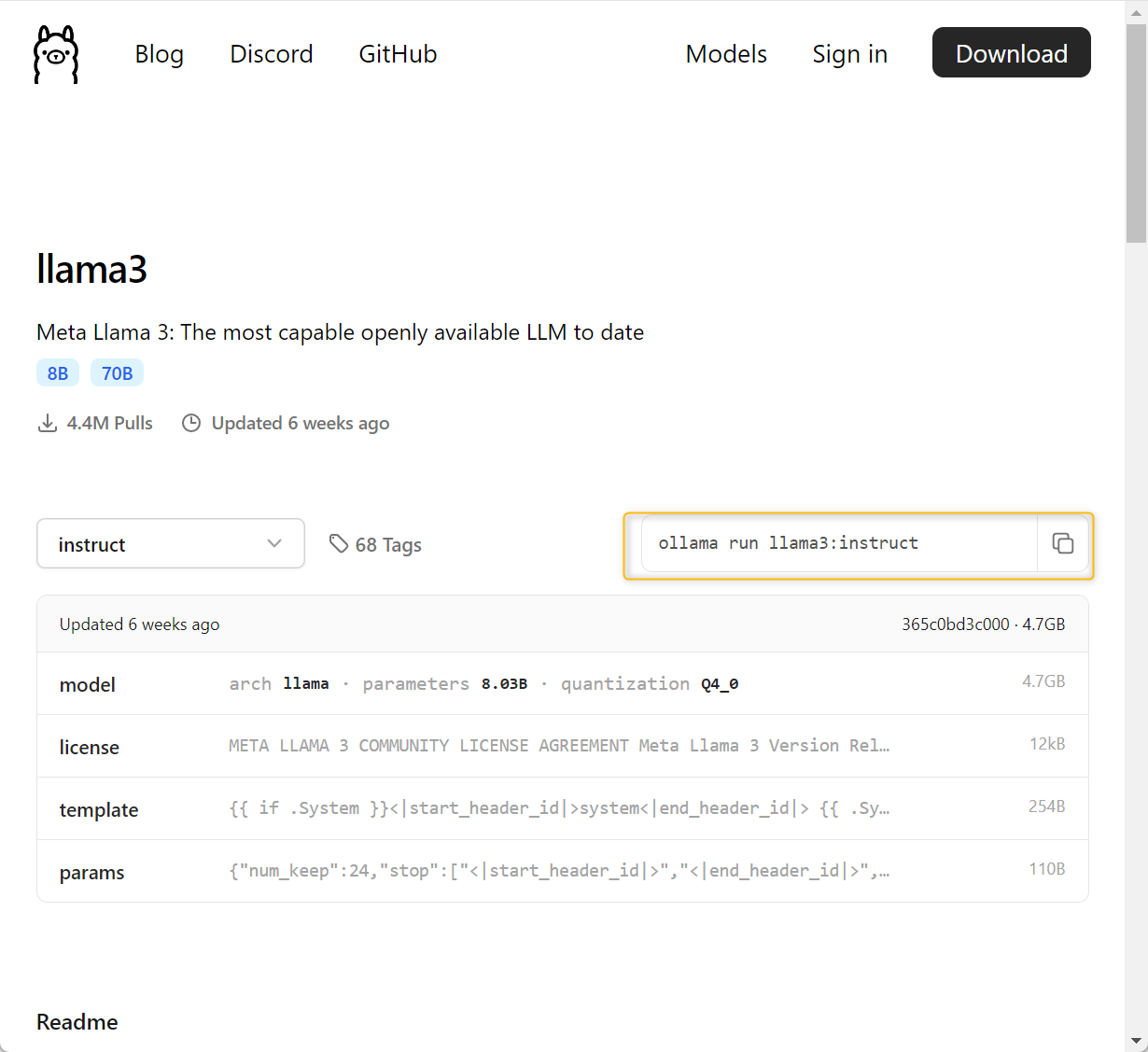
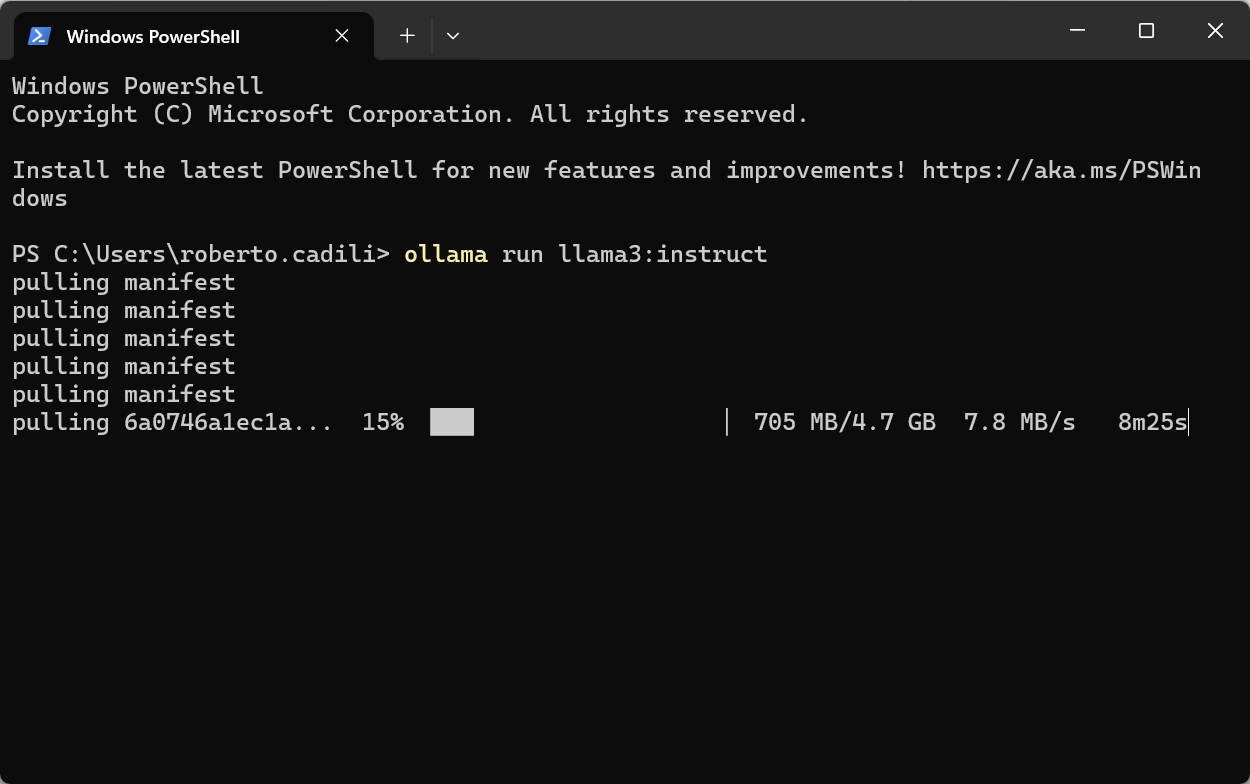
- Download the LLM of choice from Ollama. To do that, copy the download command that is automatically generated in the model card and paste it in a command-line shell. This command will download the model and other metafiles in a dedicated folder on your machine.
ollama run llama3:instruct
You are now all set to start using “Llama3-instruct” in KNIME in just three steps:
- Authenticate
- Connect
- Prompt
Step 1: Authenticate to establish a gateway to the Ollama server
The first step involves establishing a gateway to the Ollama server.
To do that, we rely on the OpenAI Authenticator node. Why? Because since February 2024, Ollama has built-in compatibility with OpenAI. This allows us to use this and the other OpenAI nodes in the next steps to conveniently specify the URL of a local host, connect to the LLM of choice, and send POST requests to the local API. In this way, we are freed from the burden of having to assemble and properly format a request body, and parse the resulting JSON output.
We start off by inputting a dummy credential in the Credential Configuration node (in the "password" field). This is needed just for the OpenAI client in the OpenAI Authenticator and is not actually accessing any service.
Next, we select the dummy credential flow variable in the OpenAI Authenticator, and configure the node to point to Ollama server by providing the base URL of a local host in the "OpenAI base URL" field (advanced settings):
http://localhost:11434/v1
You can find the base URL for a local host in the Ollama press release on OpenAI compatibility.
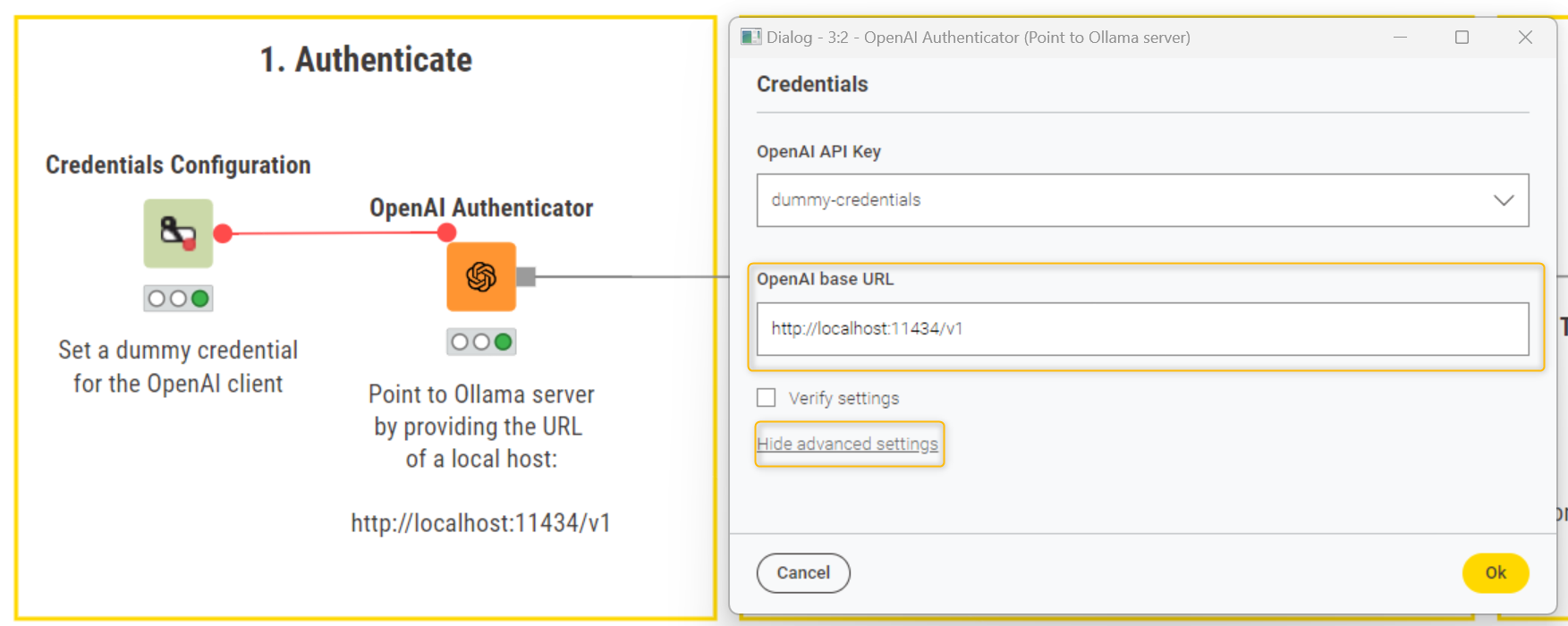
Note: Make sure you uncheck the “Verify settings” box. This ensures that we don’t call the list models endpoint, allowing the node to execute successfully with the provided base URL.
Step 2: Connect to your LLM model of choice
To connect to the model of choice, first we type the model name in the String Configuration node. The model name needs to match exactly the format defined by Ollama in the model card, that is: llama3:instruct.
Next, we drag and drop the OpenAI Chat Model Connector node, which we can use to connect to Ollama’s chat, instruct and code models. We need this specific connector node (and not the OpenAI LLM Connector) because Ollama has built-in compatibility only with the OpenAI Chat Completions API, which is what the OpenAI Chat Model Connector node uses behind the hood.
If we wish to leverage Ollama’s vision and embeddings models, we can do so using the nodes of the KNIME REST Client Extension.
In the configurations of the OpenAI Chat Model Connector, we navigate to the advanced settings and control the "Specific Model ID" with the flow variable containing the model name (i.e., llama3:instruct). This configuration will overwrite the default model configurations in “Model ID”.
If needed, we can also tweak the model hyperparameters to our liking.
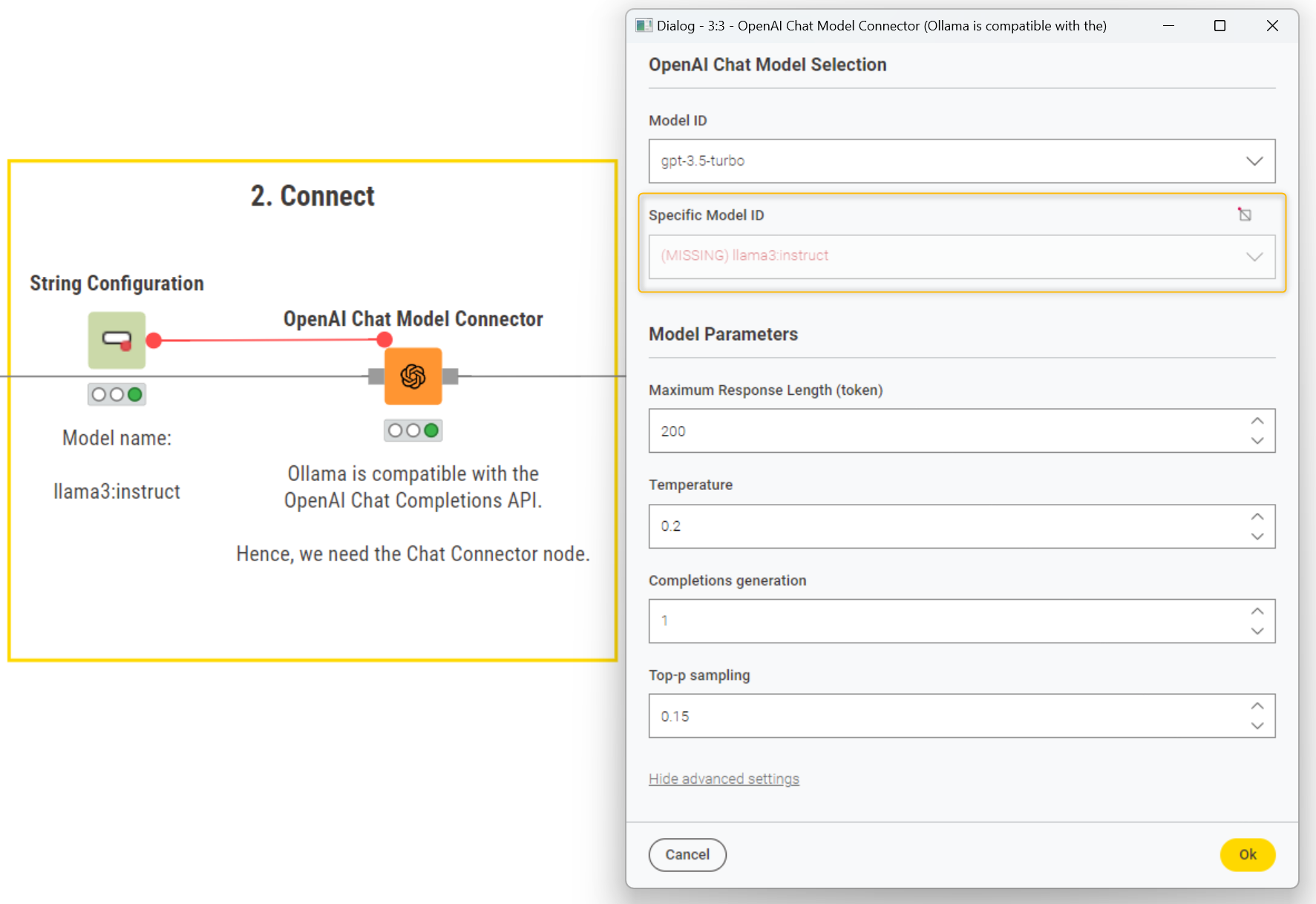
Note. The "missing" warning in the "Specific Model ID" appears because the node can't find "Llama3-instruct" among OpenAI models. This is expected since "Llama3-instruct" is not an OpenAI model and the warning can be disregarded.
Step 3: Prompt to query Llama3-instruct
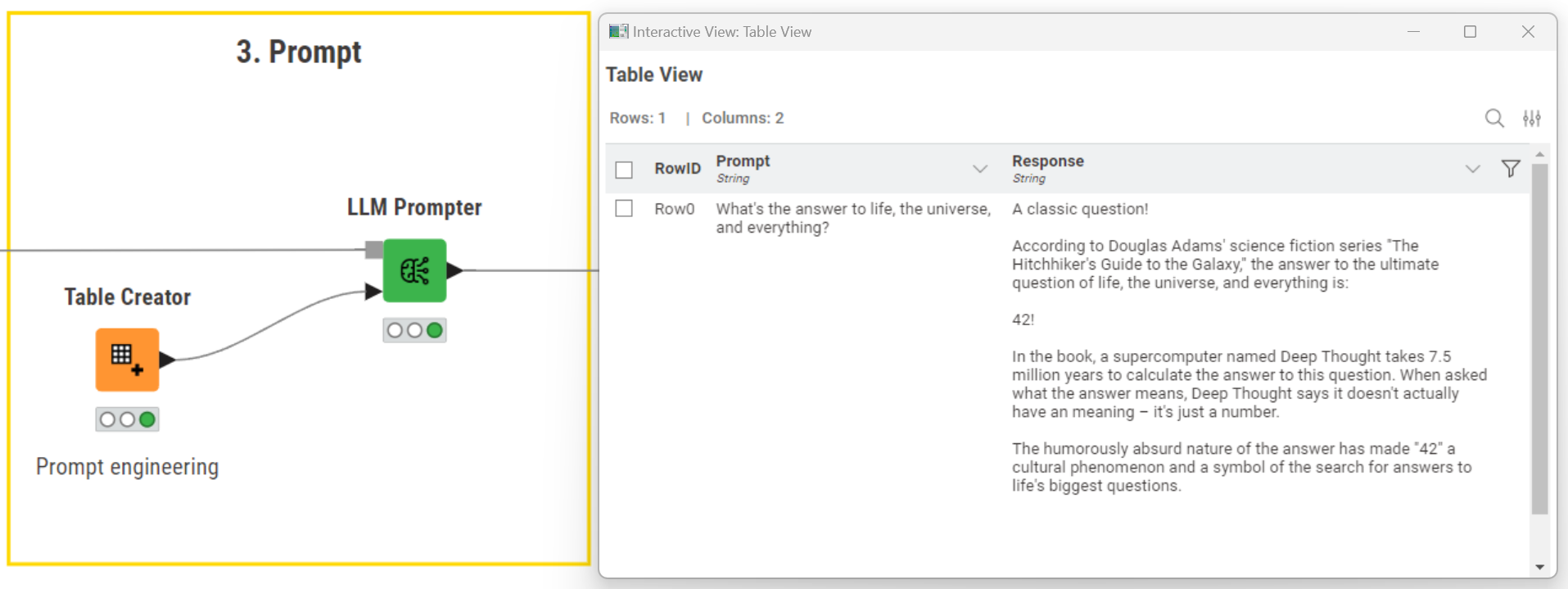
To query “Llama3-instruct”, we type our prompt in the Table Creator node. In more complex scenarios, we can use the String Manipulation node to type and format the prompt, taking into account columns and values in a dataset.
Lastly, we drag and drop the LLM Prompter node. This node takes as inputs the model connection and the prompt. In our example, we asked:
“What's the answer to life, the universe, and everything?”
The model smartly caught the reference in the prompt and provided the answer we expected, quoting “The Hitchhiker's Guide to the Galaxy” by Douglas Adams.
Note. When prompting, make sure Ollama is running as a background process on your machine.
Open source technology for scalable GenAI
In just three steps, we showed how you can combine Ollama's vast model library with KNIME's flexible capabilities for GenAI to access and prompt 80+ open source LLMs models in a local environment. This approach not only ensures data privacy and control but also provides easy customization, flexibility and scalability for various applications.
You can also use the low-code tool, KNIME Analytics Platform to connect to open source LLMs, both via API for models hosted on Hugging Face and locally via the GPT4All initiative.
Unlock new potential in your workflows with the KNIME AI Extension. Explore a collection of ready-to-use workflows using KNIME for Generative AI.