
You have probably already heard the rumors that there will be a KNIME release at the end of September. This is in addition to our usual release cycle of two releases per year, one in July and the other before Christmas. This release features quite a few major changes and we hope for assistance from the community to validate that these changes don't cause any unexpected problems. That is why we decided to release KNIME 3.0 as a public "preview" that anybody can test and use. Please be aware that we don't recommend using it for production! The next production-ready version will be KNIME 3.1 in December.
In this three-part series on the KNIME 3.0 release we will highlight some of the mentioned major changes. Part 1 will deal with internal changes to the underlying architecture and API. Part 2 will present changes we made to the user interface, while in Part 3 we will talk about other noteworthy additions.
Framework Changes
The biggest change in KNIME 3.0 is the move from Eclipse 3.7.2 to Eclipse 4.5.0 and from Java 7 to Java 8. Ideally users shouldn't notice these changes at all (except for minor layout changes in the GUI), but as always reality is often far from ideal. We have already spotted a number of minor glitches but have been able to solve them all so far. So what was the reasoning behind wanting to move to the new versions?
Eclipse 3.7 was released in 2012; now, however, bugs are no longer fixed and there are no feature additions. This is mainly a problem for Linux users, as browser integration depends on operating system libaries (notably Webkit) which have progressed quite a bit since 2012. Integrating native libraries in Java applications is usually a complex procedure and can break easily if the native library changes. Unfortunately we have seen this happening quite a few times already (resulting in application crashes whenever HTML content was to be rendered) but we were able to backport the browser integration from more recent Eclipse versions. Naturally, however, we wanted to get rid of this rather ugly workaround and this entailed moving to the latest Eclipse 4.5. However, other than that there are no relevant changes for users, and if developers have been using our standard node API, there will be no (or only trivial) changes required on their end - usually a simple re-compilation is enough.
The transition to Java 8 wasn't as pressing as the one for Eclipse, but Java 8 brings along quite a few very nice additions to the language. They don't make the impossible possible, but in some places they make your code much simpler and still more readable! Here are three new concepts in Java 8 that I already use on a daily basis:
- Lambda expressions. If you have ever had to learn a functional programming language, you may already know them. In short, they function without names (anonymous function) and in Java they can replace anonymous classes implementing single-function interfaces. Just one short example: Instead of
Arrays.sort(args, new Comparator<string>() { public int compare(String a, String b) { return Integer.compare(a.length(), b.length()); } });you can now simply writeArrays.sort(args, (a, b) -> Integer.compare(a.length(), b.length()));
This is not only shorter but also more readable (once you get used to the new syntax). - Stream API. This one will eliminate at least 50% of the loops in your code, if not more. I guess all programmers know cases of having a collection of objects, wanting to filter them based on some property and then compute an aggregate over all remaining objects (for example). This requires at least two loops, a few if statements, and a temporary collection (or something similarly complicated). With the Stream API (which makes heavy use of Lambda expressions), this is now as simple as
double averageIncome = taxpayers.stream() .filter(tp -> (tp.age > 30) && (tp.age < 50)) .mapToInt(tp -> tp.income) .average().getAsDouble(); - Optionals. These add a bit of syntactic sugar, their sole purpose being to eliminate NullPointerExceptions. You probably know the problem: a method returns an object that may be null but the caller doesn't check it and then "boooom". One solution, in such a case, is to return an Optional . Then the caller has to explicitly invoke a method to get the real object inside the Optional. At this point in time you should really start to think about why you need to invoke a method and what happens if there is null in the Optional. Not the killer solution against NullPointerExceptions but it's definitly a step forward.
There are quite a few other new features in Java 8, with explanations available for all of them online, if you are interested in finding out more about them.
Unfortunately there is one rather inconvenient change in Java 8 that affects the output of some nodes. Java 8 has made some internal changes to hashes. In some cases this changes the order in which elements are returned. Hashes have never guaranteed any particular element order (there is the LinkedHashMap for such cases) but some nodes relied on the order for creating the output (order of rows, columns, or even contents of cells). These nodes may now output different results, but the output is still correct! It's really only the order that has changed. We have changed all the affected nodes so that for any case they will now produce the same results for the same input data.
API Changes
In KNIME 3.0 we also changed our node extension API.
Row count
One relatively small change with major consequences is the introduction of a new
method in the
. Similar to the well-known
method it will return the number of rows in the table - but as
! This means that KNIME can now handle tables with more than 2 billion rows. This hasn't been an issue for 99.9% of all KNIME users so far, but with the Big Data hype it's becoming more common to process really large amounts of data. We haven't removed the
method (so existing nodes still work as before) but it's now deprecated and new implementations should use
instead. If an old implementation still uses
and the input table has more than 2 billion rows then an appropriate error is reported. This change also affects a few other interfaces and abstract classes where the number of rows was returned or required as a parameter. They have all been changed accordingly.
Extension point for data types
This is one of my favourite additions to the KNIME API. Up until now, if you implemented your own data type you had to provide a few magic static methods in your cell implementation. In practice this wasn't really an issue and yet from a software engineering point of view it wasn't a particularly elegant solution. The other problem with your custom data type was that nobody could use it, unless there was an explicit dependency on your extension. This becomes problematic when reading data with KNIME's standard reader nodes (File Reader, Database Reader, ...). They had a hard-coded list of basic data types only and e.g. reading dates from a text file always required a second node that converted the string into a date. Now there's a new extension point called
. It defines a data type based on the "simple" cell implementation and allows registering a factory (more on this in a moment) and a list of serializers. Often there are two cell implementations for the same data type, e.g. one for small XML documents (
) and one for larger documents (
). Both require different serializers. They are not returned by the magic
method inside the cell class any more, but registered through the extension point. By way of example, the definition of the data type for XML content is as follows:
The use of the other magic method
is now discouraged as well. KNIME now uses the first implemented
interface instead (unless the method still exists). Therefore you may want to check the order of your implements.
The really new part is the factory class. This is a class that implements
(or one or more of its sub-interfaces) and creates cells from various input formats such as strings or binary input streams. The factory can even decide whether or not a simple cell or a blob cell (or even a file store cell) should be created, depending on the input. These factories can now be used by any node because thanks to the extension point the KNIME Core knows about all of the registered data types and their factories. This information is provided by the new class
. The File Reader, the Table Creator, and the Fixed Width File Reader already make use of this new functionality. Here's a screenshot showing the column edit panel in the Table Creator dialog:
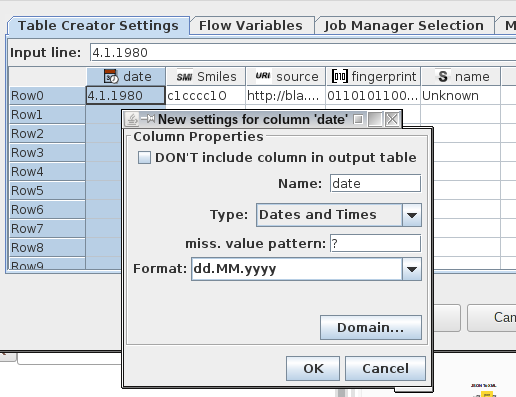
As you can see the five column all have different data types (some of which are provided by extensions); for dates and times you can even specify a pattern for the format used in the input.
All of the KNIME data types have already been ported to the new API and some nodes already make use of it. More nodes will follow in the next releases.
More Changes
Additionally we will also be introducing an extension point for port objects, which removes the usage of magic static methods in port object implementations. And the extension point for nodes will have a flag for deprecating nodes. They should not be removed from the extension point any more, but only flagged as deprecated. The node repository will not show them any more but they can still be loaded in existing workflows.
All these API changes also have the long-term goal of removing buddy classloading from the KNIME Core. This is an interesting Eclipse concept that lets plug-ins access classes from dependent plug-ins (which is usually not possible in this direction) but has some nasty side-effects which can drive you crazy when suddenly objects from the same class are incompatible. I spare you the details on this and hope that with KNIME 4.0 all these problems will be gone.
Having said all this, I want to appeal to all developers to change their node and data type implementations to the new API as soon as possible, even if existing implementation will still work without problems.
So much for internal changes, the next part of this mini-series will present you the new KNIME GUI and some improvements we have made for high resolution displays.