This is part of a series of articles to show you solutions to common finance tasks related to financial planning, accounting, tax calculations, and auditing problems all implemented with the low-code KNIME Analytics Platform.
Credit card fraud detection stands out as an ongoing challenge to accurately identify all new fraud patterns. Datasets containing fraud examples are rare, and when they do exist, they often include a limited number of outdated cases. This scarcity makes fraud detection particularly challenging, as it must continuously adapt to the evolving tactics of fraudsters.
There are two approaches to fraud detection:
- Classic machine learning based predictions, when your dataset contains enough fraud examples
- Outlier detection based techniques, when your dataset does not contain a sufficient number of fraud examples
The dataset that we will use contains a small percent of fraudulent transactions. Based on these examples, we will implement the classic machine-learning based approach for fraud detection for this article.
In the next couple articles, we will show how to implement fraud detection algorithms using outlier detection based techniques.
Whatever your data situation is, this series will show you how KNIME Analytics Platform offers a low-code solution for this problem. It can enable financial teams to automate data intake from various sources and leverage advanced analytics to detect fraudulent transactions, without the need for a coding background.
In this article on fraud detection, you'll learn how to use the Random Forest supervised learning algorithm to help identify fraudulent transactions. Watch the video for an overview.
The task: Identify fraudulent transactions
Credit card transactions can essentially be divided into two categories: legitimate and fraudulent. The task at hand is to accurately identify and flag fraudulent transactions to ensure that a small minority of flagged transactions are legitimate.
The process of fraud detection often involves several manual and automated steps to analyze transaction patterns, customer behavior, and other relevant factors. For our purposes, we will only focus on the automation part of detection by training a model on a labeled dataset and applying it to a new transaction to simulate incoming data from an outside data source.
We use a popular dataset available from Kaggle called Credit Card Fraud Detection. This dataset is composed of real, anonymized transactions made by credit cards in September 2013 by European cardholders. It includes 284,807 transactions over two days, containing 492 fraudulent transactions. The dataset represents a severe class imbalance between the ‘good’ (0) and ‘frauds’ (1), where ‘frauds’ account for only 0.172% of the data.
The dataset contains 31 columns:
- V1 - V28: numerical input variables from a PCA (Principal Component Analysis) transformation
- Time: seconds elapsed from current transaction to first transaction
- Amount: transaction amount
- Class: ‘1’ means fraud, ‘0’ means good/other
A key feature needed for our training is ‘Class’ as we need labeled data for a supervised training algorithm.
The process for creating our classification model follows the steps below. Even if there is data coming from multiple sources, the overall process does not change:
- Create/import a labeled training dataset
- Partition the data
- Train the model
- Evaluate model performance
- Import the new, unseen transactions
- Deploy the model and feed the new transactions in
Notify if any fraudulent transactions are classified
The workflows: Training a machine learning model to identify fraudulent transactions
All workflows used in this article are available publicly and free to download on the KNIME Community Hub. You can find the workflows on the KNIME for Finance space under Fraud Detection in the Random Forest section.
The first workflow covers training our model. You can view and download the training workflow Random Forest Model Training from the KNIME Community Hub.
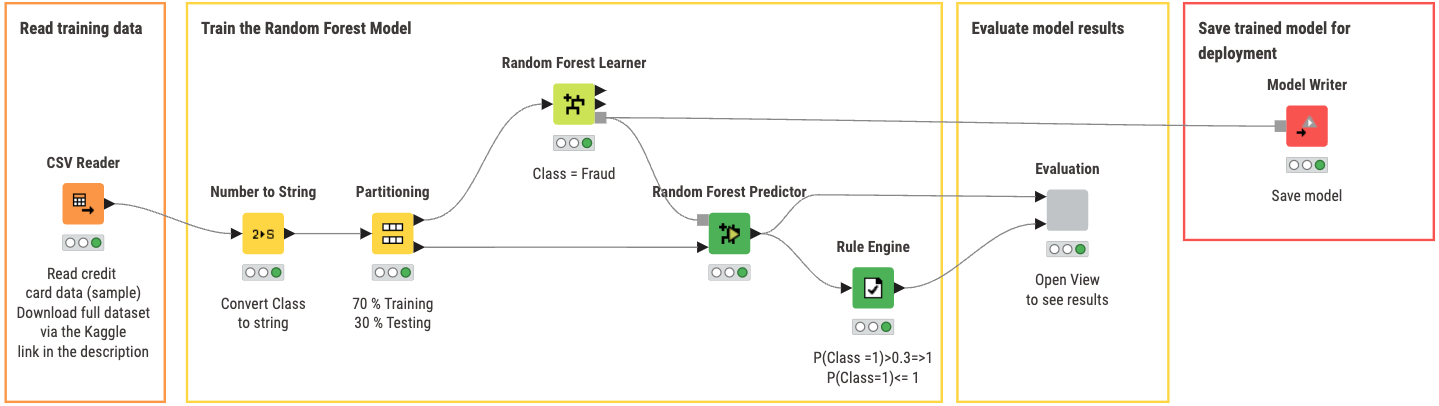
With this workflow you can:
- Read training data from a specified data source. In our case, we use data from the Kaggle dataset previously mentioned.
- Partition the Data by dividing the training data into a 70:30 split, where 70% of our data goes to training the model, and the other 30% for testing the model.
- Train the Random Forest Model by using the Random Forest Learner and Predictor nodes, using appropriate settings.
- Evaluate model results by opening the view of the component ‘Evaluation’ to check overall accuracy of the Random Forest Model.
- Save the trained model for deployment in the next workflow if you are satisfied with the performance of the model
An alternative method could be used if you have two separate datasets for training and testing. You can remove the partition and connect the ‘Number to String’ directly to ‘Random Forest Learner’ or ‘Random Forest Predictor’ depending on which dataset you are using (training goes top, testing goes to bottom).
As an additional metric, we have incorporated a ‘Rule Engine’ node to adjust the threshold for decision-making. Typically, this threshold is set at 0.5, but we've modified it to 0.3. This adjustment aims to explore whether setting a lower threshold can increase the overall accuracy of the predictions by allowing a more sensitive classification criteria, albeit with a potential increase in false positives.
The second workflow Random Forest Deployment deploys the random forest model.
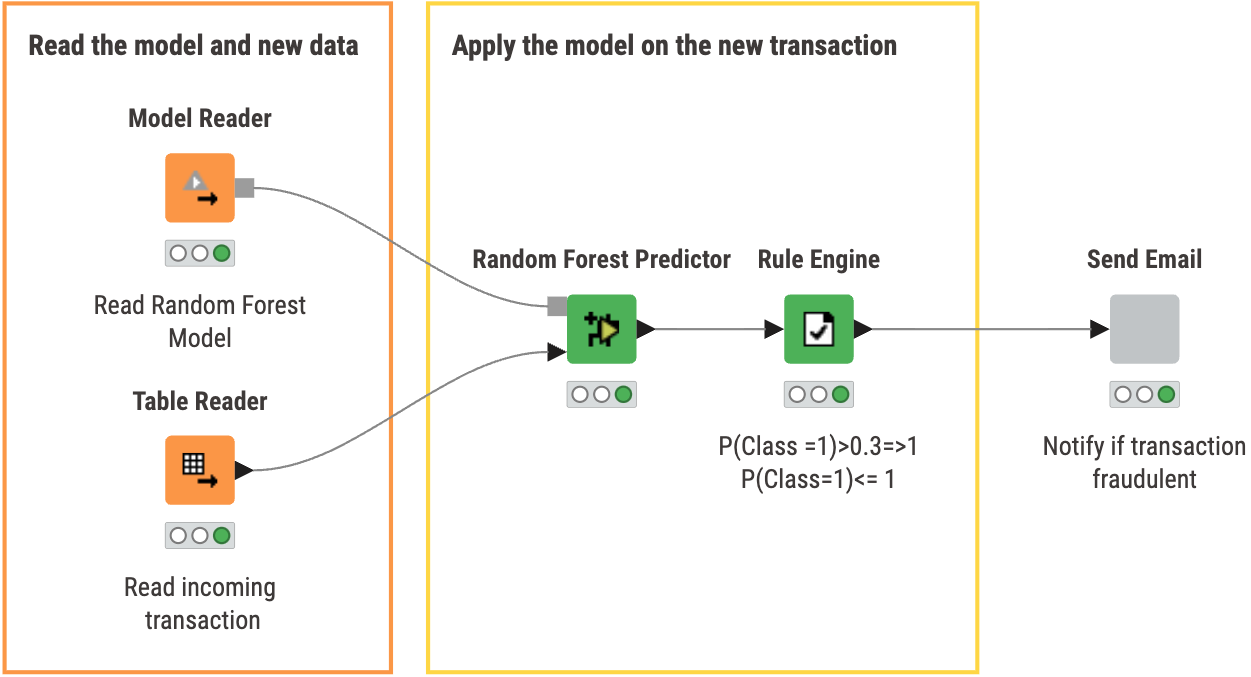
With this workflow you can:
- Read both the previously trained model and new data for classification
- Apply the model on the new transaction and optionally change the threshold value based on performance
- Send an Email to notify if a transaction is fraudulent
Inside the ‘Send Email’ component, we check whether the transaction is fraudulent or not. If it is, an email is sent to the specified person for follow up.
The results: A model to classify transactions
Let’s go back to the first workflow for a moment. From the training workflow, the results we get by opening the view of the ‘Evaluation’ component are shown below.
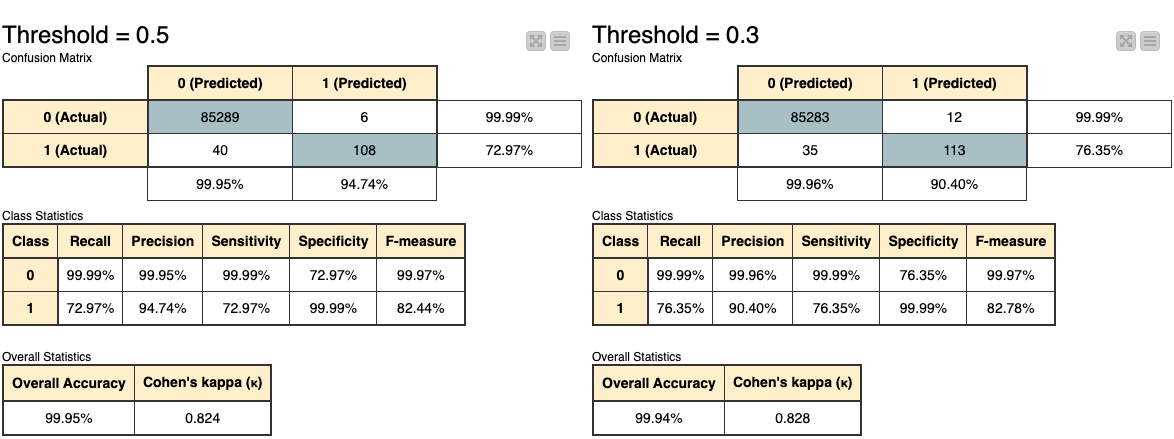
We have two confusion matrices and several tables that show us overall results of the model using two different threshold values. As we can see, they are essentially the same, albeit the threshold value of 0.5 is slightly more accurate.
We can later use this knowledge to update our threshold in the deployment workflow if we see a more significant difference in accuracy, but for our case, the differences are negligible.
The new transaction being read in is passed into the trained model and a threshold is assigned to the transaction. For our case, we use a threshold of 0.3 to classify whether or not the transaction is fraudulent or not.
As shown in the tables above, we did not see a significant difference between the two thresholds.
- A higher threshold means the model needs more confidence before labeling a transaction as fraudulent, making it more cautious about classifying transactions.
- A lower threshold makes the system more likely to identify a transaction as fraudulent, increasing the number of transactions flagged as suspicious.
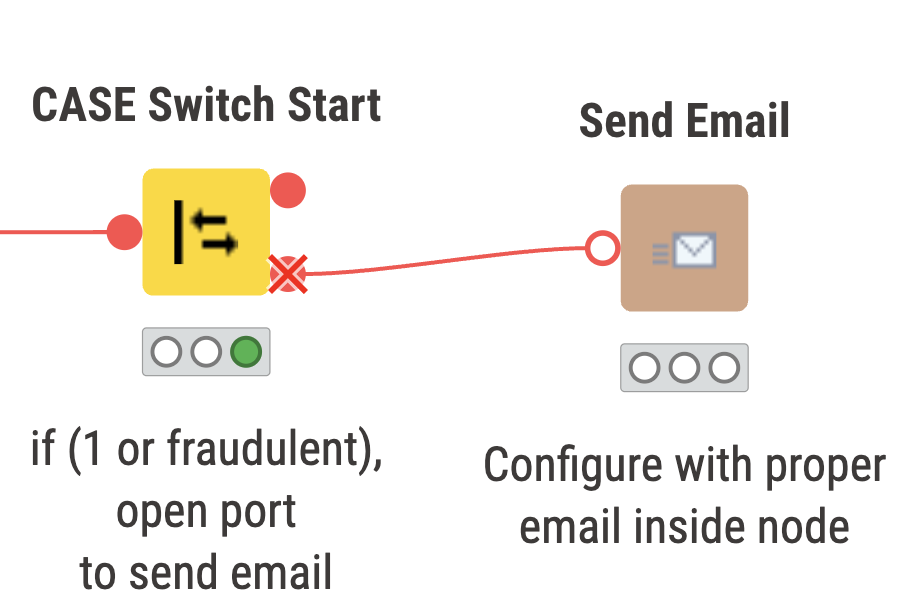
This adjustment in the threshold helps us find a balance between catching frauds and reducing false positives. The new transaction is classified as ‘not fraudulent’ or ‘good’, so our switch statement closes the port to the email.
Below, are two snippets of what can be expected to occur depending on the classification of the transaction. Here, we have a non fraudulent transaction. The port remains closed so that no notification email is sent.
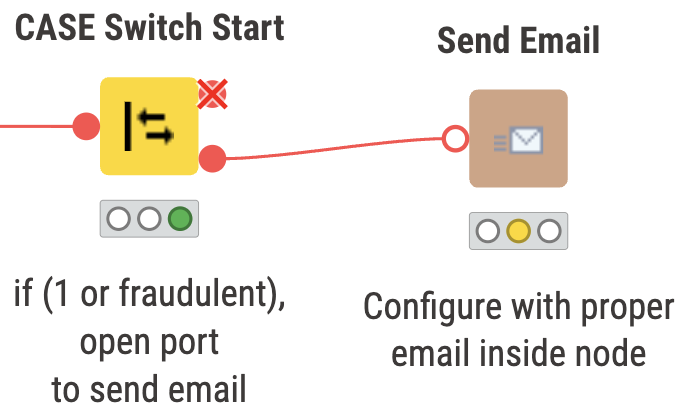
And here, the port opens up if the transaction is fraudulent or ‘1’.
KNIME for Finance: Early fraud detection
In helping to detect credit card fraud, KNIME Analytics Platform provides a solution using a low-code, visual, and intuitive user interface. We could schedule the deployment workflow to run on intake of any new transactions at a specific time of day - or if we wanted to check only large transactions, we could run the deployment workflow as is and have it check on any new transaction passed in for classification.
Download KNIME and explore more finance solutions in KNIME for Finance.