
Author: Julien Grossmann, Political and Violent Risk Data Analyst, HIS Economic and Country Risk
I’ve been using KNIME Analytics Platform for a year and a half, and in this time, KNIME has become a vital part of my work. As a political and violent risks data scientist, I am often confronted with incomplete or badly structured data. But with KNIME, I can always find ways to efficiently clean up, organize and analyze my data, and this, despite a total lack of programming or coding knowledge.
One of the most frustrating aspects of working with unstructured or semi structured data, is that they are rarely ready made for your needs. Therefore, they always require extensive manual clean up.
Worse, if your needs are constantly shifting, the data restructuration and clean up are too.
For instance, the typical data I work with involve datasets of events (such as civil unrest or terrorism attacks). Most data sets have basic meta data like date, location, and a short description of the incident, but there is only so much you can conclude from such basic dataset. Often I need to drill down, and look for specific groups, or specific actions or targets.
In the old days, we would use basic search functions in excel, or for the less geeky of us, we would do it manually.
So I decided to create a little workflow using the KNIME Textprocessing extension. The idea was to be able to mine large datasets rapidly, using a customizable list of keywords.
The solution had to be flexible (both in term of inputs, and in terms of the metadata to be created). As each analyst has different issues and questions to address, they will want to query the datasets from different angles (groups, attacks type, weapons type and targets type).
In addition, the solution had to be easy to use as most analysts have very limited experience with KNIME.
To illustrate how the workflow works I used a sample from the Rand terrorism database and a sample of the ACLED dataset on violent events in Africa.
Although full of very useful information, these datasets do not necessarily have the metadata we needed for our analysis. For instance, terrorist groups involved are not always stored in a separate field, nor are the type of attacks. Luckily, both datasets have a description field, which summarizes events like this:
“A powerful bomb destroyed a bridge in Khost. Officials suspect the Taliban or Al Qaeda members. No further information is provided.”
Using these description fields, I can then assign a theme based on a list of keywords structured like this:
Grouping keywords in concepts allow users to tag multiple concepts at once.
Breaking down the workflow
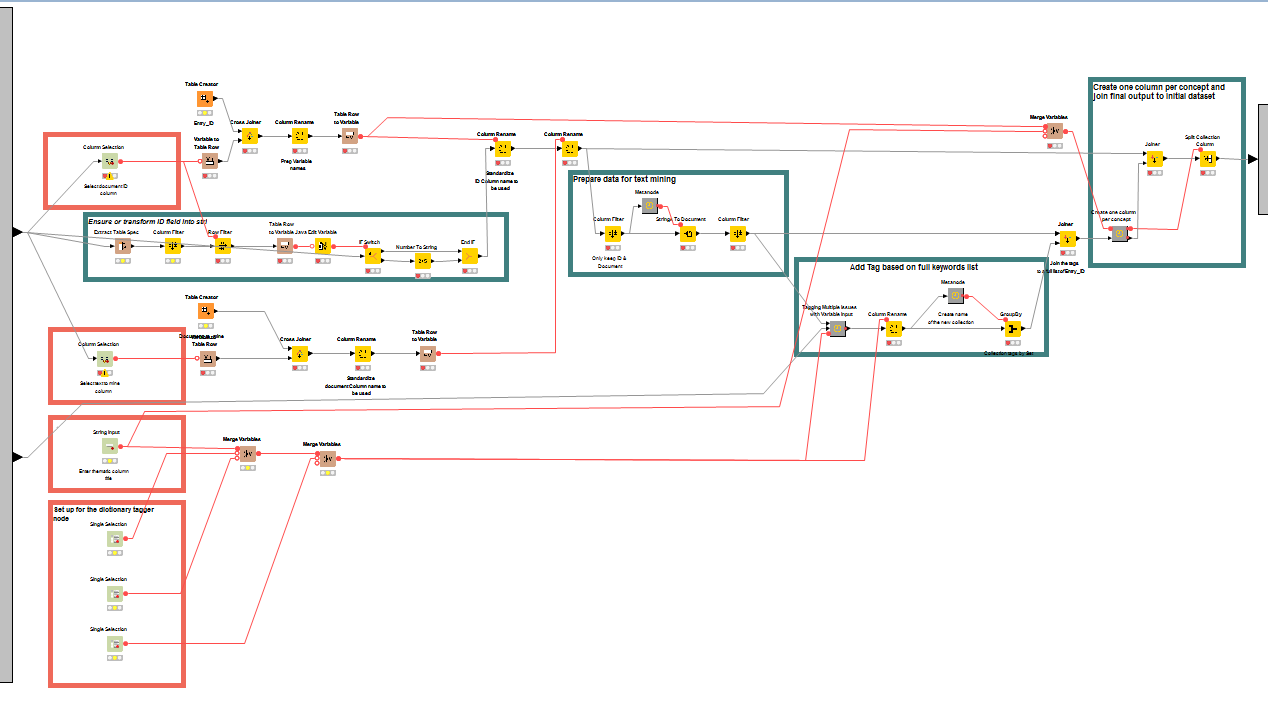
Because of the ease of use requirement, I created a series of Quickforms to allow the user to configure the tagging process (input to mine, tagging properties...).
Quickforms
(click on the image to see it in full size)
The two column selection Quickform nodes are used to identify the two necessary fields for the tagging process (namely the entry ID number, which will be used in the string to document node as the category, and the field to mine). For the ID field, I introduced an intermediary step to ensure the entity ID data type is string (the string to document node doesn't allow numbers for categories).
I also added an input Quickform to allow user to assign a theme to the tagging process (i.e. if the user tags groups he can assign a "group" theme). This is particularly useful if the user uses multiple tagging processes (one for groups, another for attack type...) one after the other. In the final output the column name will appear as "Theme+Concept" which allows for easier regex manipulation.
Finally, I used three single selection nodes to configure the dictionary tagger node.
Tagging
Before looking at the tagging process, let’s have a closer look at the Java Edit Variable node. This is a necessary step in order to transform the initial variable created by the Quickforms into a TRUE/FALSE variable, which is needed for the dictionary tagger node.
Thanks to Ferry Abt from KNIME for his help with this part of the workflow. This is a piece of code worth keeping in mind as it can come in handy in quite a few situations.
(click on the image to see it in full size)
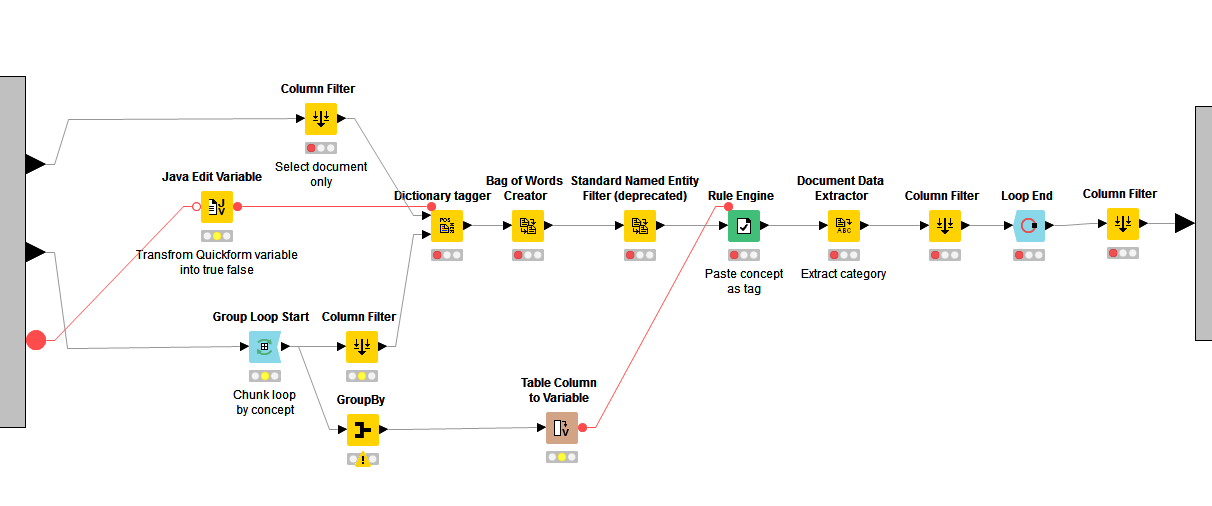
The tagging sub process is very straight forward:
- Dictionary tagger: this node is fully configured through the variables set in the Quickforms.
- Bag-of-words creator: to extract all terms (including our keywords)
- Standard Named Entity: to keep only triggered keywords
- Rule Engine: to create a new column and pastes the relevant thematic
- Document Data Extractor: to retrieve the Entry_ID
- Column filter: keep only the Entry_ID and Thematic column
Now because, I wanted to tag multiple concepts at the same time, the tagging input in the dictionary tagger node had to be split by concept. To do that, I used the Group loop node.
- Column filter: to keep the keyword column and send it to the dictionary tagger
- GroupBy: to keep the concept and inject it as a variable to the rule engine column
At the end of the loop, all the new tags created were concatenated into a Set using the GroupBy node.
Once the tagging was done, we added the theme (selected by user in the Quickform) to the collection column containing all the tags generated.
The final stages involved taking the collection of tags created and transposing them into dedicated columns.
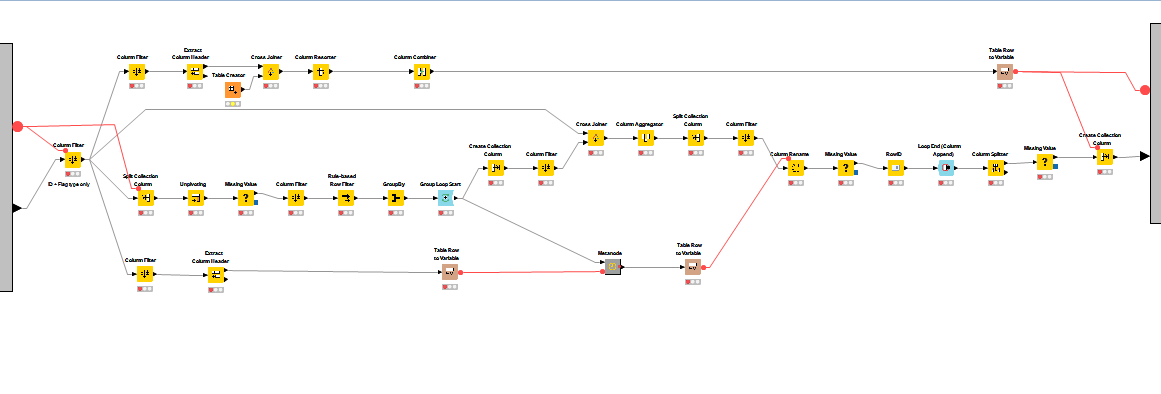
(click on the image to see it in full size)
Because I created a set collection for our tags using the GroupBy node, splitting the collection will result in unstructured output that looks like this:
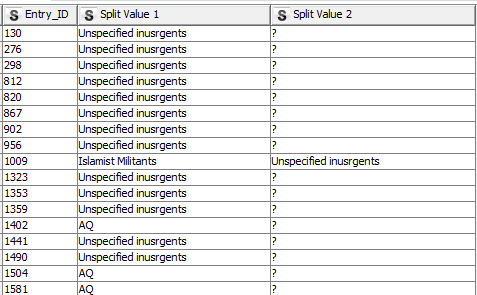
The short workflow above takes these unstructured tags and drops them into a dedicated column. The final output looks like this:
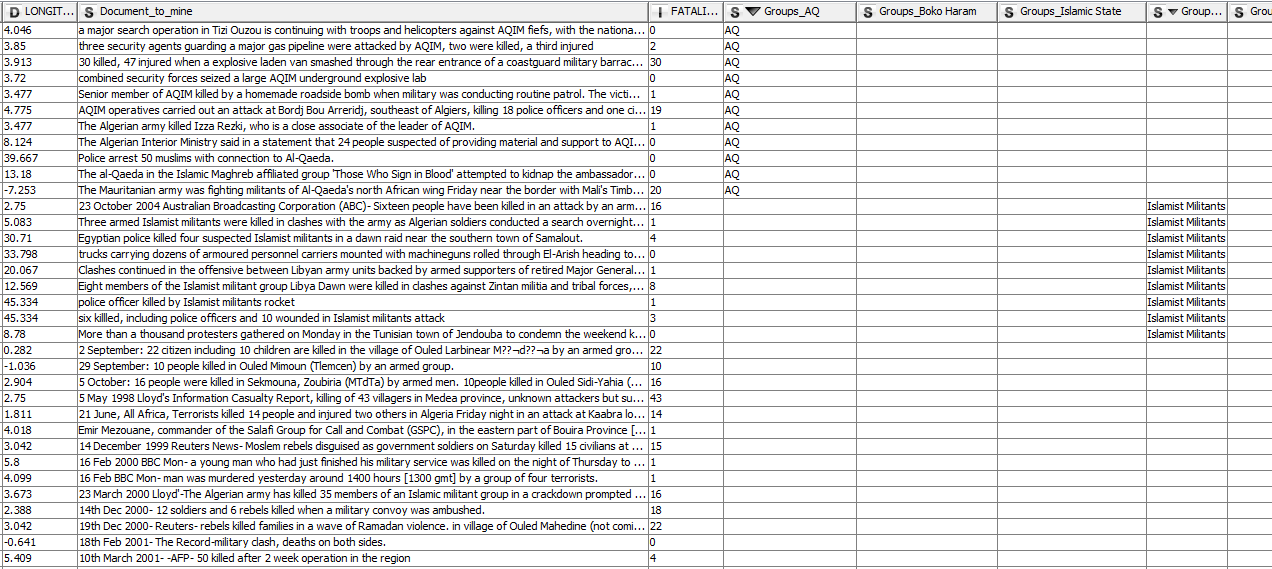
(click on the image to see it in full size)
Conclusion
More advanced users will probably find ways to make this workflow more efficient and streamlined, but for newcomers to KNIME, it shows that you can easily build somewhat complex workflows without any coding or programming skills.
The workflow simply mimics the logic I wanted to create with small steps and processes (filter one column, inject its name as variable…). Then with various iterations I improved it and added functionalities (such as the Quickforms).
It also illustrates how useful KNIME can be for social scientists. In this example, I showed how to tag data in a table format, but the process can be easily adapted to mine large text documents such as PDF. And because the tagging list is fully customizable by the user, the process can save hours of research by simply identifying documents of interests by mining their contents.
Finally, this workflow is a good example of how a somewhat experienced KNIME user can help introduce the platform to a wider audience of potential users. A lot of social scientists have a difficult relationship with technology. They use computers every day, but often stick to their web browser, Word, PowerPoint, and, for the most adventurous, Excel.
Creating out-of-the-box, easy-to-use processes is one way of drawing more of them to the beautiful world of advanced analytics.