
Semantic search techniques with unstructured data are becoming more and more common in most search engines. In this article, we show you how to build a KNIME workflow for semantic keyword search. The insight output by the workflow will enable you to craft webpage texts for better search rankings for a given search query. You can download the workflow that extracts this information from the KNIME Hub: Search Engine Optimization (SEO) with Verified Components.
But first: What is a semantic keyword search?
In the context of search engine optimization (SEO), a semantic keyword search aims to find the most relevant keywords for a given search query. Keywords can be frequently occurring single words, as well as words considered in context, like co-occurring words or synonyms of the current keywords. Modern search engines, like Google and Bing, can perform semantic searches, incorporating some understanding of natural language and of how keywords relate to each other for better search results.

As Paul Shapiro explains in Semantic Keyword Research with KNIME and Social Media Data Mining, a semantic search can be carried out in two ways: with structured or unstructured data.
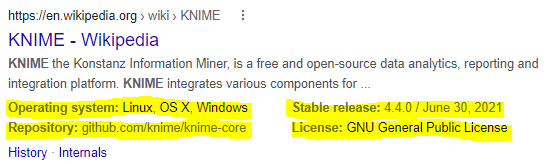
A structured semantic search takes advantage of the schema markup — the semantic vocabulary provided by the user and incorporated in the form of metadata in the HTML of a website. Such metadata will be displayed in the Search Engine Results Page (SERP). In figure 2 you can see an example snippet of a SERP as returned by Google. Notice how it shows the operating system support, the latest stable release, the link to a Github repository, and other metadata from the found webpage. Creating metadata in HTML syntax can be done with schema.org, a collaborative work by Google, Bing, Yahoo, and Yandex, used to create appropriate semantic markups for websites. Relevant metadata helps to improve the webpage ranking in search engines.
Meanwhile, unstructured semantic searches use machine learning and natural language processing to analyze text in webpages for better SERP ranking. The more relevant the text to the search, the higher the web position in the SERP list.
While structured searches on metadata are present in all search engines, techniques with unstructured data are now also becoming more common. There are two places where searches happen: search engines (of course) and social media. We want to explore the results of search queries on SERP and social media, and learn from the text in the top-performing pages.
Search by scraping text from Search Engine Results Page (SERP)
Up until 2013, search engines like Google used to check the frequency of words in webpages to figure out their relevance. This led people to add random keywords to either the markup or the webpage text to improve their ranks in Google Search. In 2013, Google Search introduced the Hummingbird algorithm. This algorithm tries to understand a user's intent in real time. For instance, if a user writes “beer” in the search box, the intent is not that clear. Is the user seeking to buy beer, looking for a beer shop, looking for beer preparation details, or something else? So search engines will show all possible results concerning “beer.” However, if a person writes “beer bar,” the engine will show listings for nearby pubs, restaurants, cafes, etc. In the latter query, Google understood the user's intent better. Hence this algorithm also displays Google Map results on SERP.
With the Hummingbird algorithm, multiple topics and the relevant keywords are associated with the search query. Thus the webpages ranking at the top in SERP contain such keywords and such topics. If we want our webpage to perform better with SEO, we might learn from the top-ranking pages how to shape our text, for example which single keywords and which pairs of words to use. The right collection of keywords from similar websites can help tremendously with the page ranking in search results.
In this article, we will pay particular attention to texts in top ranking pages for a given search query, with the goal to extract meaningful keywords and key pairs of words.
Search by scraping text from links on social media
While scraping text from SERP may be one way to extract keywords, scraping text from links on social media might be a secondary source. Opinions and ideas shared by users on these networks really help expand one’s horizon for collecting the right keywords. In the context of digital marketing, social media conversations are used to engage with visitors to make them stay on a website or to get them to perform an action — for example, getting a visitor on an ecommerce website to make a purchase. This can be optimized by improving the conversion rate measure (in this example, the number of visitors divided by number of purchases made). This is called conversion rate optimization (CRO).
Social media activities often use webpage links for calls to action, and they are heavily optimized on conversion rate. Therefore, analyzing social media text and the text of linked webpages can help in the process of keyword extraction, especially those keywords most “appealing” to visitors.
Three techniques we used to extract keywords
Based on the previous observations, we built an application which would perform a search query on a web search engine (Google) and a social media platform (Twitter), scrape the texts from the links appearing in SERP and tweets, and finally extract the keywords.
We used three different keyword extraction techniques:
- Term co-occurrences — the most frequently occurring pairs of words are extracted.
- Latent Dirichlet Allocation (LDA) — an algorithm which clusters documents in a corpus into topics, with each topic described by the set of relevant associated keywords.
- Term Frequency - Inverse Document Frequency (TF-IDF) — the importance of a single keyword in a document is measured by the term frequency (TF), and the importance of the same keyword within the corpus is measured by the inverse document frequency (IDF). The product of those metrics (TF-IDF) gives a good compromise of how relevant the word is to identify the document and only that document within the corpus. The highest TF-IDF-ranking words are then extracted.
How we implemented our keyword search application for SEO
Our “Keyword Search Application” consists of four steps:
- Run search queries on search engines and social media, and extract the links to the top-ranking webpages.
- Scrape text from the identified top-ranking webpages.
- Extract keywords from the scraped texts.
- Summarize the resulting keywords in a data app.
Step 1: URL Extraction
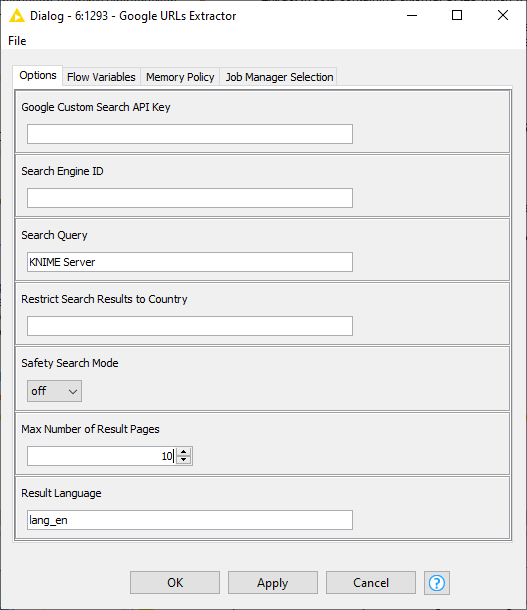
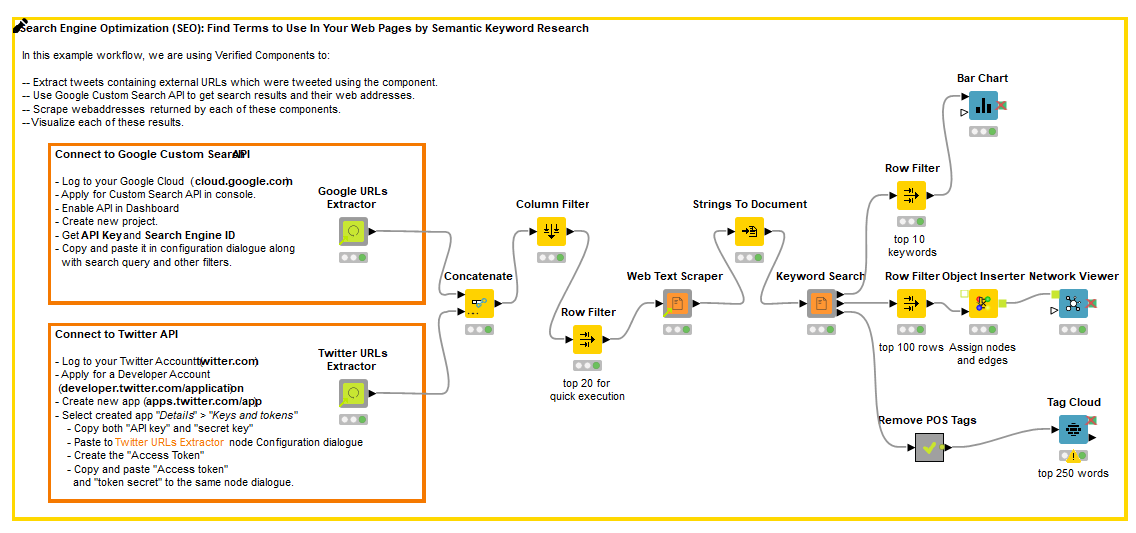
The first step consists of extracting the URL for the top-ranking pages around a given hashtag or keyword. For this step, we created two very useful verified components: Google URLs Extractor and Twitter URLs Extractor (Fig. 3).

Step 2: From Google SERP and From Tweets
From Google SERP
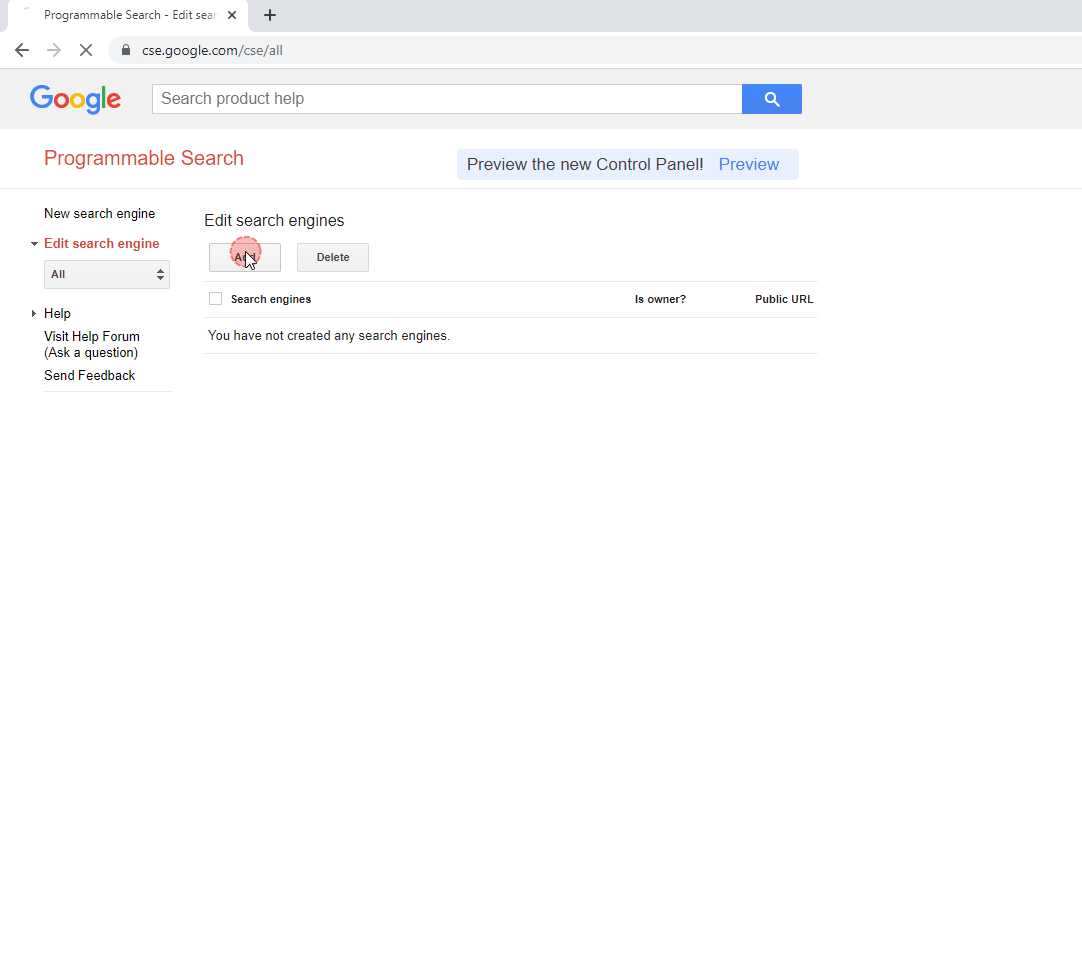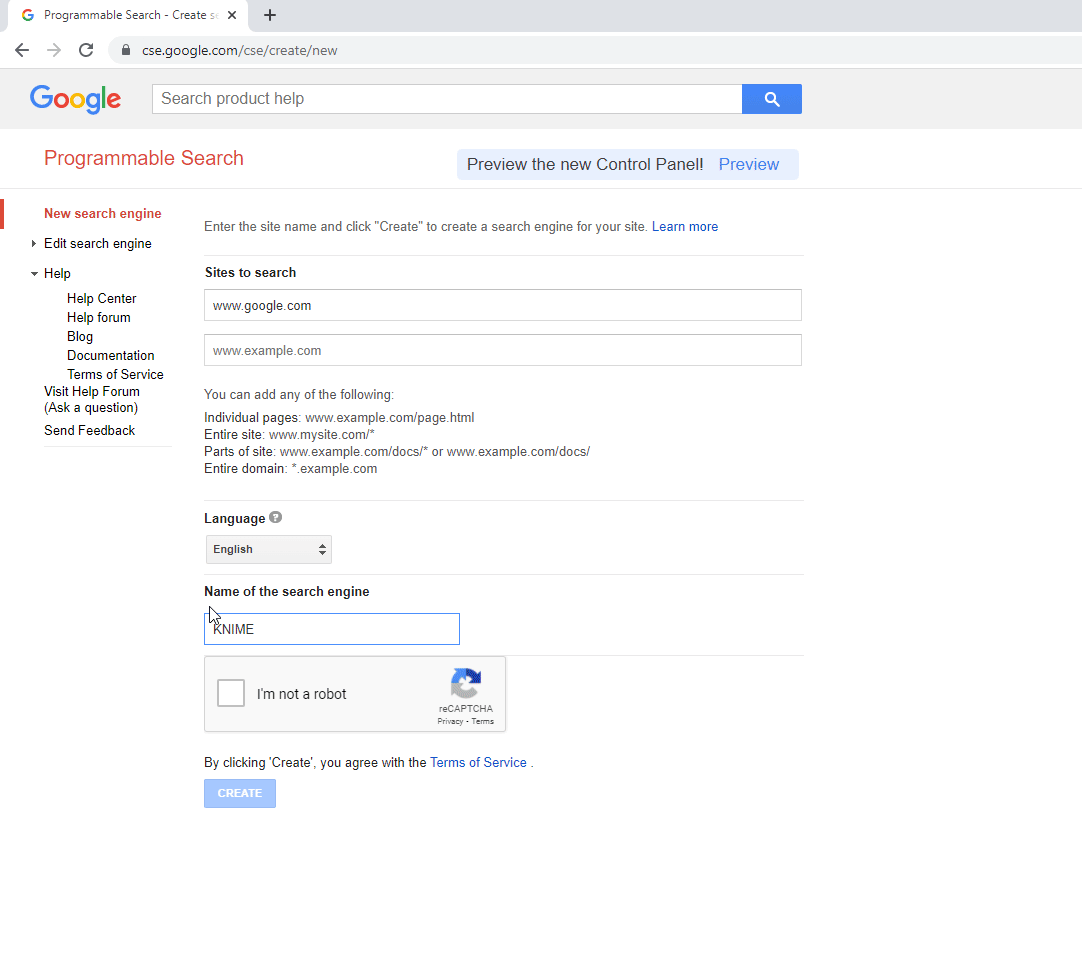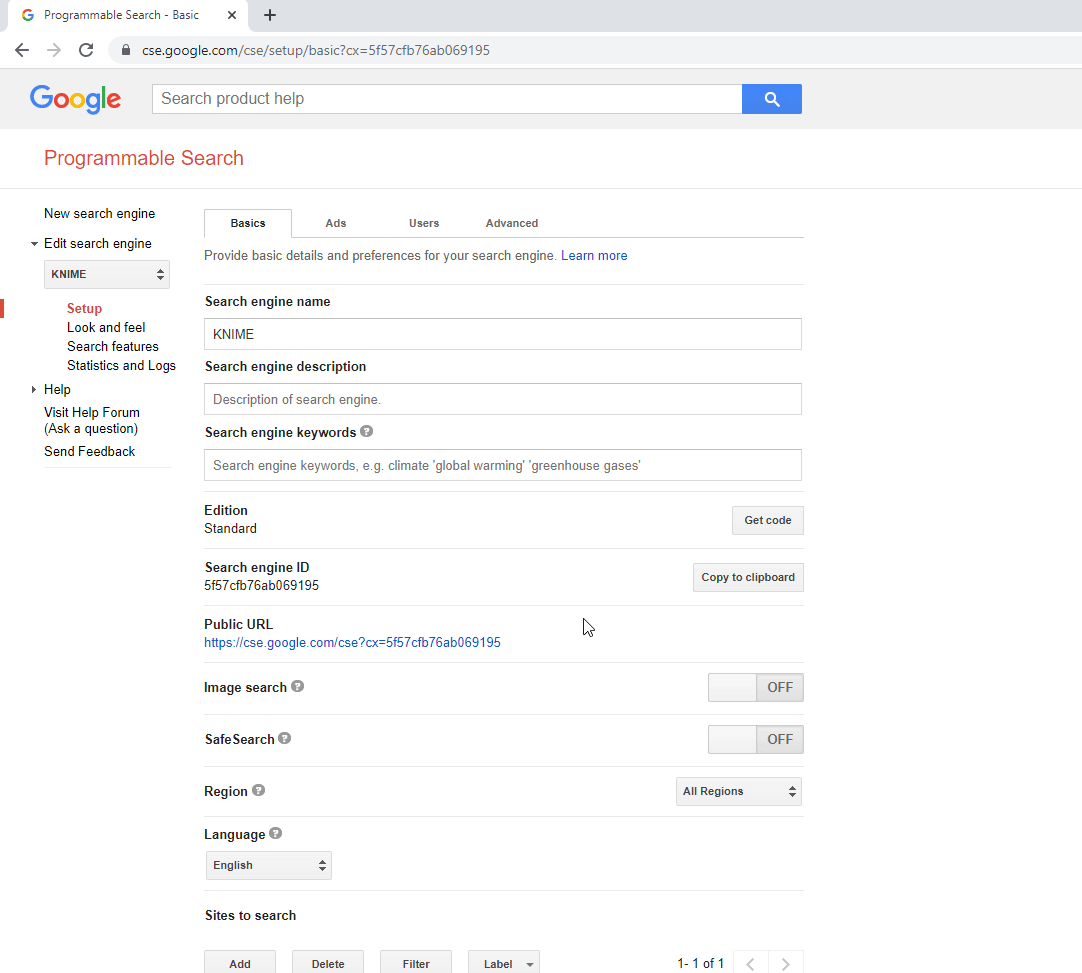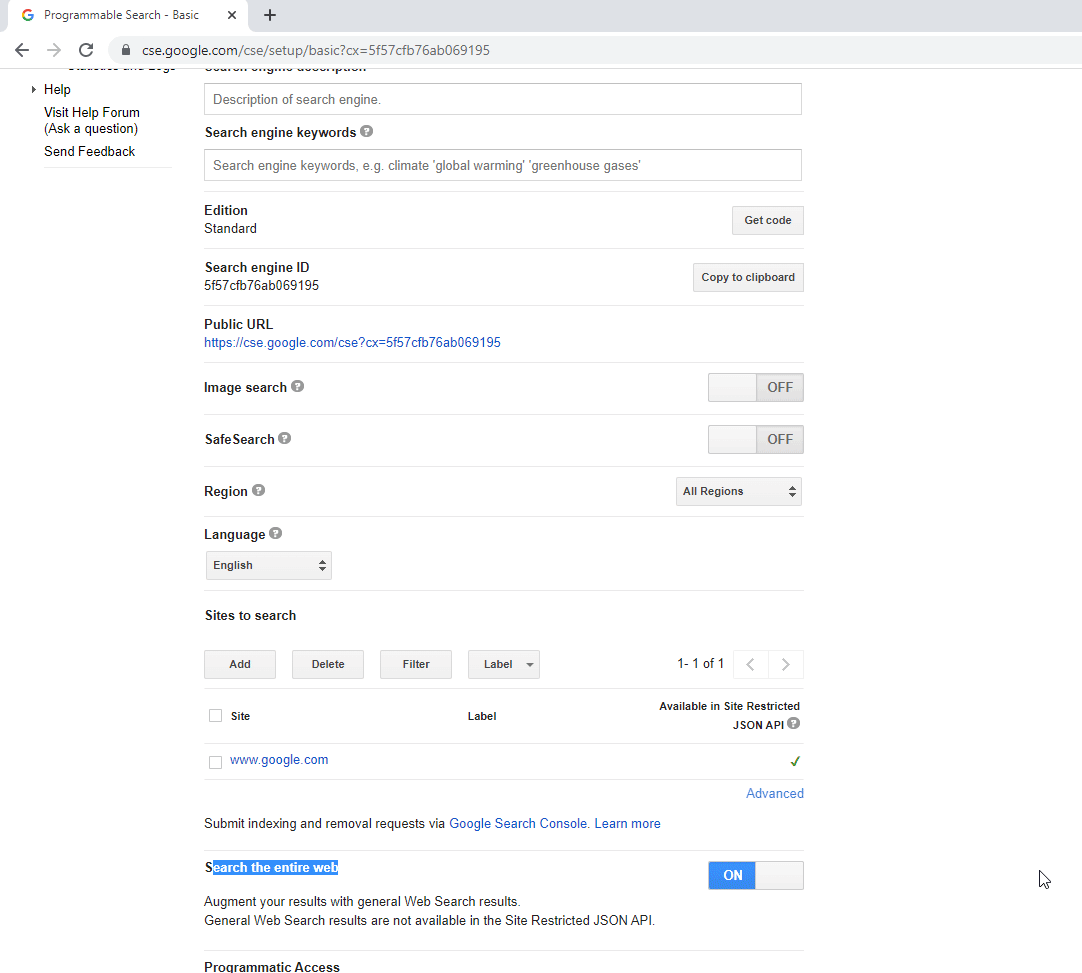
The Google URLs Extractor component performs a search on Google Custom Search Engine (CSE) via a web service. It sends a Google API key, the search query, and the engine ID, and receives in return a maximum number of SERPs in JSON format. From this JSON response, the component extracts the web links for all found pages and returns them together with text snippets, SERP title, and status code. The Google search can be refined through some extra configuration settings of the components: a specific language or location for the search result pages (Fig. 4).
Just like there is no free lunch 😏, Google just provides the refreshments but not the main meal. The free version of Google Custom Search Engine (CSE) web service can return only 10 SERPs on consecutive calls, which means a maximum of 100 search results. A premium CSE web service obviously solves this problem.
To create the Google API key and the search engine ID, refer to the Google Custom Search JSON API documentation page or the Google Cloud Console.
To begin, you will need the API key, which is a way to identify the Google client. This key can be obtained from this page. If this link doesn’t work, then a similar key can be created in Google Cloud Console. Next, the authentication parameter needed is Search Engine ID, a search engine created by a user with certain settings. Fig. 5 shows how it can be obtained.
From Tweets
Here we used the Twitter URLs Extractor component. This component extracts tweets from Twitter around a given search query and then extracts the URLs in them. We could have also chosen to consume Facebook, LinkedIn, or any other social media site. We used Twitter because of the easier access it provides to its content.
In case you are wondering why we opted for the URLs and not the main text bodies of the tweets, we personally believe that relying on text from linked URLs should provide more information than what is contained in a simple short tweet.
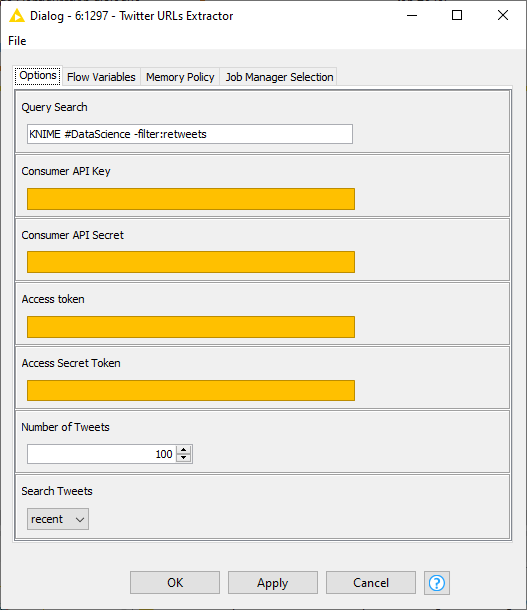
To run the component, you need a Twitter Developer account and the associated access parameters (Fig. 6). You can get all of that from the Twitter Developer Portal.
Additional search filters to apply in the query, like filtering out retweets or hashtags, are described in the Twitter Search Operator documentation page. The component’s output includes the URLs, tweet, tweet ID, user, username, and user ID.
Step 3: Scraping Text from URLs
With the URLs from both SERP and tweets, the application must proceed with scraping their texts to get the corpus for keyword extraction. For this step, we have another verified component, “Web Text Scraper” (Fig. 7). This component connects to an external web library — “BoilerPipe” — to extract the text from the input URL. It then filters out unneeded HTML tags and boilerplate text. (Headers, menus, navigation blocks, span texts, all the unneeded content outside the core text.)
The details about algorithms used in Boilerpipe and its performance optimization are mentioned in the research paper “Boilerplate Detection using Shallow Text Features.”
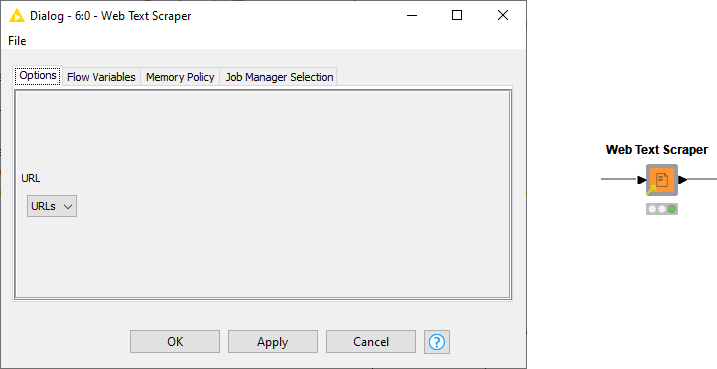
This component takes a column of URLs as input and produces a column with the texts in String format as output. Only valid HTML content is supported — all other associated scripts are skipped. With long lists of URLs to be crawled, this component can become slow, because identifying the boilerplates for each URL is time-consuming.
Step 4: Summarize results in a data app
Keyword Search Component
Once the document corpus has been created, the application converts it into Document format using the “Strings To Document” node. The resulting Document column becomes the input for the Keyword Search component. This component implements the three techniques described previously (term co-occurrence, topic extraction using LDA, and TF-DIF) to extract the keywords.
Fig. 8 shows the configuration dialog of the “Keyword Search” component. This includes the selection of the Document column, a few parameters for the LDA algorithm (i.e. the number of topics and keywords, along with the Alpha and Beta parameter values), the IDF measure for the TF-IDF approach, and a flag to enable default text processing. For further understanding of Topic Extraction using LDA, please read “Topic Extraction: Optimizing the Number of Topics with the Elbow Method.”
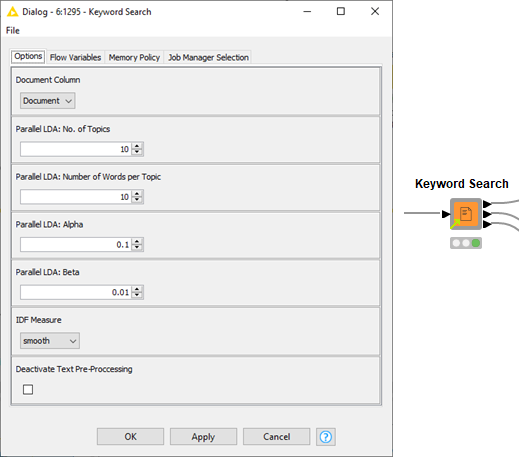
This component has three outputs:
- Terms (nouns, adjectives, and verbs) along with their weights as produced by the LDA algorithm.
- Terms (nouns, adjectives, and verbs) of co-occurring pairs, along with the occurrence counts.
- Top tagged terms (nouns, adjectives, and verbs) with the highest TF-IDF values.
Each of these output tables are sorted in descending order according to their respective weights/ frequencies/values.
For our last step, these outputs have been visualized:
- Top 10 LDA with a bar chart.
- Co-occurring terms with a network graph, where each node is a term and the counts of documents are the edges.
- Top terms identified by the highest TF-IDF values with a Tag Cloud, where the word size is defined by the maximum TF-IDF value for each term.
The complete workflow, “Search Engine Optimization (SEO) with Verified Components,” incorporating all four components, is available on the KNIME Hub (Fig 9).
An example: Querying for documents around “Data Science”
As an example, let’s query Google and Twitter about the term “Data Science.” The keywords — alone or in combination — extracted from the top-ranking pages extracted from both SERP and tweets lead to the charts and maps reported in Fig. 10, 11, and 12. Let’s see what those keywords are and how they relate to each other.
Keywords from LDA
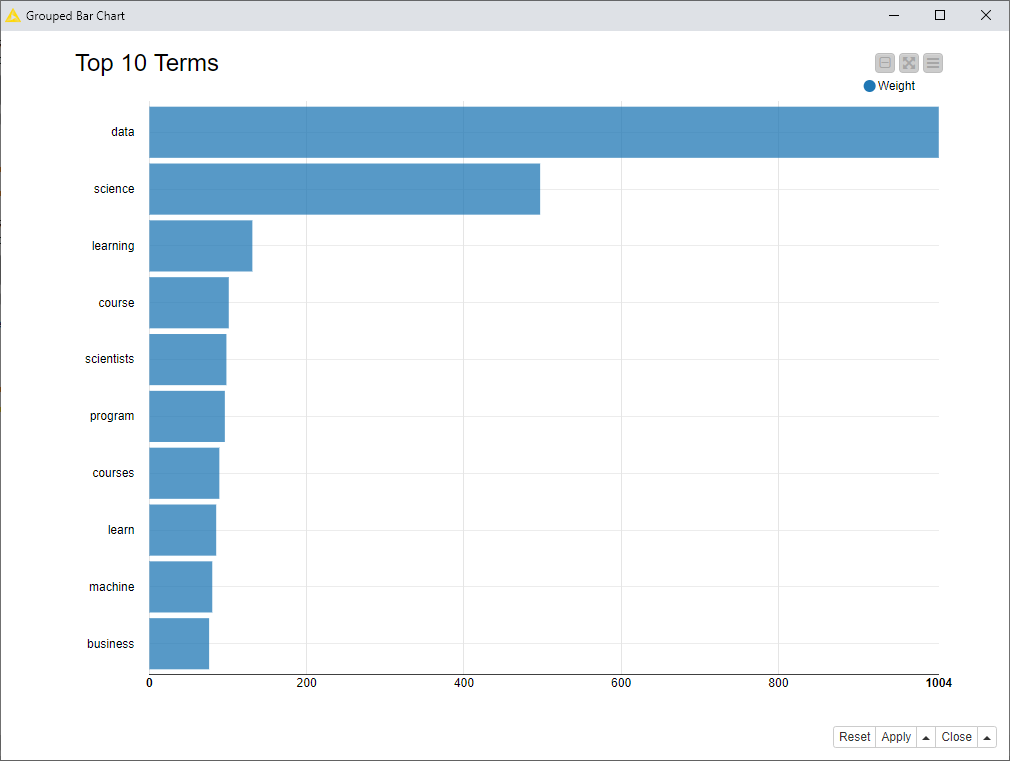
The top 10 topic-related keywords, sorted by their LDA weight, are reported in Figure 10. The words “data” and “science” have the highest weightage, which makes sense, but is also obvious. The next highly meaningful keywords are “machine” and “learning,” followed by “course.” The reference to “machine learning” is clear, while “course” is probably due to the recent blossoming of educational material on this subject. Adding a reference to machine learning and a course or two to your data science page might improve its ranking.
Co-Occurring Keywords
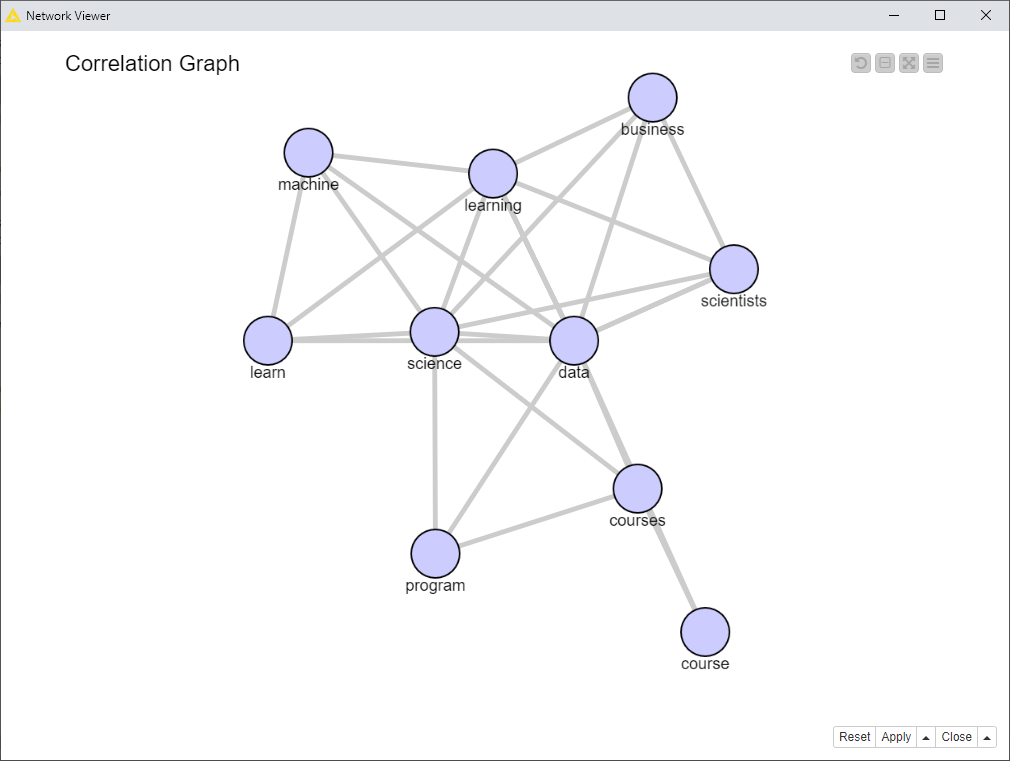
However, in the network graph (Fig. 11), we observe a different set of keywords. “Data” and “science” still represent the core of the keyword set, as they are located at the center of the graph and have the highest degree. “Machine” and “learning” are also present again, and this time we learn that they are connected to each other. In the same way, “program” is connected to “courses,” as those words are often found together in highly ranked pages about “data science.”
We can learn as much from this graph about the words that don’t occur together. For example, “program” is only co-occurring with “science” and “courses,” while “skills” and “course” only co-occurs with “data” and not with “science,” “machine,” “learning,” or “business.” It thus becomes clear which pairs of words you should include in your data science page.
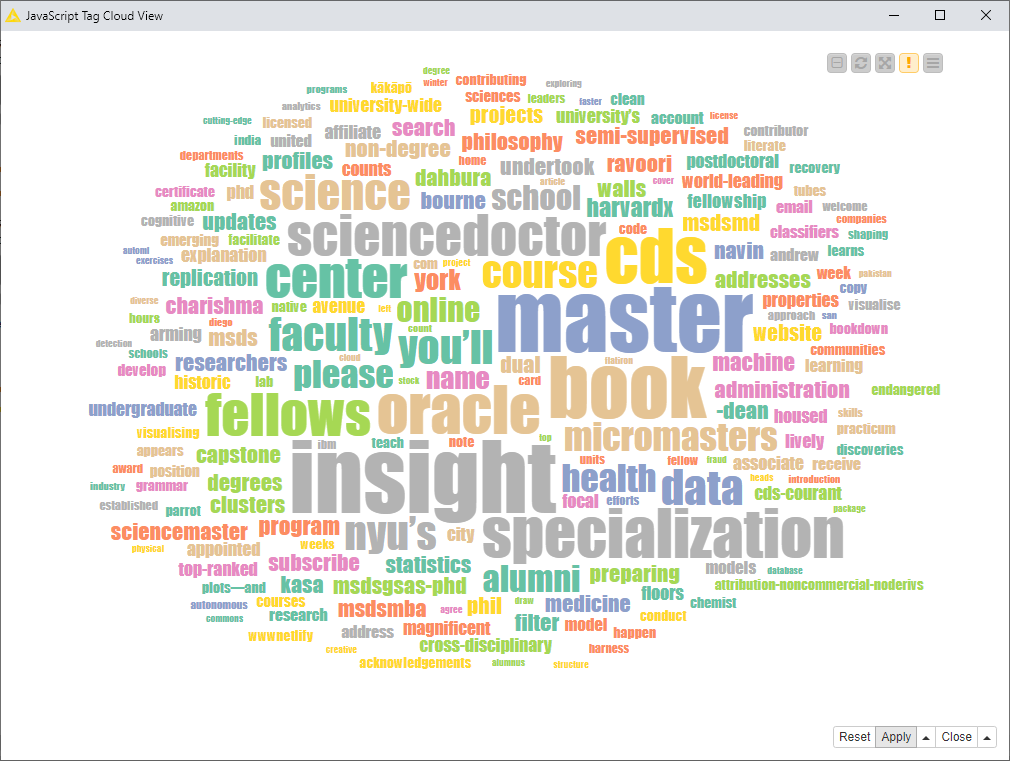
Keywords from a Word Cloud
Lastly, if we look at single keywords in the Tag Cloud (Fig. 12), we can see that the terms “master,” “insight,” “book,” and “specialization” appear most prominently. This makes sense, since the web contains a large number of offers for specialization courses with universities, online platforms, and books. In the word cloud, you can also see the names of institutes, publishers, and universities offering such learning options. Only on a second instance do you see the words “data,” “science,” “machine,” “learning,” “philosophy,” “model,” and so on.
Single keywords seem to better describe one aspect of the “data science” community, i.e. teaching, while co-occurring keywords and topics best extract the content of “data science” discipline.
Notice that the multifaceted approach to visualizing keywords that we have adopted in this project allows for an exploration of the results from different perspectives.
Conclusion
In order to improve SEO by learning from the top-performing pages for a given search query, we have built a tool that can help you extract the most frequently used keywords, in pairs or in isolation, or from the top-ranking pages around a given search on whatever topic you choose.
The application identifies the URLs of top-performing tweets and pages in SERP, extracts texts from URLs, and extracts keywords from scraped texts via LDA algorithm, TF-IDF metric, and word pair co-occurrences.
You can download the workflow from KNIME Hub: Search Engine Optimization (SEO) with Verified Components. Of course, to make it run, you need to insert your own authentication credentials for the Google and Twitter accounts.
Note. The Machine Learning and Marketing space on the KNIME Hub contains example workflows of common data science problems in Marketing Analytics. The original task was explained in: F. Villarroel Ordenes & R. Silipo, “Machine learning for marketing on the KNIME Hub: The development of a live repository for marketing applications”, Journal of Business Research 137(1):393-410, DOI: 10.1016/j.jbusres.2021.08.036. Please cite this article, if you use any of the workflows in the repository.