Many organizations, especially in industries like finance and law, scan and store historical customer agreements, originally signed on paper, as image files in the cloud. These agreements often contain critical terms, provisions, and conditions for compliance, audits or decision-making. Manually extracting key details from these lengthy scanned documents is time-consuming, labour-intensive and error-prone, highlighting the need for streamlined and automated solutions.
This tutorial shows how you can build a visual workflow that automates the extraction and summarization of financial agreements using OCR (Optical Character Recognition) and GenAI in KNIME Analytics Platform. With this solution, you can generate concise, professional summaries from scanned documents, saving time and improving accuracy.
KNIME Analytics Platform is a data science tool where you use visual workflows to build your applications. It’s open source and free to use.
This blog series on Summarize with GenAI showcases a collection of KNIME workflows designed to access data from various sources (e.g., Box, Zendesk, Jira, Google Drive, etc.) and deliver concise, actionable summaries.
Here’s a 1-minute video that gives you a quick overview of the workflow. You can download the example workflow here, to follow along as we go through the tutorial.
Let's get started.
Summarize scanned financial agreements with a visual workflow
This solution aims to automate the summarization of scanned financial agreements stored as image files in the cloud. Using OCR technology and local LLMs within KNIME Analytics Platform, the workflow extracts key textual information and generates concise summaries. These are then compiled into a PDF report and stored on Box for easy access and sharing.
In this example, we will summarize a historical financial support agreement sourced from the UNT Digital Library. The document outlines Texas Human Rights Foundation’s commitment to support a litigant involved in a legal case.
We can do this in three steps:
- Access images of a scanned financial agreement by connecting to Box
- Extract text using OCR and summarize the document using a local LLM
- Compile the summaries into a static report and store it on Box
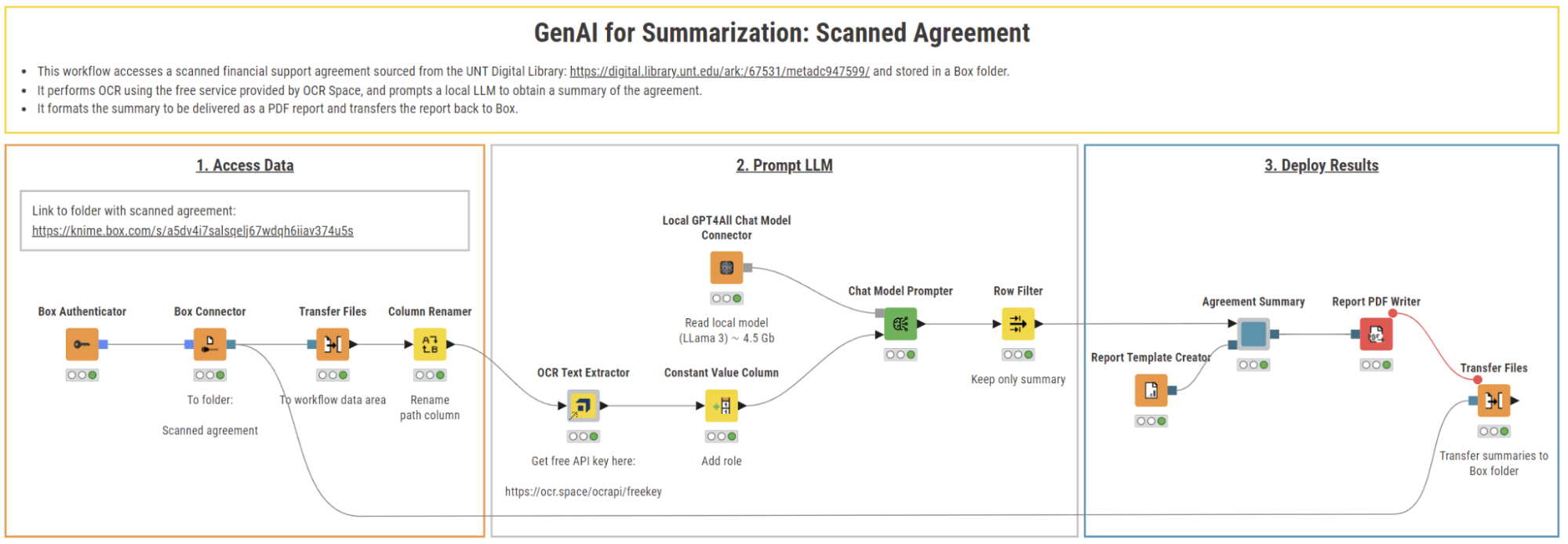
This workflow automates the summarization of scanned financial agreements using KNIME.
Step 1. Access data: Connect to Box to fetch scanned documents

In the first section of the workflow, the scanned financial agreement, stored in a Box folder, is accessed in KNIME Analytics Platform.
We begin by accessing the scanned financial support agreement stored on Box. To do this, we use the Box Authenticator node to authenticate to our Box account. Next, we use the Box Connector node to specify the directory containing the .png files, each file representing a page of the agreement.
To extract the textual content of the images, we first move the files from the original location to a new destination using the Transfer Files node. This node automatically adjusts its input port based on the source file system we connect to. In this example, we move the files from Box to the workflow data area for local processing.
Step 2. Prompt LLM: OCR texts and summarize with local Meta’s Llama-3
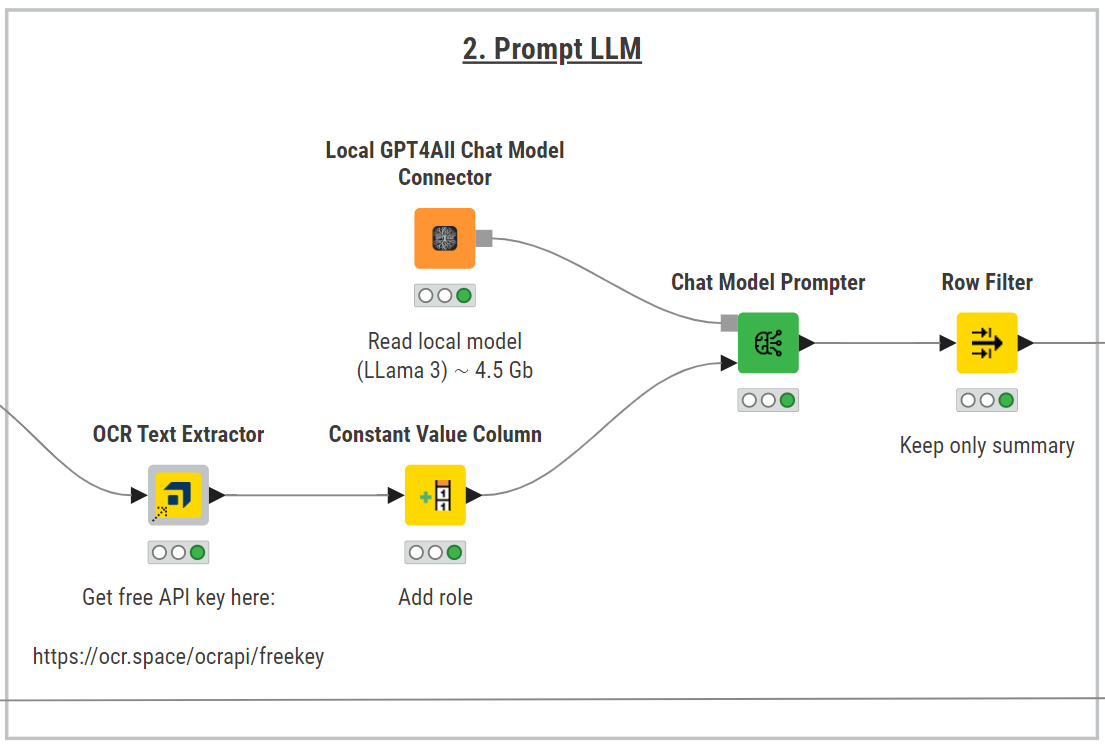
To summarize the financial agreement, we first need to extract the text from each image. To do that, a very convenient way is to use the OCR Text Extractor component, freely available on the KNIME Community Hub.
This component leverages OCR Space API, a service that offers both free and paid tiers depending on usage needs. For our use case, a free API key, easily obtained by registering on the OCR.Space website, is sufficient.
In the component configuration, we specify:
- The file path to the local .png files
- The OCR engine and language
- The API key and host URL
After configuration, the component processes each image and extracts the embedded text The results are added to a new column called “OCR_output” where each row corresponds to a page of the agreement and contains the extracted text as a string, making it ready for further processing by the LLM.
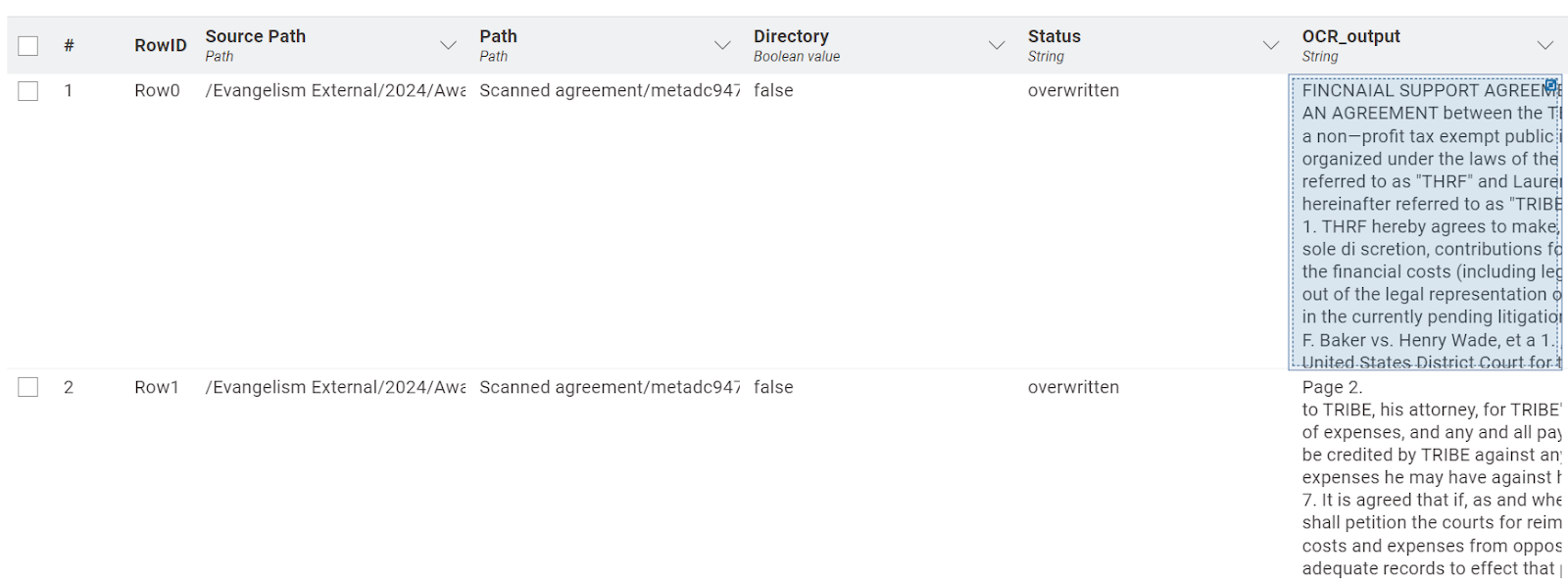
The output table of the OCR Text Extractor component.
To summarize the agreement text, we use KNIME’s AI extension and pick the best-fit LLM for the task, balancing costs, performance, and concerns over data privacy with sensitive documents. For example, Meta’s Llama-3, which is available for free via GPT4All and can run locally on our machine.
To establish the connection:
- Download Llama-3 from GPT4All
- Drag and drop the Local GPT4All Chat Model Connector node to specify the local directory where the model is stored, making it available for querying
To prompt Llama-3, we could use the LLM Prompter node. However, for our use case, it has a limitation. This node sends one prompt to the LLM and receives a corresponding response, for each row in the input table. That is, the node treats each row and the corresponding prompt independently from each other, as the LLM cannot remember the content of previous rows or how it responded to them.
Using this prompter node would result in the independent summary of each page, without any contextual continuity, instead of a comprehensive summary of the whole agreement at once.
Therefore, we define a different strategy, relying on the Chat Model Prompter. We won’t use the node to actually chat with Llama-3. Rather, we’ll take advantage of the node configuration and capabilities to feed all the agreement pages as context and obtain an overall summary.
This node prompts a chat model using the provided user message, with an existing conversation history as context. That is, for each prompt, the node generates a response with knowledge of previous interactions between the human and AI.
Practically, this means that:
- In the “Conversation settings”, set the “Messages column” to the OCR_output. This feeds all pages of the agreement into the chat history.
- In the “Message roles column”, define the roles in the interaction (human or AI). To do that, use the Constant Value Column node to add a column named “Role” with the value "AI", marking the OCR-extracted text as generated by the model.
Note: Why assign the “AI” role to the extracted text? In this setup, we treat the OCR output as if it’s already part of the conversation history (from AI). The user prompt, typed in the “New message” field, is then used to ask for a comprehensive summary of the agreement. This setup enables the model to “remember” the full document while generating its response.
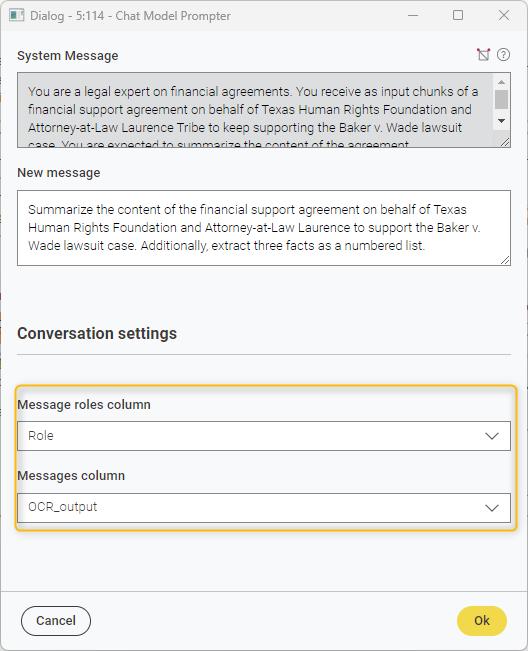
The configuration window of the Chat Model Prompter, where the columns containing the conversation history and roles are selected.
The Chat Model Prompter node is then configured with the following prompts:
- New message: it provides direct instructions for the final summarization:
“Summarize the content of the financial support agreement on behalf of Texas Human Rights Foundation and Attorney-at-Law Laurence to support the Baker v. Wade lawsuit case. Additionally, extract three facts as a numbered list.”
- System Message: it is similar to a prompt but it’s typically the first message given to the model describing how it should behave, assigning it a persona and clarifying the task (see best practices for prompt engineering):
“You are a legal expert on financial agreements. You receive as input chunks of a financial support agreement on behalf of Texas Human Rights Foundation and Attorney-at-Law Laurence Tribe to keep supporting the Baker v. Wade lawsuit case. You are expected to summarize the content of the agreement.”
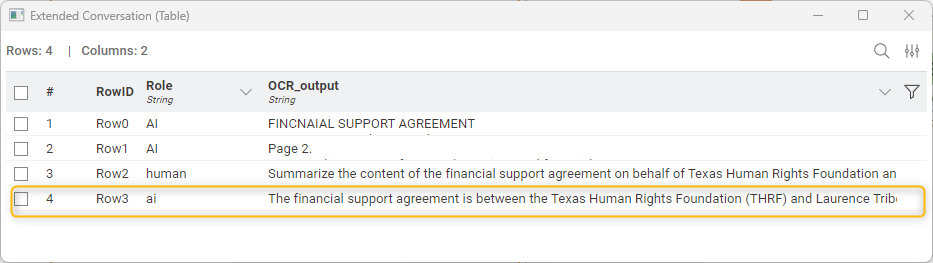
The Chat Model Prompter outputs a new row with the summary and “AI” as the source of it.
Finally, the Row Filter node is applied to retain only the AI-generated summary of the financial document, ensuring a clean and focused output.
Step 3. Deploy results: Create a PDF report and store in on Box
With the agreement fully summarized, the final stage involves compiling the summary into a report and storing it on the cloud.
To create a static and properly formatted PDF report, we use the KNIME Reporting Extension.
The Report Template Creator node is used to define the page size and orientation of the final report. In the “Agreement Summary” component, we post-process the LLM responses and display the summary using the Table View. We also design the layout of the report to include an introductory heading, ensuring the final output is both engaging and well-structured.
Once the report is finalized, we transfer it back to the same Box folder using the Transfer Files node, which takes as input the Box file system connection. This ensures the summarized report is automatically integrated into the existing document management system, enabling easy access and sharing.
The Result: A digitized, summarized agreement
The final output is a well-structured PDF report containing the summary of the financial agreement. The document is digitized, summarized, and ready for easy access or sharing, significantly reducing the manual effort required for processing scanned documents.
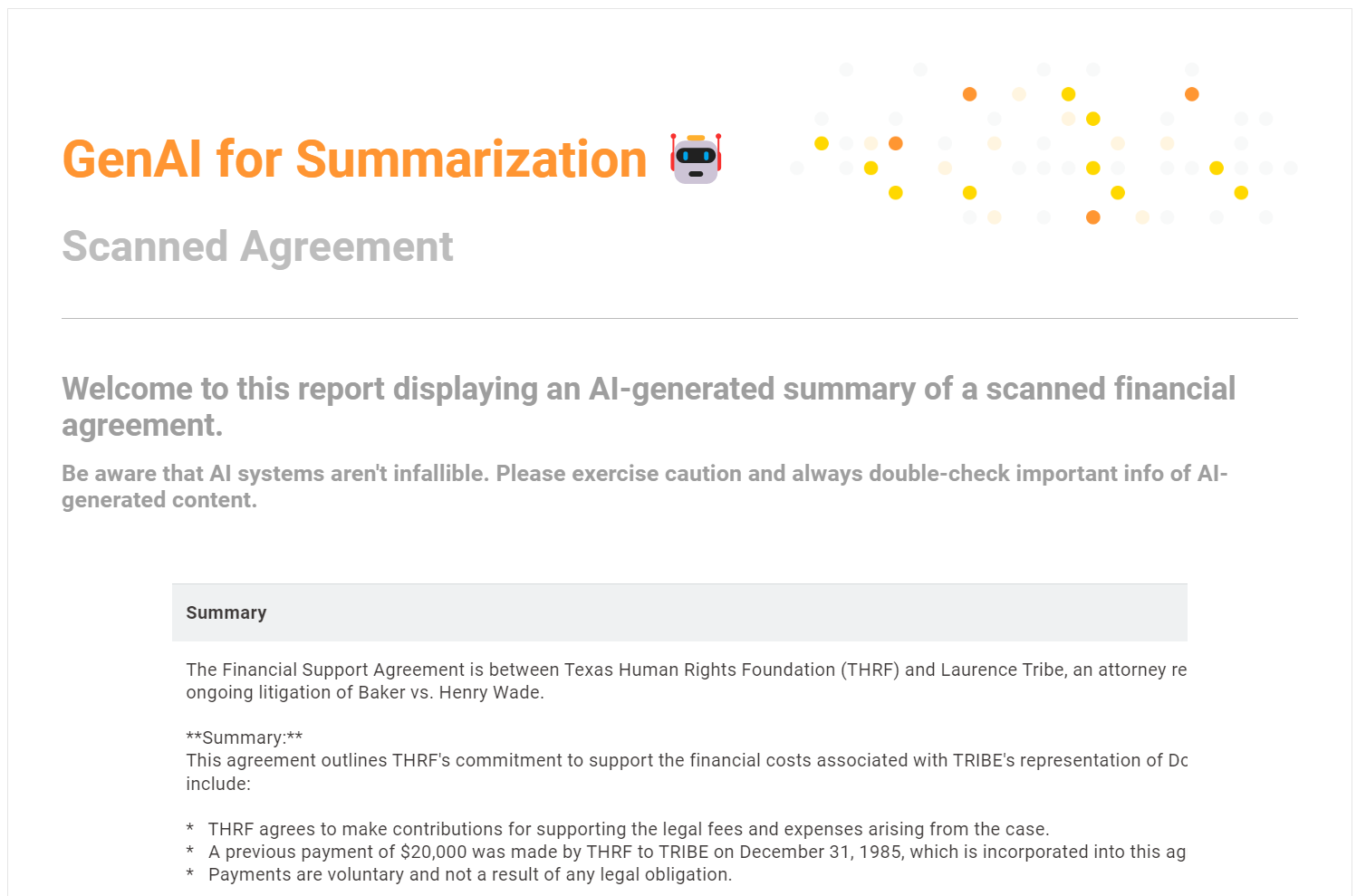
The final PDF report presents the summarized content of the financial agreement in a clean and professional format.
GenAI for summarization in KNIME
In this article from the Summarize with GenAI series, we explored how KNIME Analytics platform combined with OCR and GenAI can streamline the handling of financial documents, particularly scanned agreements as image files.
By automating key steps like text extraction, summarization, and report generation, this solution helps significantly reduce manual effort and increase efficiency and accuracy.
You learned how to:
- Access images of a scanned financial agreement by connecting to Box
- Extract text using OCR and leverage local LLMs with the KNIME AI exten
- sion to summarize the documents
- Compile the summaries into a static report and store it on Box
Download KNIME Analytics Platform and try out the workflow yourself!