
As first published in Business2Community.
Life in the lab is easy and comfortable. Data are balanced, descriptive, exhaustive. Machine learning models perform great on all classes. Life in the lab comes to an end with the arrival of “deployment” when the machine learning model is taken, incorporated into a deployment application, and moved into production to work on real-world data. Have you ever wondered what happens to an artificial intelligence (AI) model after it graduates from the lab?
The real world is scary. Data are put through unknown operations, oftentimes producing different results from those learned in the lab. But the scariest fact of all is that things in the real world change! They can change slowly without you even realizing it, or they can change abruptly from one day to the next because the underlying system is either currently changing or has already changed.
Slow Changes in the Outside World: Data Drift
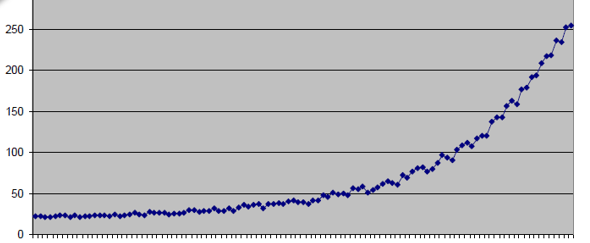
The world changes. Often slowly. Your customers also change. Your mechanical machines change too, slowly over time. Your machine learning models need to be prepared.
There are foreseeable changes, such as seasonal changes in customer preferences. These changes are predictable, and the data that describe them need to be part of the lab dataset used to train the model. If the training set has been designed adequately, such changes will have been metabolized by the machine learning model during the training phase. The model will have no problem predicting them or making the right predictions under changed conditions.
There are also unforeseeable changes. Or sometimes there are changes for which we see a trend, we can understand where the world is going, but we do not yet have enough data to describe them. Take increased life expectancy, for example. Customers in their 70s are now fully productive and an attractive market segment. How can we predict product preferences when we have such a short history for this market segment? Take the fashion industry and the evolving youth culture. How can we use the current youth preferences to shape a product for the next youth generation? Or, more dramatically, take climate change and the corresponding expected changes in agricultural products and operations. We know that agricultural production will change, yet we have no data to integrate into the model to make the right predictions for the future. So, what can we do?
Well, we train a model using state-of-the-art technology with the data we currently have, and then we stay vigilant. At some point, the model will stop working because the underlying world has changed, and the data used in the lab no longer reflect the real-world data.
Sudden, Often Unexpected Changes: Data Jumps
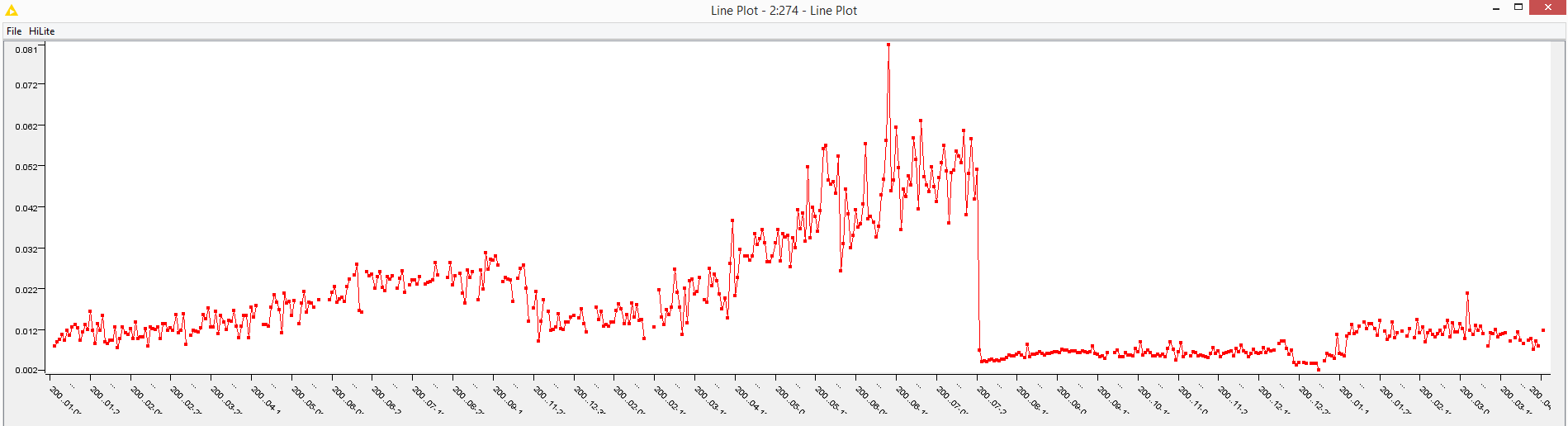
Sometimes changes are not even expected, much less are they quantifiable. Stock market crashes, for example. There might be hints in the preceding stock market history, but more often than not, they come as a surprise as a result of facts unknown to the stockholders. Virus spread is another example. It is plain to see now how the world has changed in a very short time due to the unexpected consequences of the COVID-19 pandemic.
While in the previous example of data drift, machine learning models continue to work for a while (but with deteriorating performance levels), in the case of data jumps, machine learning models stop working suddenly. They have been trained on data from a world that suddenly does not exist. Google traffic predictions are a now-famous example of this. The prediction engine was working great for many years. However, when the COVID-19 pandemic started and lockdowns began in many cities of various countries, traffic also stopped in many parts of the world. Suddenly, all those models predicting traffic had to work with a new kind of data never seen during training in the lab.
Model Monitoring
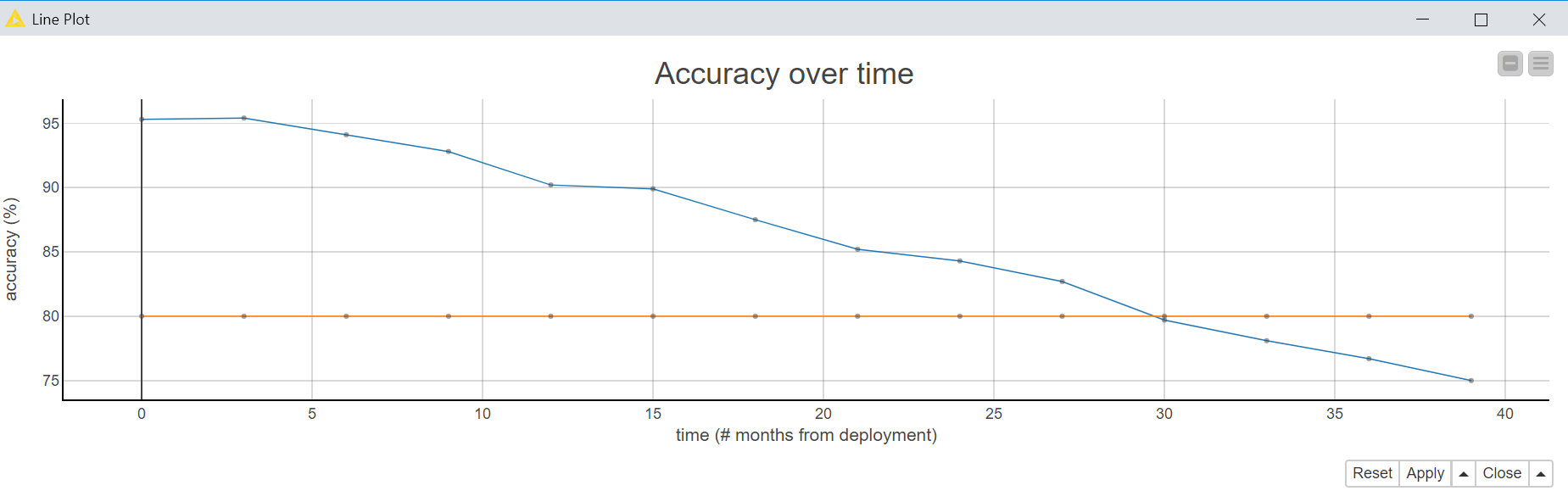
Data drift or data jump as a consequence of a change in the underlying system is what can happen to a machine learning model in its production life, after its lab graduation. It is imperative, then, to monitor the model’s performance periodically once it has been deployed into production.
How often?
What does “periodically” mean? Shall I test my model performance once a week, once a month, or once a year? You know the answer already: It depends on the data and on the business case. Stock predictions have a shorter breath than the shopping preferences of 70-year-old customers. While the stock prices change every minute, the current generation of 70-year-old customers will be around for a while. In the first case, model performance needs testing every few weeks; in the second case, a validation of model accuracy on real-world data can be performed with less urgency every few months — or even as infrequently as once a year.
On what data?
The second issue around model monitoring is the dataset to use for testing. It is clear that the old test set, the one used in the training phase to assess the model performance, is not an option anymore. This dataset might be as obsolete as the training set itself. Indeed, though containing different data from the training set, it still relies on data collected at the same time from the same system. Usually, recent production data are stored for monitoring purposes until a sufficiently large dataset is collected. The model is subsequently tested again on this newly collected dataset. No action is taken if performance drops within an acceptable interval. Contrarily, actions for model retraining must be taken if performance goes below an acceptance threshold.
Using which tool?
Many tools are available, and many tools promise to automate this process. Of course, you do need a professional infrastructure to comfortably set up a full framework for model monitoring. However, when choosing one, make sure that it allows you to collect the new data for testing on the side, while the model is working in production; set the testing frequency and the acceptance performance; and finally, automatically start a new training cycle if needed.
We conclude this quick journey into the life of an AI model after graduating from the lab. We have shown the danger of divergence over time between the world, the data, and the trained model. We’ve also shown how this divergence can happen and how the data scientist needs to set up a model monitoring framework to keep a vigilant eye on the model’s performance — not to blindly trust its functioning into the future.