
Sentiment analysis is an essential tool for businesses to quickly and efficiently gauge customer feedback. Automating the process of identifying whether documents, reviews, social media posts, or other texts convey positive, negative, or neutral sentiment, can streamline decision-making based on customer feedback.
In this article, we explore how you can use GenAI in KNIME for sentiment classification of customer reviews of their experience of U.S. airlines.
What is sentiment classification and how is it done?
Sentiment classification is a type of sentiment analysis that assigns a predefined label (usually: positive, negative, or neutral) to a piece of text.
Sentiment classification can be done using many different approaches, from lexicon-based, machine learning-based, deep learning-based, to techniques rooted in natural language processing (NLP), and more recently, Gen AI-based sentiment analysis.
Before GenAI, we trained our own models or used dictionaries to detect sentiment. Now, we approach the task differently. Instead of training our own model from scratch, as we used to, we typically use pre-trained “out-of-the-box” GenAI models for prediction. Enabling the use of larger models that would be impractical to train yourself.
In this article we want to look at the pros and cons of these two approaches for sentiment classification:
- In the first, we train our own model
- In the second, we use a pre-trained GenAI model
Training your own model vs. using a pre-trained GenAI model
Each approach has its strengths and limitations, depending on the context and available resources.
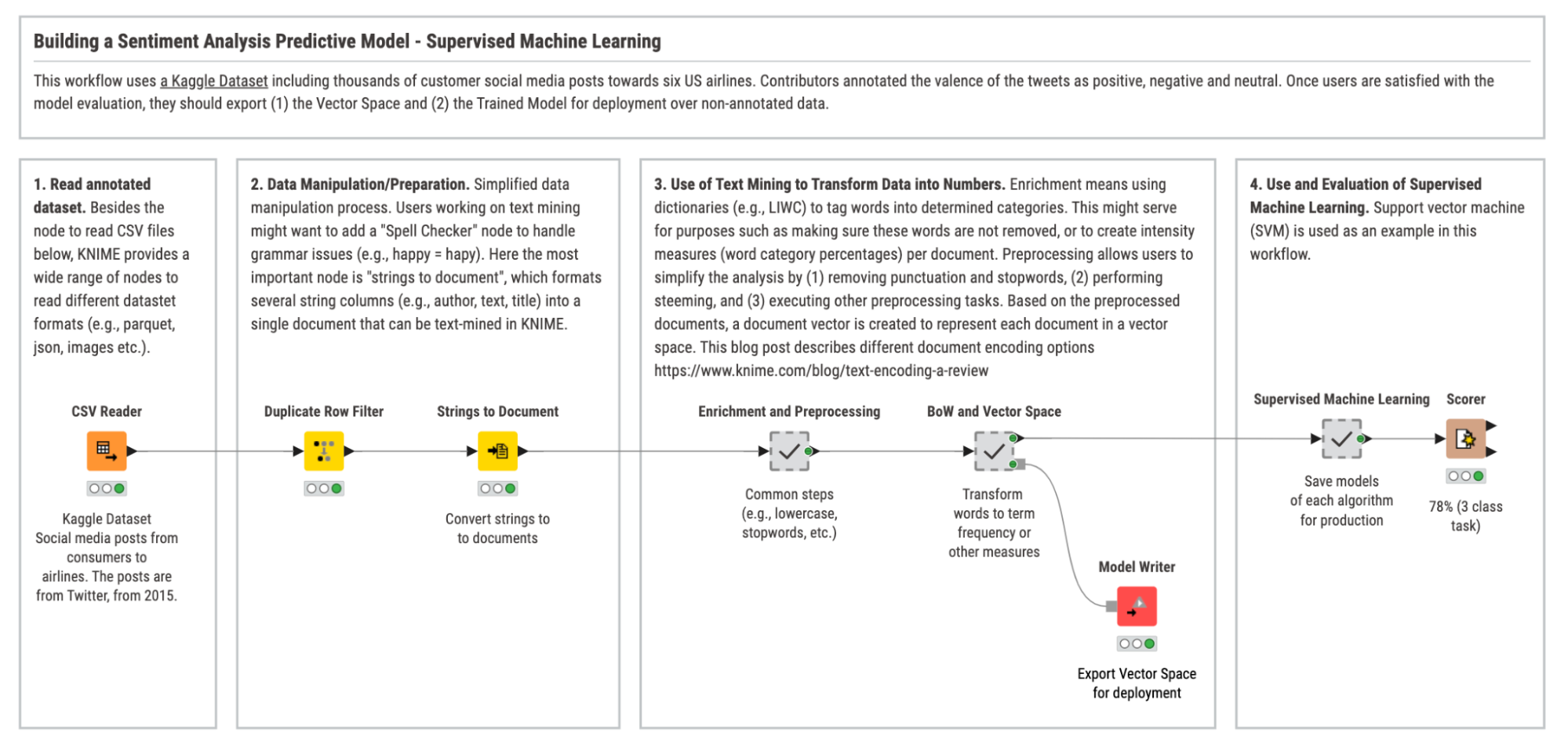
Training our own model for sentiment classification
To train our own model to predict sentiment, we’re going to use a dataset of social media posts, each one of them is labeled with the correct sentiment – either positive, negative, or neutral – based on their content. The labeling of these posts was performed by human annotators.
We train our model on these labels. The model learns patterns from these labels based on various words, phrases, and overall sentence structures in the training data. Once the model is properly trained, it can predict the correct sentiment for new, unlabeled data (e.g., previously unseen social media posts).
Benefits:
- High accuracy when trained on large, high-quality datasets
- Model performance can improve with more data over time
Limitations:
- Requires large, labeled datasets, which are expensive and time-consuming to produce
- Needs retraining as language evolves or new contexts emerge
Here’s an example workflow where we trained a model for sentiment classification using traditional, supervised machine learning.
Using pre-trained GenAI models for sentiment classification
Generative AI models like OpenAI’s GPT-4o are pre-trained on diverse content such as books, articles, reviews, and online conversations. The development of these large-scale models was made possible by the transformer architecture, first introduced in Google’s 2017 paper Attention Is All You Need. This innovation enabled models to capture long-range dependencies in text more effectively, forming the foundation for today’s high-performing language models.
Instead of training these models specifically for sentiment analysis, we can prompt them to perform the task using their general language understanding. This allows us to classify sentiment without additional training or labeled data.
Prompt engineering plays a key role – we guide the model by providing specific instructions. For instance, a prompt can ask the model to classify a text as ��“positive,” “negative,” or “neutral” based on defined criteria. Your prompt could be something like this:
“You work for a travel agency and are supposed to evaluate customer airline reviews. Extract the sentiment from this text <include text>. Classify the sentiment as positive, neutral, or negative.”
Benefits:
- No need for labeled datasets, unless fine-tuning is required as part of the workflow
- Flexible and adaptable to different domains with minimal setup
Limitations:
- Cost – For a high volume of text, usage-based pricing can add up. However, for smaller volumes, this approach may be more cost-effective than creating a manually labeled dataset.
- Responses variability – The model’s outputs may vary slightly between runs, even for the same input.
- Knowledge cutoff – Some models are trained on data available only up to a specific point in time (e.g., GPT-3.5 was trained on data up to 2021)
Here’s an example workflow of a sentiment classification with GenAI in KNIME
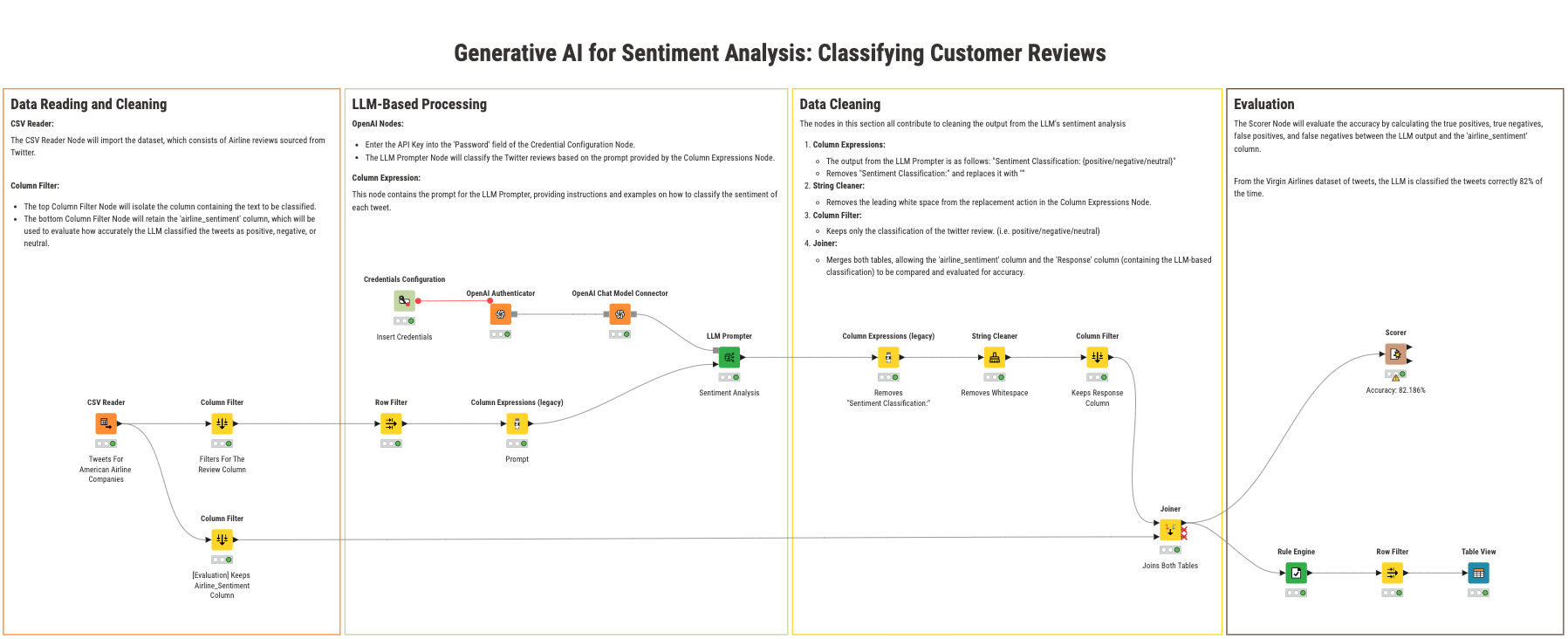
How to build a GenAI sentiment classification workflow in KNIME
Let’s walk through how to build a sentiment classification workflow in KNIME Analytics Platform using the KNIME AI Extension.
The goal is to use a GenAI model to classify these airline reviews as positive, negative, or neutral.
The basic steps in our KNIME workflow will be to:
- Give the model some context in a prompt, telling it our goal and explaining what qualifies as a positive, negative, or neutral statement.
- Evaluate the accuracy or trustworthiness of the GenAI model at predicting the sentiment.
You can download the workflow from KNIME Community Hub here.
Step 1: Data is read in and cleaned
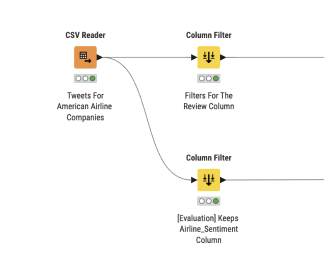
Start by reading the dataset with the CSV Reader node.
- In one path, the Column Filter extracts only the “ext” column for sentiment classification.
- In a parallel path, the labeled sentiment column is preserved to later evaluate the model.
Step 2: Text is processed according to the prompt
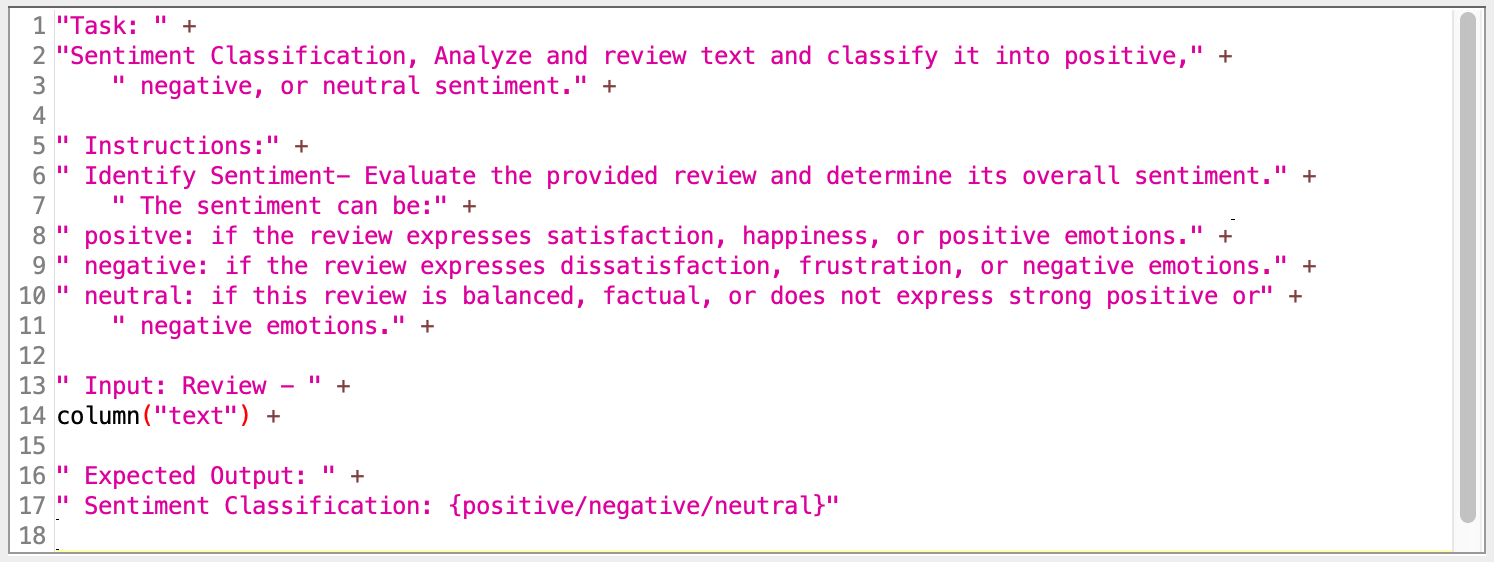
Each customer review is passed into a Column Expressions node, where a custom prompt is built. The prompt includes:
- Task: Communicates the overall goal of sentiment analysis to the model.
- Instructions: Explain what qualifies as a positive, negative, or neutral statement.
- Text processing: Each review is individually processed
- Expected output: A consistent single-word sentiment label
Authentication is handled using the Credentials Configuration and OpenAI Authenticator nodes. After configuration, the OpenAI Chat Model Connector connects to GPT-3.5 and the prompt is passed via the LLM Prompter.
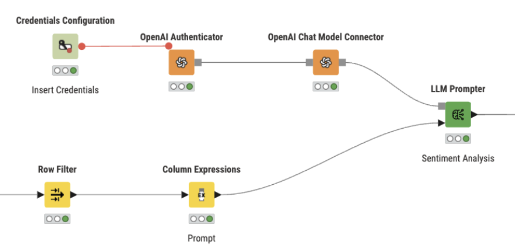
Each of the 14,640 reviews is processed individually and the output is stored in a new column.
Step 3: Data is processed to retain only the single-word sentiment
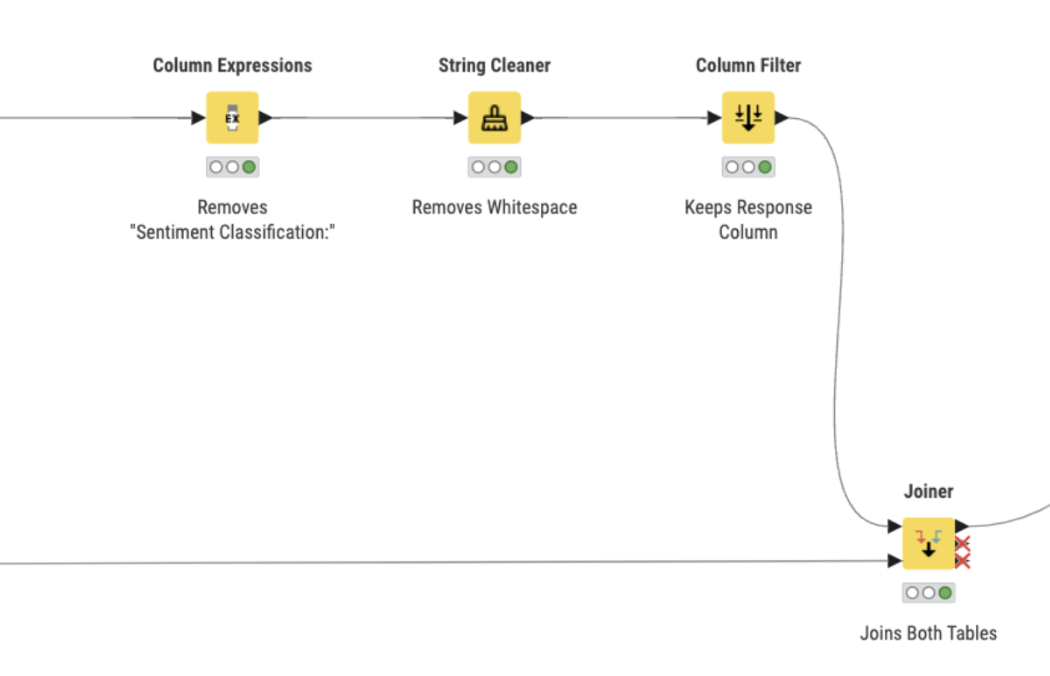
To ensure a clean output, the Column Expressions node is used to extract just the one-word sentiment from each prediction (e.g., converting “Sentiment Classification: {positive}” into “positive”).

Next, the predicted sentiment is joined with the true labels using the Joiner node for model evaluation.
Step 4: Accuracy of the GenAI model is evaluated
We can use the dataset of 14,640 labeled airline experiences from customers from 2015 to evaluate the performance of the GenAI model.
It’s the same labeled dataset as the one we used in the supervised machine learning example mentioned above.
We can use the labeled column to evaluate the accuracy of the GenAI model in predicting the right sentiment label for each post.
The Scorer node in our KNIME workflow compares predicted and actual sentiment labels. The GenAI model achieved an overall accuracy of 82%. To better understand performance, we also looked at precision and recall. A breakdown by sentiment revealed:
- Negative sentiment: 93% precision and 88% recall
- Positive sentiment: 75% precision and 88% recall
- Neutral sentiment: 64% precision and 63% recall
The model was particularly strong at identifying negative sentiment but struggled more with positive and neutral cases.
Limitations:
- Sensitivity to prompt structure – Small changes in phrasing can affect the output, making consistent prompting important.
- No domain-specific memory – Out-of-the-box models do not retain domain knowledge unless extended with additional tools, such as vector stores.
- Cost at scale – For large datasets, using proprietary LLMs can become expensive. However, for smaller volumes, this method may still be more cost-effective than manually labeling data in a traditional setup.
The potential of GenAI for sentiment classification
GenAI’s ease of use, flexibility, and general understanding of language make it a valuable tool for quickly understanding sentiment at scale and simplifies the process of extracting customer feedback insights. While GenAI is usually good at taking into account sarcasm and irony, it may still fail at times. It’s therefore valuable to add in an additional trustworthiness step – to evaluate just how accurate the output really is.
With tools like KNIME AI Extension, building a GenAI model for sentiment classification becomes accessible – even for users without coding experience.