
Large Language Models (LLMs) excel at understanding and generating natural languages. Their ability to mimic human conversational behaviors makes them incredibly versatile in and proficient at a wide range of tasks, from casual conversations to translation, summarization, and even more complex activities like code generating.
LLMs are increasingly shaping practices and services in various industries, revolutionizing the way we interact with technology.
But the question is, can we leverage state-of-the-art LLMs for our own use cases without the need for resource-intensive computational demands and time investment?
The answer is: Yes!
In this blog, learn how you can build your own LLM-based solutions using KNIME, a low-code/no-code analytics platform.
We’ll explore:
- How you can leverage both open-source and closed-source models
- The pros and cons of each approach
- How to put your knowledge into practice with a simple KNIME workflow and use LLMs to predict the sentiment (positive vs. negative) of financial and economic news.
Create your own LLM-based solutions with the KNIME AI Extension (Labs)
The KNIME AI Extension (Labs) enables you to harness the power of advanced LLMs and it’s available from KNIME Analytics Platform version 5.1.
This extension gives you the functionality to easily access and consume robust AI models from diverse sources, such as OpenAI, Azure OpenAI, and Hugging Face Hub for API-based models, or GPT4All for local models. This means it is now possible to leverage advanced language capabilities, chat functionalities, and embeddings in your KNIME workflows by simple drag & drop.
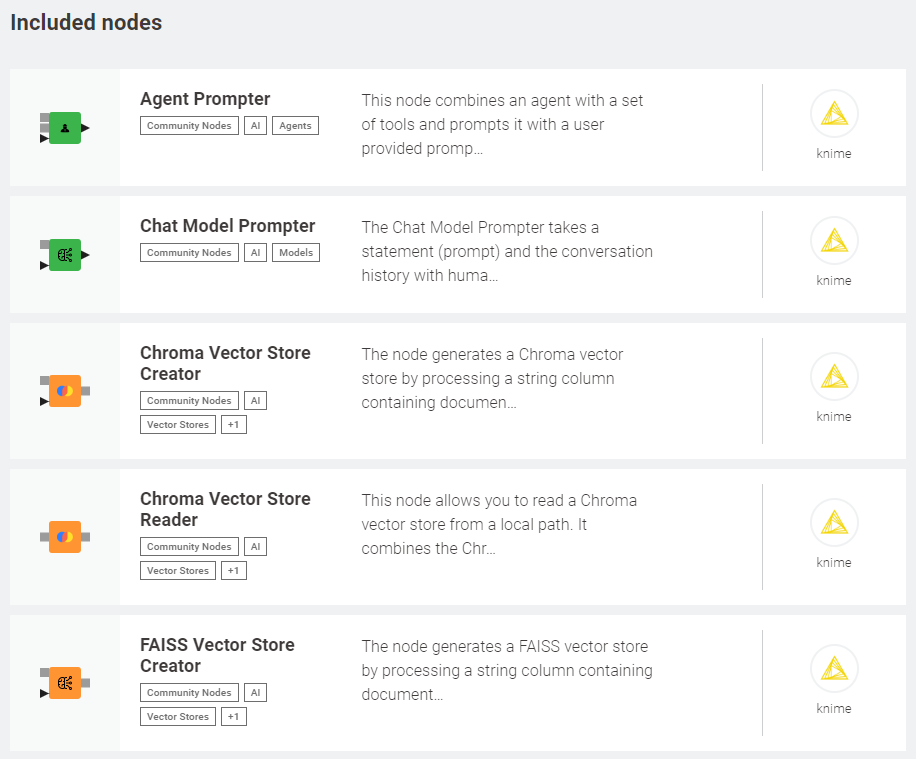
The extension also provides nodes for more advanced applications so that you can efficiently build and query vector stores like Chroma and FAISS, and customize LLMs’ responses via retrieval augmented generation.
It also offers features to combine multiple vector stores and LLMs into agents that, given the user prompt, can dynamically decide which vector store to query to output custom responses.
The variety of nodes available in the extension allows us to explore two distinct philosophies to leverage LLMs: open-source or closed-source. Let’s have a look at the pros and cons of each of them, and the key nodes to access and leverage LLMs in KNIME.
Using open-source LLMs via API
More than 150k models are publicly accessible for free on Hugging Face Hub and can be consumed programmatically via a Hosted Inference API.
- Performance. Model performance varies significantly according to model size, training data, and task. Overall, the performance of open-source models is steadily improving to close the gap with that of closed-source counterparts. Yet, the latter tend to be superior.
- Pros. The vast majority can be accessed for free, is well-documented, does not require powerful hardware, and can be used for different tasks (e.g., text generation, summarization, etc.).
- Cons. They may be rate limited for heavy use cases, can incur service outage, and are prone to potential data privacy concerns. Free access is possible only if Hugging Face’s Hosted Inference API is activated.
To connect to free models via the Hugging Face’s Hosted Inference API, we need a free access token. To get one, we can create an account on Hugging Face, navigate to “Settings >Access Tokens” and request a token. With the access token, we can swiftly authenticate to Hugging Face using the HF Hub Authenticator node.
Upon authentication, we can use the HF Hub LLM Connector or the HF Hub Chat Model Connector node to connect to a model of choice from the wide array of options available. These nodes require a model repo ID, the selection of a model task, and the maximum number of tokens to generate in the completion (this value cannot exceed the model’s context window). In the “Advanced settings”, it’s possible to fine-tune hyperparameters, such as temperature, repetition penalty, or the number of top-k tokens to consider when generating text.
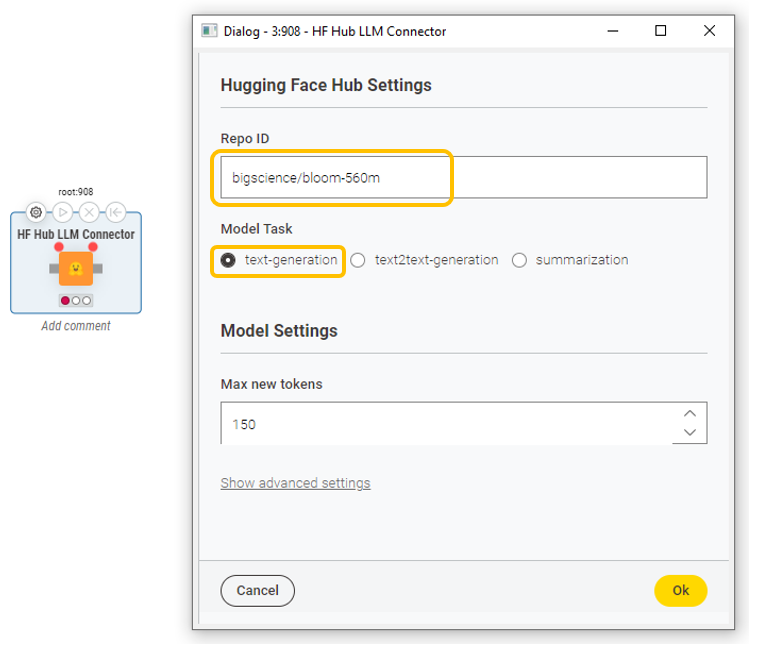
The model repo ID and model task can be found directly on Hugging Face Hub. This means that only models compatible with the task category specified in the node can be accessed.
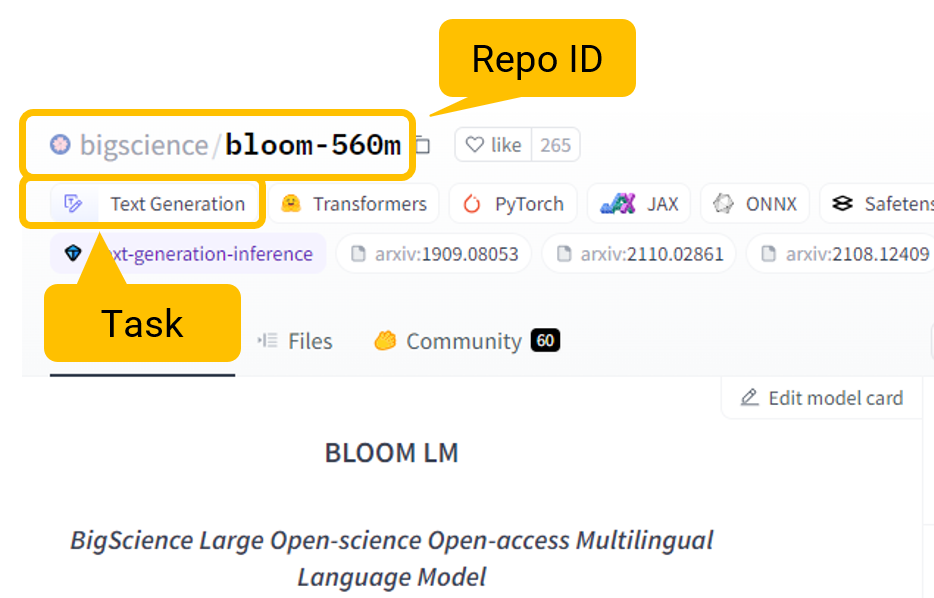
Lastly, to successfully use the HF Hub LLM Connector or the HF Hub Chat Model Connector node, verify that Hugging Face’s Hosted Inference API is activated for the selected model. For very large models, Hugging Face might turn off the Hosted Interference API.
Using open-source LLMs locally
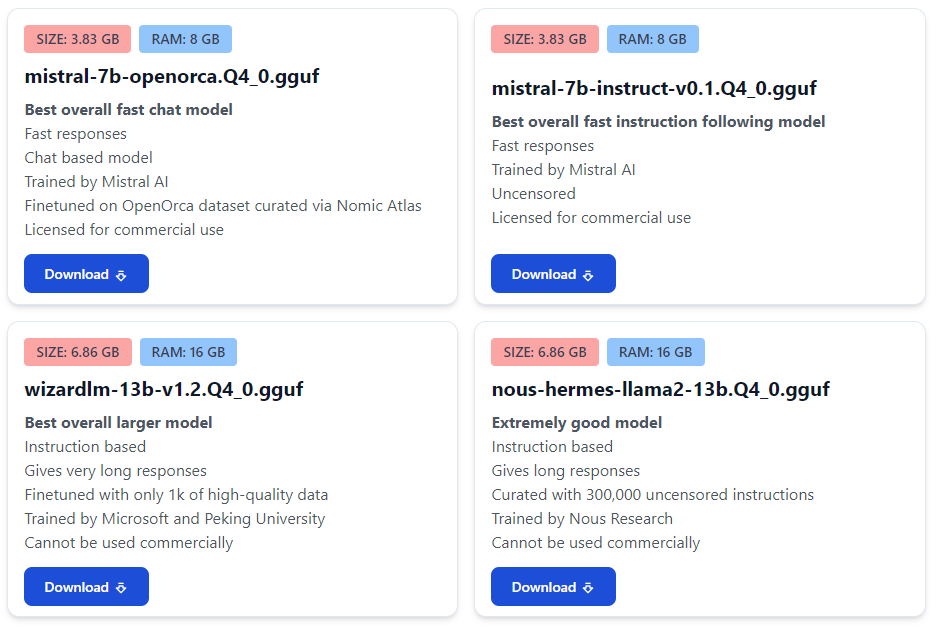
An ever-growing selection of free and open-source models is available for download on GPT4All. The crucial difference is that these LLMs can be run on a local machine.
- Performance. Model performance varies significantly according to model size, training data, and task. Overall, the performance of open-source models is steadily improving to close the gap with that of closed-source counterparts. Yet, the latter tend to be superior.
- Pros. They can be accessed for free, do not require an Internet connection for execution, are not rate limited, and can be run locally and used for different tasks (e.g., text generation, summarization, etc.). Furthermore, the possibility of running these models locally removes concerns for data privacy.
- Cons. They often require powerful local hardware for smooth execution, as model performance increases with model size (> 8 GB). Furthermore, their response time is usually slower, as it heavily depends on the hardware capabilities.
To leverage free local models in KNIME, we rely on GPT4All, an open-source initiative that seeks to overcome the data privacy limitations of API-based free models. From the GPT4All website, we can download the model file straight away or install GPT4All’s desktop app and download the models from there.
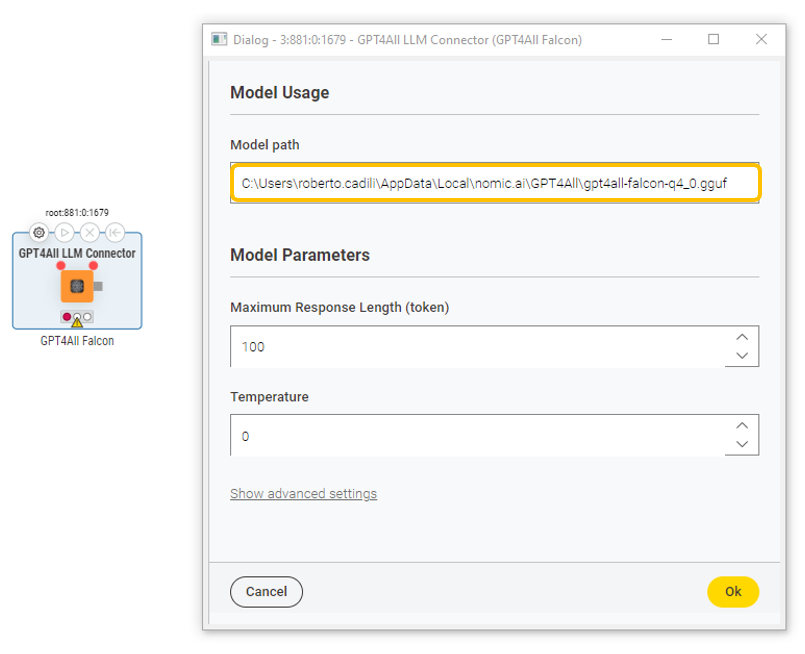
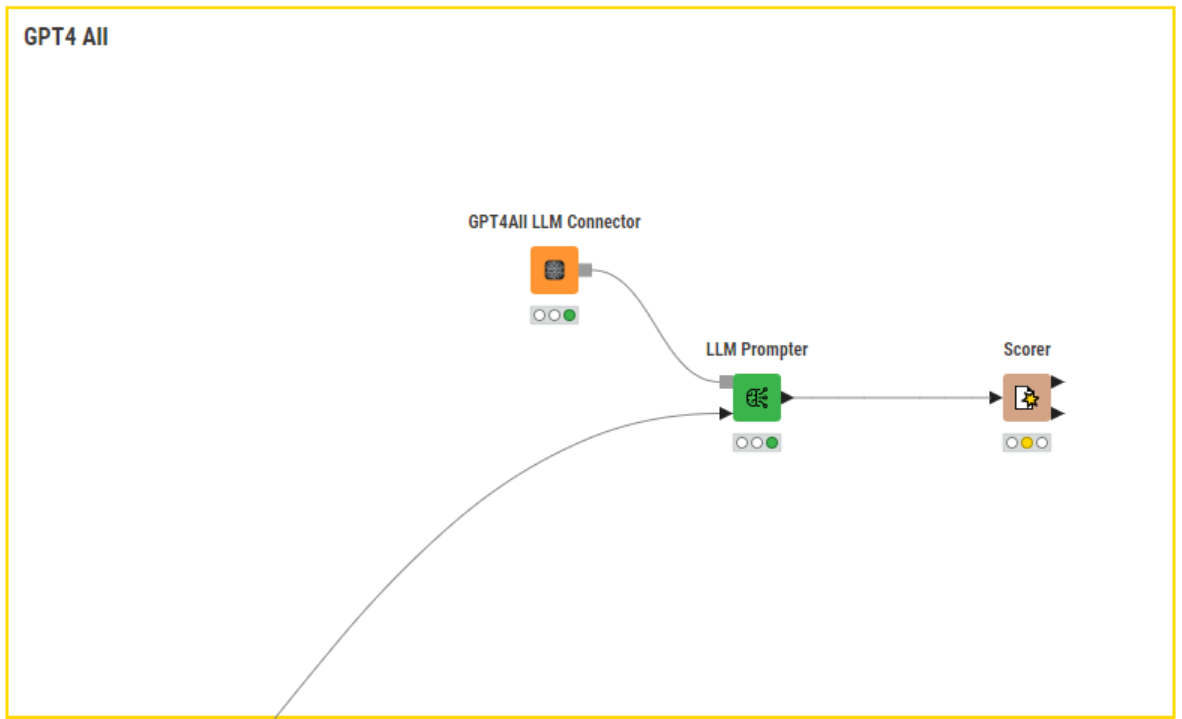
With the GPT4All LLM Connector or the GPT4All Chat Model Connector node, we can easily access local models in KNIME workflows. After downloading the model, we provide the local directory where the model is stored, including the file name and extension. We set the maximum number of tokens in the model response and model temperature. Additionally, in the “Advanced settings”, we can customize different token sampling strategies for output generation.
Using closed-source LLMs
Major technology giants, such as OpenAI or Microsoft, are at the forefront of LLM development and actively release models on a rolling-base. These models are closed-source and can be consumed programmatically on a pay-as-you-go plan via the OpenAI API or the Azure OpenAI API, respectively.
- Performance. Model performance varies according to model size, training data, and task. Overall, the performance of closed-source models is superior to that of open-source counterparts.
- Pros. They offer access to the newest technology and enable the creation of cutting-edge solutions. They are also well-documented, maintained and supported, do not require powerful hardware, and can be used for different tasks (e.g., text generation, summarization, etc.).
- Cons. They require the payment of a fee for programmatic consumption via the API. They may be rate limited for heavy use cases, can incur service outage, and are prone to potential data privacy concerns (initiatives are increasingly taken to mitigate this risk).
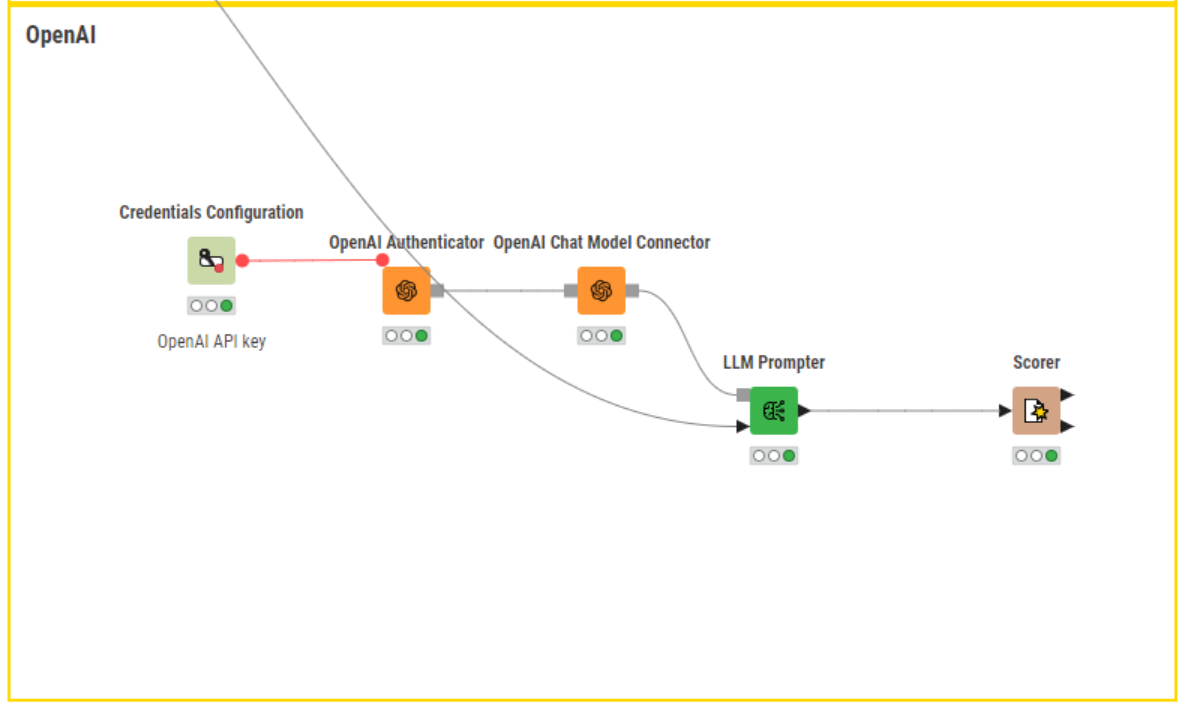
To access OpenAI models, we need an API key. To get one, we can create an account on OpenAI, fill in payment details and navigate to the “API keys” tab to generate it. With the API key, we can swiftly authenticate to OpenAI using the OpenAI Authenticator node.
Upon authentication, we can use the OpenAI LLM Connector or the OpenAI Chat Model Connector node to access a model of choice, depending on whether we want a model with text completion (e.g., text-davinci-003, the model behind GPT-3) or conversational capabilities (e.g., gpt-3.5-turbo, the model behind ChatGPT). These nodes require the selection of model ID, the setting of the maximum number of tokens to generate in the response, and the model temperature. In the “Advanced settings”, it’s possible to fine-tune hyperparameters, such as how many chat completion choices to generate for each input message, and alternative sampling strategies.
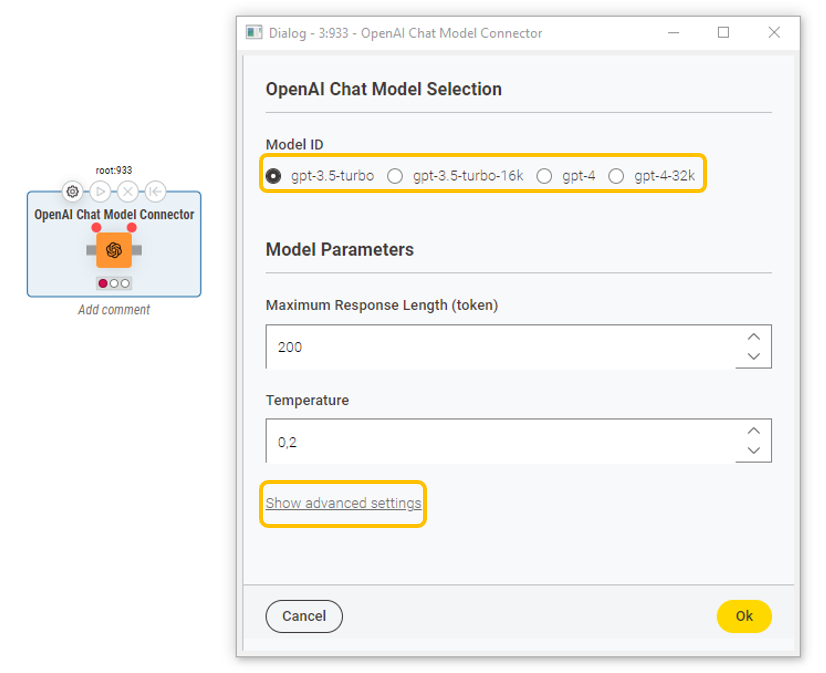
A similar procedure applies for generating an API key for Azure OpenAI, authenticating and connecting to the models made available by this vendor.

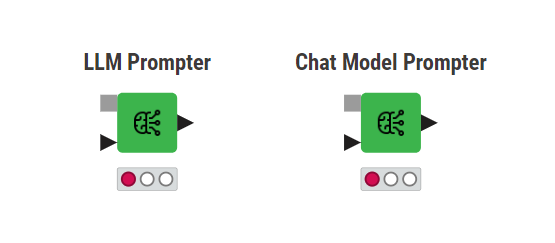
Talking to LLMs with prompters
Regardless of the chosen philosophy to access LLMs, querying the models requires a prompting engine. For that, we can rely on the LLM Prompter or the Chat Model Prompter nodes. These nodes take as input the connection to the chosen LLM model (gray port) and a table containing the instructions for the task we want the model to perform.
As output, the LLM Propter node returns a response where rows are treated independently, i.e. the LLM can not remember the content of previous rows or how it responded to them. On the other hand, the Chat Model Prompter node allows storing a conversation history of human-machine interactions and generates a response for the prompt with the knowledge of the previous conversation.
Use case: How to build an LLM-based sentiment predictor
Let's now dive into a hands-on application to build a sentiment predictor leveraging LLMs and the nodes of the KNIME AI Extension (Labs).
Download the KNIME workflow for sentiment prediction with LLMs from the KNIME Community Hub.
Sentiment analysis (SA), also known as opinion mining is like teaching a computer to read and understand the feelings or opinions expressed in sentences or documents.
Today’s example explores an application of SA for the financial sector, where we’ll focus on detecting sentiment orientations in financial and economic news. The dataset that we will use comprises two columns: one containing ∼5000 phrases/sentences sampled from financial news texts and company press releases, and the other indicating the corresponding sentiment as either positive, negative, or neutral. For the sake of simplicity, we'll focus solely on positive and negative sentiments, but the process can be easily extended to handle multi-label classification.

Data access and prompt engineering
We start off by importing the dataset with the financial and economic reviews along with their corresponding sentiments (positive, negative, neutral). For the sake of this example, we filter out reviews with neutral sentiment and downsample the dataset to 10 rows.
Next, in the Table Creator node, we type the prompt that we’ll pass on to the model:
“Assign a sentiment label, positive or negative, to the following text: ”.
The pivotal step here involves joining the prompt with each review (= row) in the dataset. Practically, this means creating a new column, containing the prompt and the review, that serves as the input query to the model.
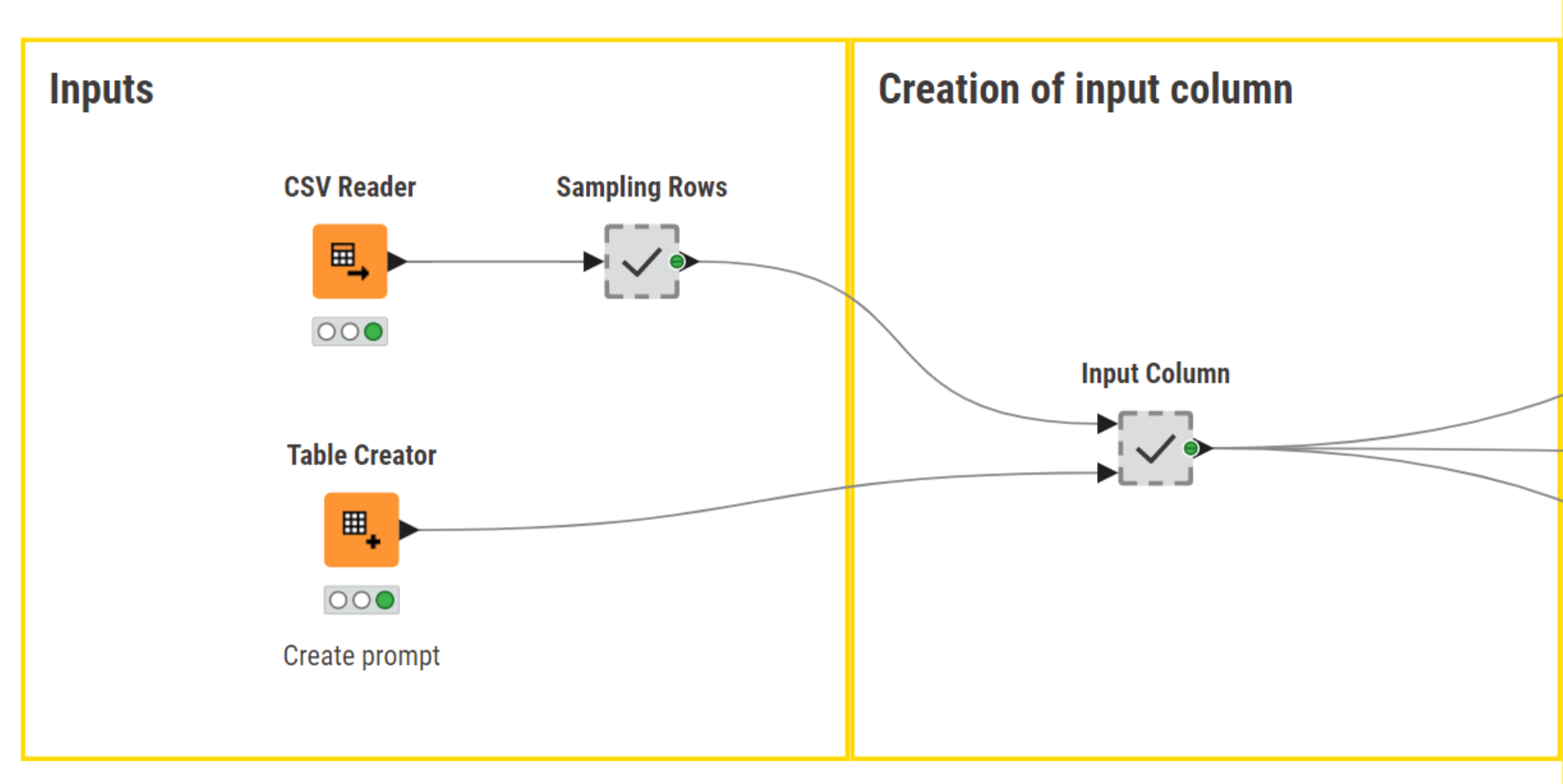
Model prompting
Once we have created the input query, we are all set to prompt the LLMs. For illustration purposes, we’ll replicate the same process with open-source (API and local) and closed-source models.
The interaction with the models remains consistent regardless of their underlying typology. It essentially entails authenticating to the service provider (for API-based models), connecting to the LLM of choice, and prompting each model with the input query. As output, the LLM Promper node returns a label for each row corresponding to the predicted sentiment.
The three models employed are: gpt4all-falcon-q4 (local model), zephyr-7b-alpha (accessible via Hugging Face Hub), and gpt-3.5-turbo (via OpenAI). We tested each model on the same data sample.
For API-based models, an access API key is essential. This can be easily provided to downstream nodes with the Credential Configuration node.
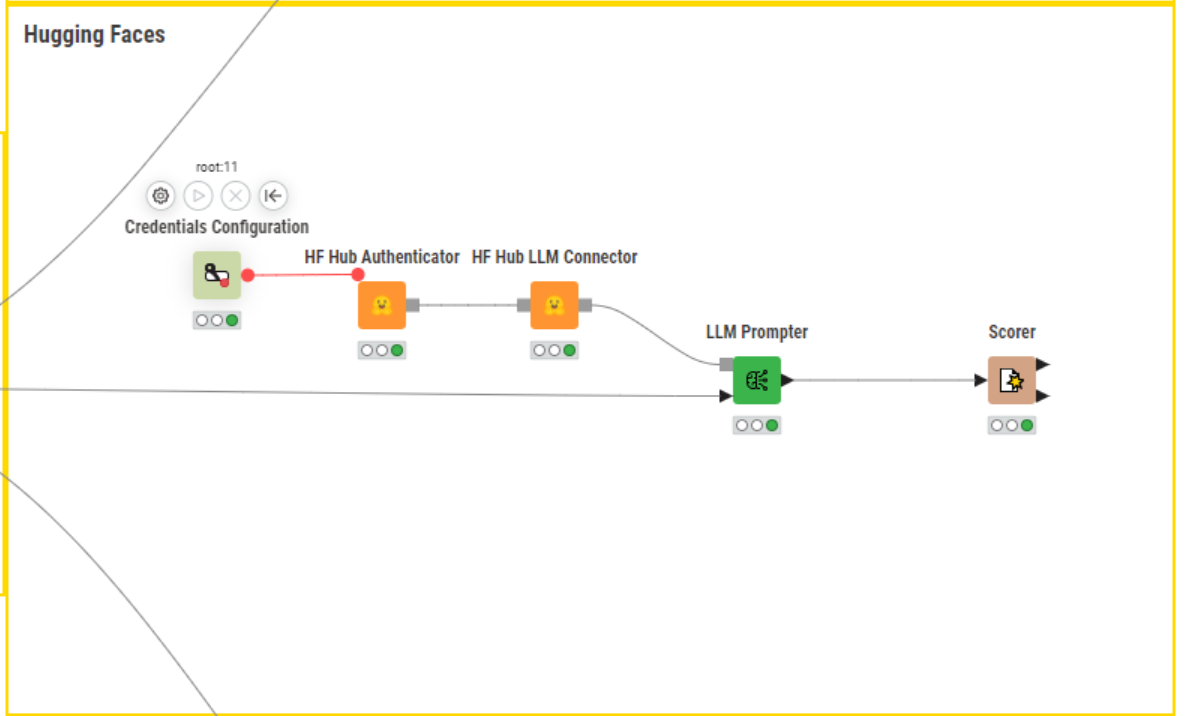
To prompt the local model, on the other hand, we don’t need any authentication procedure. It is enough to point the GPT4All LLM Connector node to the local directory where the model is stored.
Model scoring
The task that we asked the LLMs to perform is essentially a classification task. The dataset that we used for this example has a column containing ground truth labels, which we can use to score model performance.
In terms of performance, using the Scorer node, we can see that the chosen models achieved accuracies of 82.61% (gpt4all-falcon-q4), 84.82% (zephyr-7b-alpha), and 89.26% (gpt-3.5-turbo). OpenAI’s ChatGPT emerges as the top performer in this case, but it's worth noting that all models demonstrate commendable performance.
Start building customized LLM-based solutions for your needs
As a versatile tool, LLMs continue to find new applications, driving innovation across diverse sectors and shaping the future of technology in the industry. In this article, we saw how you too can start using the capabilities of LLMs for your specific business needs through a low-code/no-code tool like KNIME. Browse more such workflows for connecting to and interacting with LLMs and building AI-driven apps here.