
Tagging content plays an important role for corporate websites, blogs, streaming services, and e-commerce vendors. A well-designed tagging strategy helps customers easily navigate a website and apply filters, ensuring they see content aligned with their interests. While manually tagging a few items is manageable, the challenge arises when dealing with thousands of them.
For instance, let’s say an e-commerce platform decides to start to categorize all its products (e.g., jackets, TVs, dishwashers, books, etc.) or update an existing one. Carrying out this task manually would be an enormous undertaking in terms of manpower and costs. If something has a detailed description, it can take a lot of time to figure out the categories for a tag and it can be really hard to do without making mistakes.
If manual tagging isn't the way forward, what's the alternative? Tagging content is essentially a classification task and, as data experts, we could use supervised machine learning to automate it. This approach, however, has a major drawback: it requires an extensive dataset with correctly tagged content to properly train and test models.
So, what's the solution? Fortunately, we're in the era of Large Language Models (LLMs). Leveraging these models for classification tasks via prompt engineering is a viable and efficient strategy for content tagging.
In this blog post, we will learn how to automatically tag blog posts on the KNIME Blog with LLMs in 4 steps namely:
Our ultimate goal is to help you identify the content you are interested in, simply and intuitively.
We will do this on the KNIME Analytics Platform which is a low-code data science tool. KNIME is an intuitive tool making it easy to collaborate on data science projects. All along, we will rely on the KNIME AI Extension
Let’s get started!
Step 1: Define the tag sets
To carry out this task, we teamed up with the Marketing team. Their help was essential in defining tag sets that would effectively speak to data practitioners and managers alike. More specifically, we defined three sets of different tags:
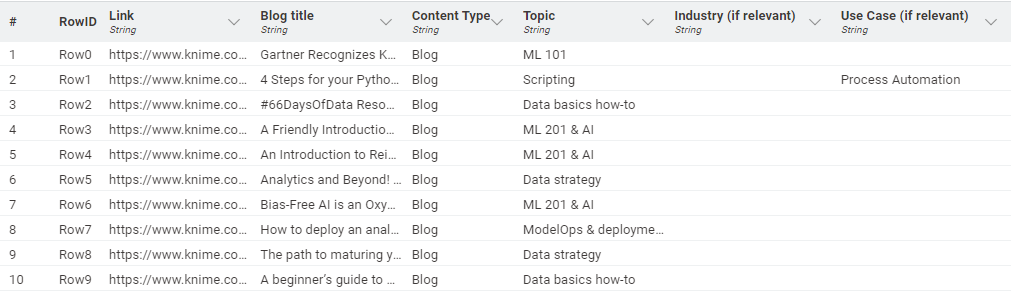
- Topic. This tag set contains 19 tags and aims to encompass different approaches, techniques, and strategies in data science (e.g., “Data blending”, “ML 101”, etc.).
- Use Case (optional). This tag set contains 12 tags and aims to describe macro-fields to which a particular use case may belong (e.g., “Marketing Analytics”, �“Supply Chain Analytics”, etc.). We will include tags of this set only when relevant.
- Industry (optional). This tag set contains 20 tags and refers to the main existing industries (e.g., “Education”, “Healthcare”, etc.). We will include tags of this set only when relevant.
Due to three sets of different tags, this task is a multi-label classification task. Each blog post can be labeled with one tag (Topic), two tags (Topic & Use Case, or Topic & Industry), or three tags (Topic & Use Case & Industry).
To tag the blogs, we relied on OpenAI’s ChatGPT and its capability to understand and generate texts via the nodes of the KNIME AI Extension. The same strategy can be adapted to work with open-source models accessible via the same extension. It is worth noting that, as in traditional ML approaches, the larger the number of labels (or combinations of labels) we want to automatically assign, the harder it is to obtain accurate predictions.
Step 2: Scrape content from the blog
We started by identifying relevant information from blog posts that the LLM would need to process to output a tag. Passing the full text in the prompt would provide the LLM with plenty of details and context information. However, doing so poses the risk of incurring higher costs, exceeding the service rate limits, the maximum number of tokens, or the model context window.
The service rate limit (usage restriction), the maximum number of tokens (words/subwords), and the model context window (scope of information) are all so-called hyperparameters. They represent the external factors that influence the learning process and outcome and can be tuned to guide, optimize, or shape model performance for a specific task
Striking a balance in this situation means that we retrieved and included only blog posts and paragraph titles in our prompts. More specifically, we used only blog post titles to assign Topic tags, and both blog post and paragraph titles to assign Use Case and Industry tags. We assume that they represent the minimal and most meaningful information for the model to accurately assign labels.
Disclaimer: This assumption is tailored specifically to the writing style and formatting of blog posts published on the KNIME Blog and may not apply in other scenarios.
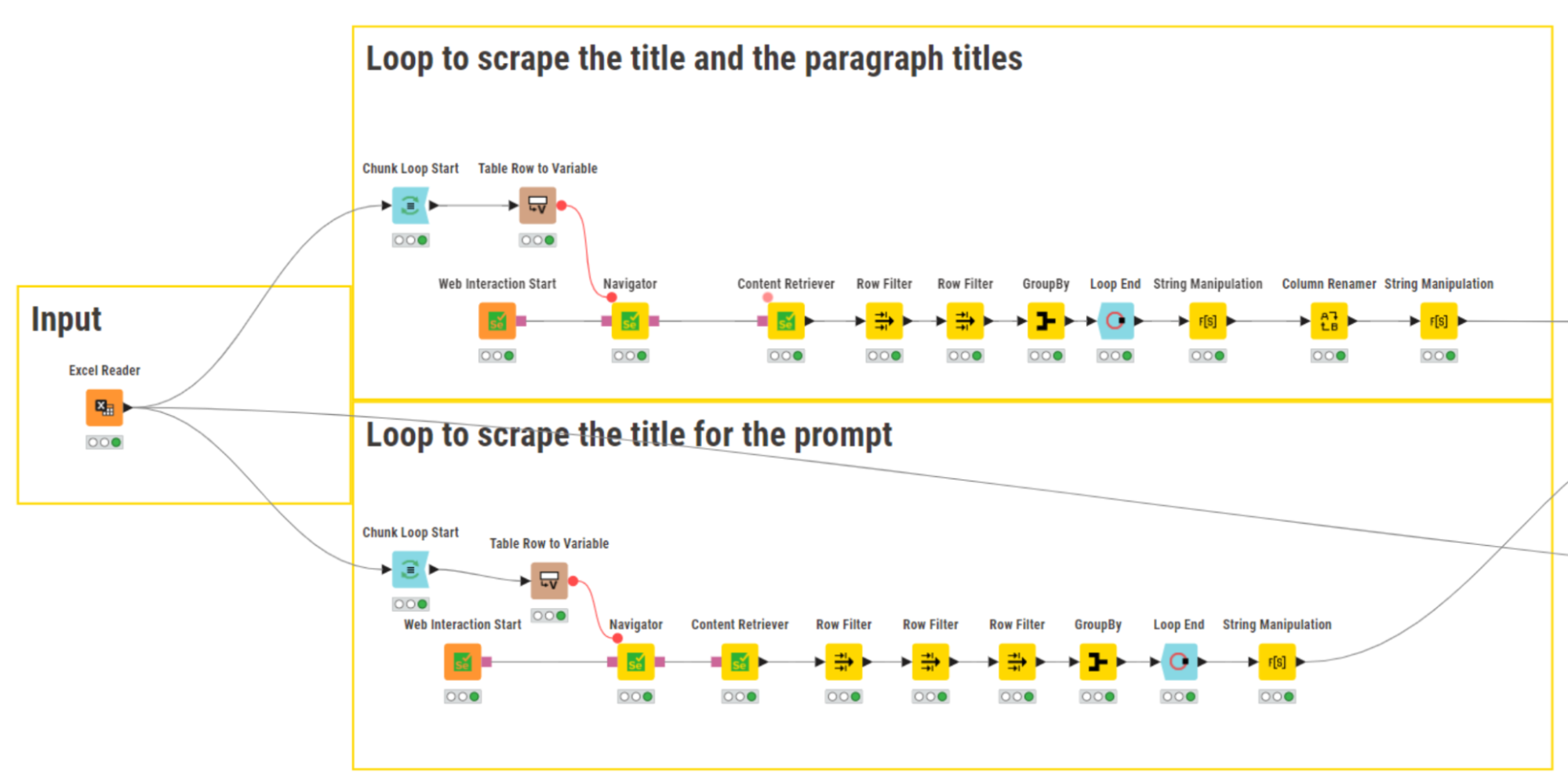
Using the Excel Reader node, we imported an extensive list of blog post URLs (for faster execution, in the shared workflow we included only a sample of approximately 20 URLs). Having access to URLs means that we can build a web scraper to automatically collect blog posts and paragraph titles.
To do that, the nodes of the KNIME Web Interaction extension came in handy. The extension, based on Selenium, allows us to start a browser session from the KNIME Analytics Platform for remote-controlled web interactions.
For the sake of clarity, we divided the web scraper into two sections. The top branch scrapes blog and paragraph titles, whereas the bottom branch only blog post titles. We looped over the list of URLs, started a browser session, and extracted blog posts and paragraph titles enclosed within the <h1> and <h2> HTML tags, respectively, using the Content Retriever node.
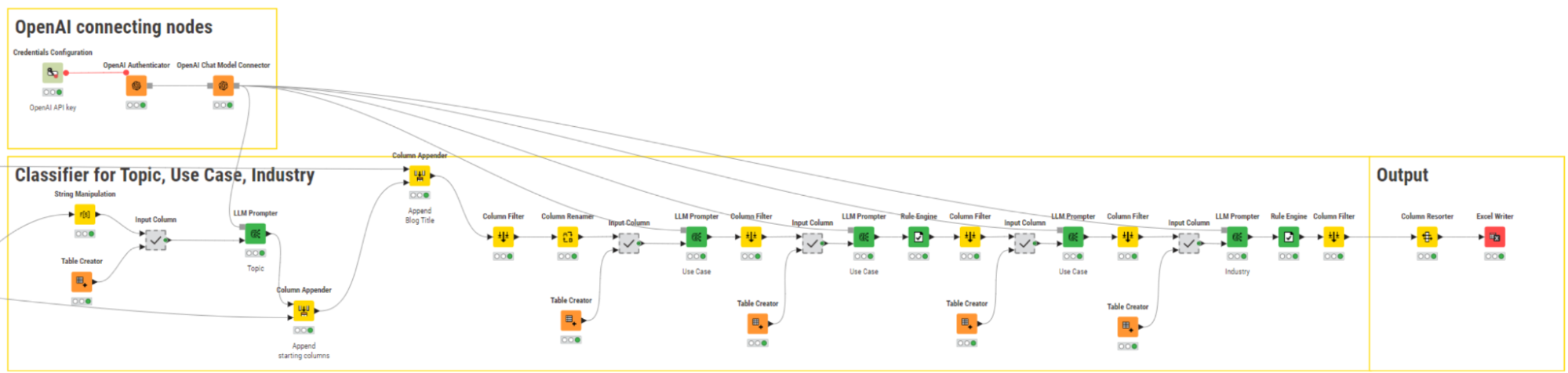
Step 3: Assign topics to blogs
When dealing with LLMs, a crucial step lies in effective prompt engineering. The ability to make the model understand the task accurately and return the desired output depends largely on how we formulate our requests. While there exist best practices for crafting optimal prompts, the process often involves a great deal of trial and error.
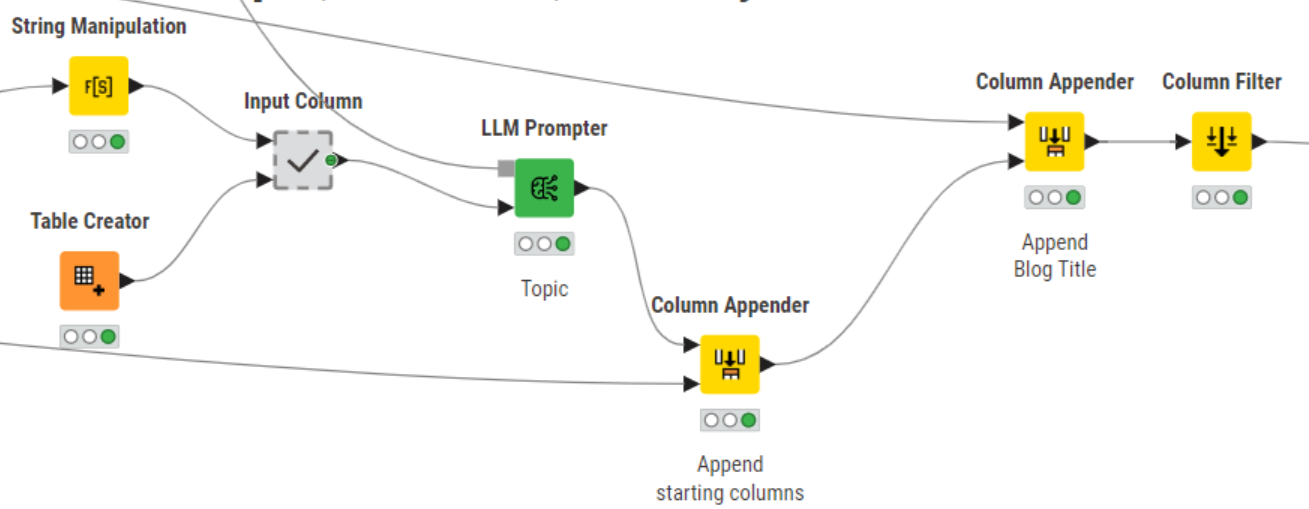
In our specific use case, we realized it was necessary to preprocess the labels used for Topic tagging. To clarify the example, let’s list some of the tags:
- “Automation inspiration”
- “Dashboard kickstarts”
- “Data basics how-to”
- “ML 101”
- “Put simply”
- “Cheminformatics”
A notable issue with this tag set is that some tags, such as "Put simply", focus more on the writing style rather than the topic of the blog post. It's important to emphasize that the more precise and pertinent the prompt is, the more likely the output will align with our intentions. Hence, to fine-tune the relevance of the responses, we excluded some tags, such as “Put simply” or “Company news”, from our prompts.
Moreover, we re-phrased certain tags to be more self-explanatory. For instance, "ML 201 & AI" was modified to "Advanced Machine Learning and AI". This was just a temporary trick as tags that had been changed were reverted to their original form later on through string manipulation.
Download the content tagging workflow from the KNIME Community Hub.
Another step in prompt refinement involved crafting the prompt in a way that minimized the need for post-processing of the model output. Our goal was to obtain a discrete tag without unnecessary additional information. For example, we didn’t want the model to return something like “The Topic of the provided text is Bioinformatics”, but rather only “Bioinformatics”. One way to achieve this was by adjusting the model's hyperparameters. Indeed, we set the temperature to a lower value, as this hyperparameter influences the creativity of the model's responses. Lowering the temperature instructs the model to exhibit less randomness in its behavior.
Lastly, adopting a few-shot learning approach further enhanced our prompt. This involves presenting the model with examples of the desired behavior, making it more inclined to align with our specific goal.
Using the String Manipulation node, the final prompt for Topic classification was designed as follows and passed on to the LLM Prompter node:
“You are a classifier that gets an input and outputs one of the following classes: {CLASSES}, like in the following examples: {EXAMPLE 1} {EXAMPLE 2} {EXAMPLE 3} {EXAMPLE 4}.
Here’s the input, just output the class: BLOG POST TITLE.”
Step 4: Assign use case and industry
The last step in the project involved assigning Use Case and Industry tags. As these tend to encompass much broader and fuzzier domains, the LLM could not easily predict the most fitting ones solely from the title. For that reason, we enriched the prompt also with paragraph titles.
Lastly, it was essential to address the scenario where no tags were needed, considering that a specific Use Case or Industry tag might not apply to every blog post. We observed that the LLM had a high propensity to always generate a tag even when this was not needed. This behavior could be explained by the multitude of possible tags or the presence of overly general ones.
To handle this problem, in addition to prompt engineering, we split the process into two separate iterations. The first iteration involved asking the model if a specific Use Case tag (and later an Industry tag) could be identified:
“You will be given a text and you must return "Yes" if a single use-case/industry can be identified; otherwise, if no use-case/industry is present or multiple use-cases/industries are present, return "No". Here’s the text:”
In the second iteration, a few-shot learning approach was implemented again, this time to pinpoint examples where the Use Case and/or Industry tags were meaningfully assigned to a blog post. Finally, the results were filtered to retain only those with a "Yes" response from the previous interaction.
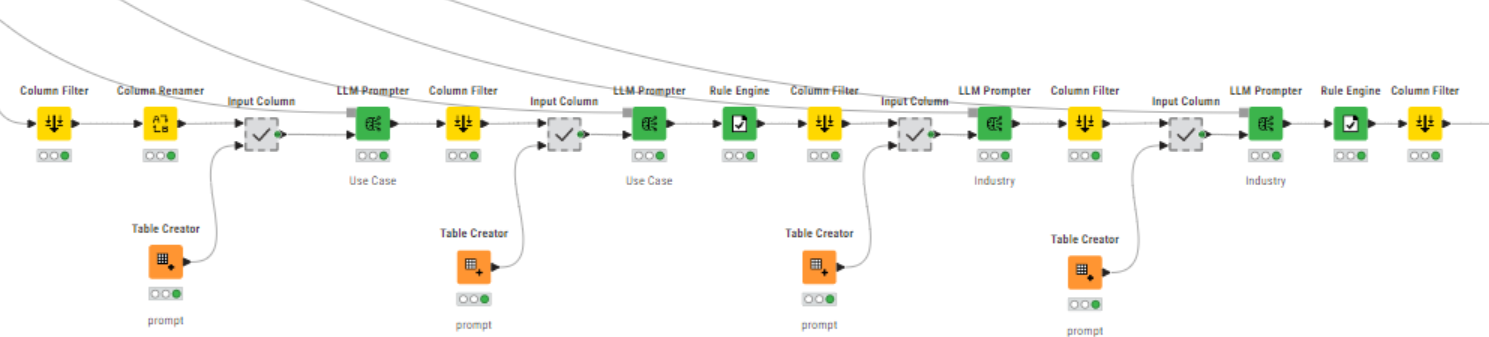
After obtaining the desired tags, the information was consolidated into a table and exported to Excel.
A few sample checks and validation rounds later under the supervision of the Marketing team and voilà, our web designer could now easily apply those tags to content on the KNIME Blog! What’s Your AI-powered Use Case?
In this blog post, we explored how leveraging LLMs can streamline the process of tagging content, making it an easy and automatic task.
In this example use case, we relied on the capability of OpenAI’s ChatGPT. However, using more advanced models, while more expensive (e.g., OpenAI’s GPT-4), would likely result in better outcomes and fewer post-processing operations. Free models are also an option, but they may demand more human supervision as they tend to be less reliable.
In addition to model proficiency, strategies for clever prompt engineering played a crucial role. The better-crafted prompts were likely to obtain results that were tailored to meet specific requirements.
As LLMs increasingly excel in a wide array of natural language-related tasks and free us from tedious manual work, using low-code data science tools, like KNIME, lowers the barrier to using these advanced techniques and building the right AI-powered solution.
What use case are you going to tackle with an AI-powered solution?