This is part of a series of articles to show you solutions to common finance tasks related to financial planning, accounting, tax calculations, and auditing problems all implemented with the low-code KNIME Analytics Platform.
Fraud patterns are continually evolving, making it increasingly challenging to keep pace with the sheer volume of transactions. In this article we want to look at quantiles as a simple and quick solution for identifying suspicious transactions and give you a solution in KNIME that is able to analyze large volumes of transaction data quickly.
This is one of several articles on detecting fraud that look at two types of fraud detection: classic machine learning based predictions – when your dataset contains enough fraud examples (e.g. random forest) – and outlier detection based techniques – when your dataset doesn’t contain enough fraud examples. Here we’re going to use quantiles to detect the outliers or the suspicious transactions in our dataset of credit card transactions. Watch the video for an overview.
What are quantiles?
Quantiles are values that divide a dataset into equal-sized intervals, helping to understand the distribution of the data. By examining quantiles, we can identify what constitutes "normal" data. In the context of credit card transactions, quantiles help establish the typical range of legitimate transactions. Transactions that deviate significantly from this range can be flagged as suspicious or potentially fraudulent, as they are considered outliers. While quantiles are typically aimed at linearly distributed datasets, we will demonstrate that they can also perform well on highly skewed datasets, such as the one in our use case.
Why KNIME for quantile calculations?
While quantile calculations can be performed in Excel, the advantage of using KNIME Analytics Platform is that as a data science tool, KNIME is designed to handle large datasets efficiently. You can also use it to automate data intake from various sources, reducing the need for manual intervention, and its visual, low-code environment makes it accessible for financial teams without expertise in coding.
Let’s get started!
The Task: Identify fraudulent transactions using quantiles
Credit card transactions fall into two primary categories: legitimate and fraudulent. The challenge lies in accurately identifying and flagging fraudulent transactions to ensure minimal false positives.
Fraud detection typically involves a mix of manual and automated steps for transaction patterns, customer behavior, and other pertinent factors. For our focus, we will concentrate on the automation aspect by training a model on a labeled dataset and applying it to new transactions to simulate incoming data from an external source.
We utilize a well-known dataset from Kaggle named Credit Card Fraud Detection. This dataset consists of real, anonymized credit card transactions made in September 2013 by European cardholders. It contains 284,807 transactions over two days, including 492 fraudulent transactions. This dataset is characterized by a significant class imbalance, with fraudulent transactions ('frauds') making up only 0.172% of the data, compared to the vast majority of legitimate transactions ('good').
The dataset contains 31 columns:
- V1 - V28: numerical input variables from a PCA (Principal Component Analysis) transformation
- Time: seconds elapsed from current transaction to first transaction
- Amount: transaction amount
- Class: ‘1’ means fraud, ‘0’ means good/other
A key feature needed for our training is ‘Class’ as we can use it to score the performance of the quantile-based classification method.
The process for creating our classification model follows the steps below. Even if there is data coming from multiple sources, the overall process does not change:
- Create/import a labeled training dataset
- Z-score normalize the data
- Remove non outliers based on defined quantile scalar
- Mark outliers on input data
- Evaluate model performance
- Import the new, unseen transactions
- Deploy the model and feed the new transactions in
- Notify if any fraudulent transactions are classified
The Workflows: Using quantile classification to identify fraudulent transactions
All workflows used in this article are available publicly and free to download on the KNIME Community Hub. You can find the workflows on the KNIME for Finance space under Fraud Detection in the Quantile section.
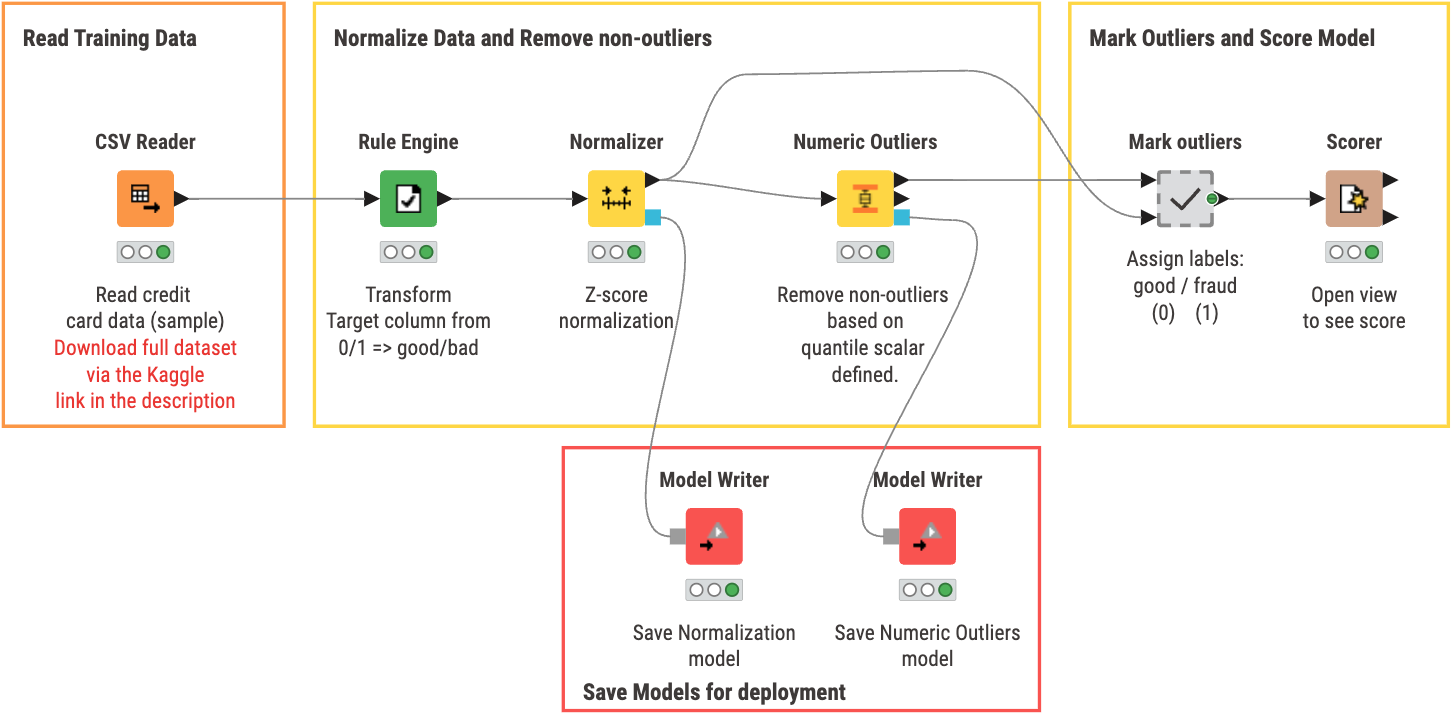
The first workflow covers training our model. You can view and download the training workflow Quantile Method Training from the KNIME Community Hub. With this workflow you can:
- Read training data from a specified data source. In our case, we use data from the Kaggle dataset previously mentioned.
- Normalize the data by applying a z-score normalization on all numeric data columns
- Remove Non-outliers by using the Numeric Outliers node based on the defined quantile scalar
- Mark Outliers based on the result from the Numeric Outliers node
- Evaluate model results by opening the view of the ‘Scorer’ node to check overall accuracy of the Outlier classification.
- Save the models for deployment in the next workflow if you are satisfied with the performance
In our second workflow, Quantile Method Deployment, you can:
- Read the previously saved models and new data for classification
- Apply the models on the new transaction after normalization of the new transaction
- Mark Outliers
- Send an Email to notify if a transaction is fraudulent
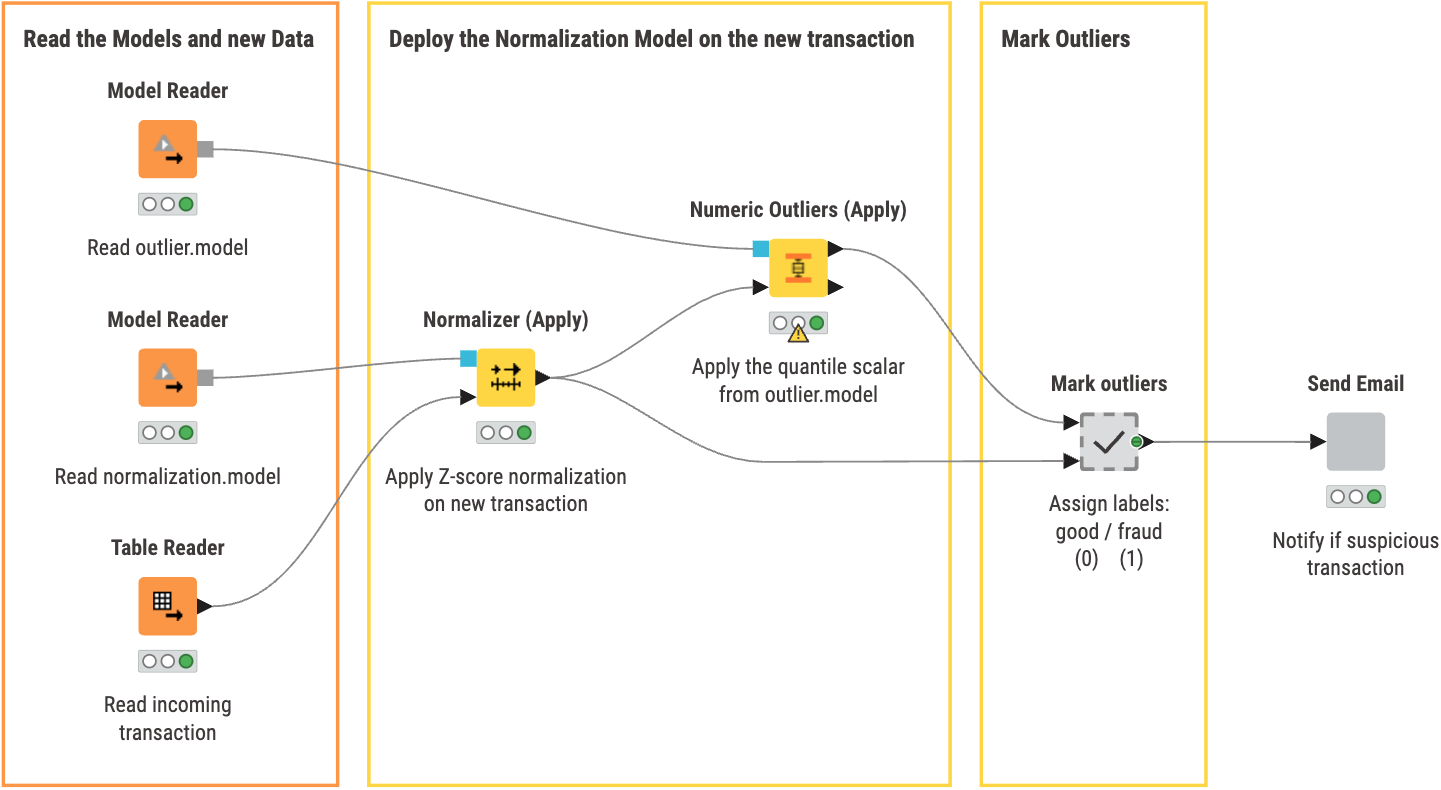
Inside the ‘Send Email’ component, we check whether the transaction is fraudulent or not. If it is, an email is sent to the specified person for follow up.
The Results: A model for classifying transactions with quantiles
Let’s go back to the first workflow for a moment. From the training workflow, the results we get by opening the view of the ‘Scorer’ node is shown below.
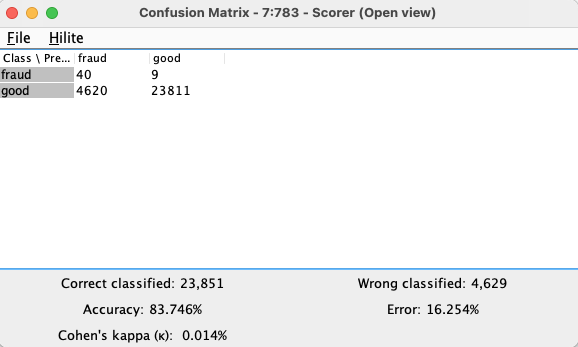
We have a confusion matrix that outlines statistics of the quantile-based method of classification. We can see that the overall accuracy came out to 83.7 %. In the context of the alternative methods available, this method does not perform up to par. For example, the Random Forest method yielded a much better accuracy. Nevertheless, this type of performance is to be expected as quantile-based classification is one of the simple implementations of anomaly detection that works well for linear or evenly distributed data. As the method we use is sensitive to distributions in the data, our dataset used from kaggle is highly skewed with a very small percentage of fraudulent transactions which is one of the main reasons we see this relatively low performance. Although not the best, the quantile method offers a quick and easy way of classifying data which can potentially be used for quick preprocessing or for linear data use cases.
The new transaction being read in is normalized and applied into the saved models from the training workflow. The new transaction is classified as ‘not fraudulent’ or ‘good’, so our switch statement closes the port to the email.
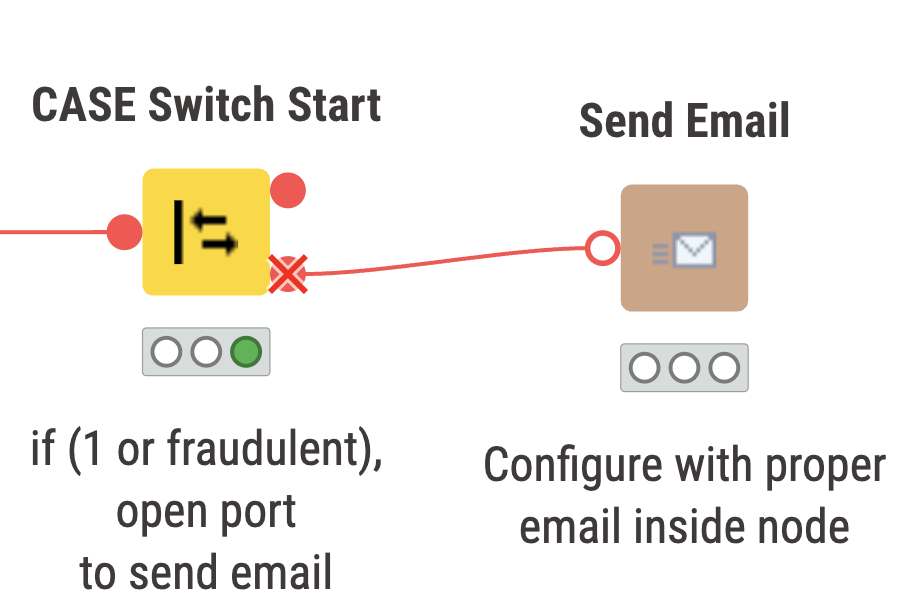
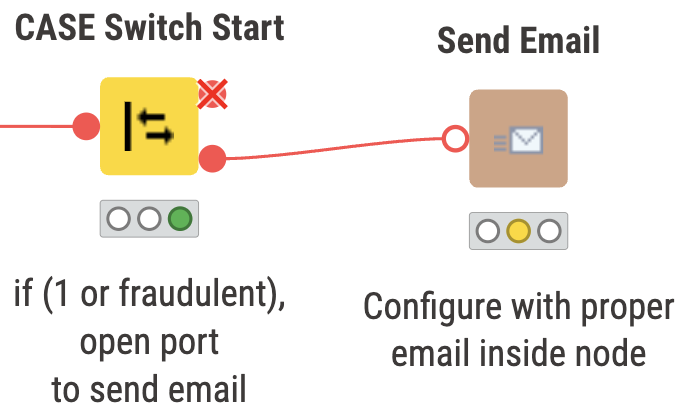
Above we have two snippets of what can be expected to occur depending on the classification of the transaction. On the left, we have a non fraudulent transaction, and on the right the port will open up if the transaction is fraudulent or ‘1’.
Why KNIME for Finance
KNIME provides finance teams with easy access to advanced data science techniques tailored for managing large data volumes efficiently. Utilizing KNIME’s intuitive interface, teams can collect, clean, and analyze data from both new and legacy sources, automate tedious data processing tasks, and develop advanced models for fraud detection. Explore more finance solutions on the KNIME for Finance space on KNIME Community Hub.