
One way to fix AI hallucinations is to give the model more knowledge.
You can do this with Retrieval Augmented Generation (RAG). It’s a technique that enables you to add your own data to the prompt and ensure more accurate generative AI output.
In this tutorial, we want to show you how to develop an RAG-based AI framework in KNIME, using functionality from KNIME’s AI Extension (Labs). We’ll demonstrate how to generate embeddings, how to create a vector store and retrieve information from it to ensure that your GenAI application produces fact-based responses.
To illustrate the process, we built an example workflow that mitigates factual hallucinations in LLM responses about the nodes of the KNIME Deep Learning - Keras Integration.
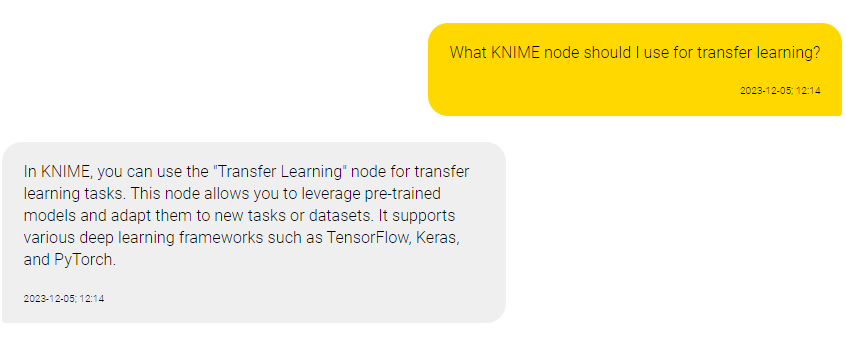
Example of a factual hallucination
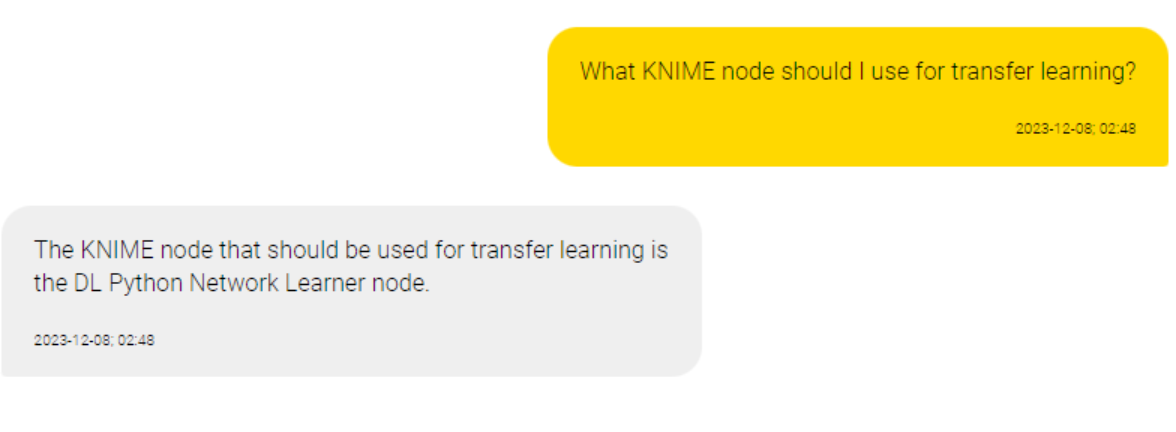
We prompted OpenAI’s ChatGPT model with the question: "What KNIME node should I use for transfer learning?"
The model hallucinated a response. It fabricated the name and functionality of a KNIME node for transfer learning that doesn’t exist (shown below).
The model presents the information as a fact and in a well-argumented manner. It’s easy to believe this hallucination if you don’t read with a skeptical eye.
We can mitigate this hallucination and obtain a response that is grounded in fact using functionality in the KNIME AI Extension (Labs).
The KNIME AI Extension (Labs) provides nodes to connect to and prompt Large Language Models, chat and embeddings models provided by OpenAI, Hugging Face Hub and GPT4All. It also provides nodes to build and query Chroma and FAISS vector stores and combine multiple vector stores and LLMs into agents.
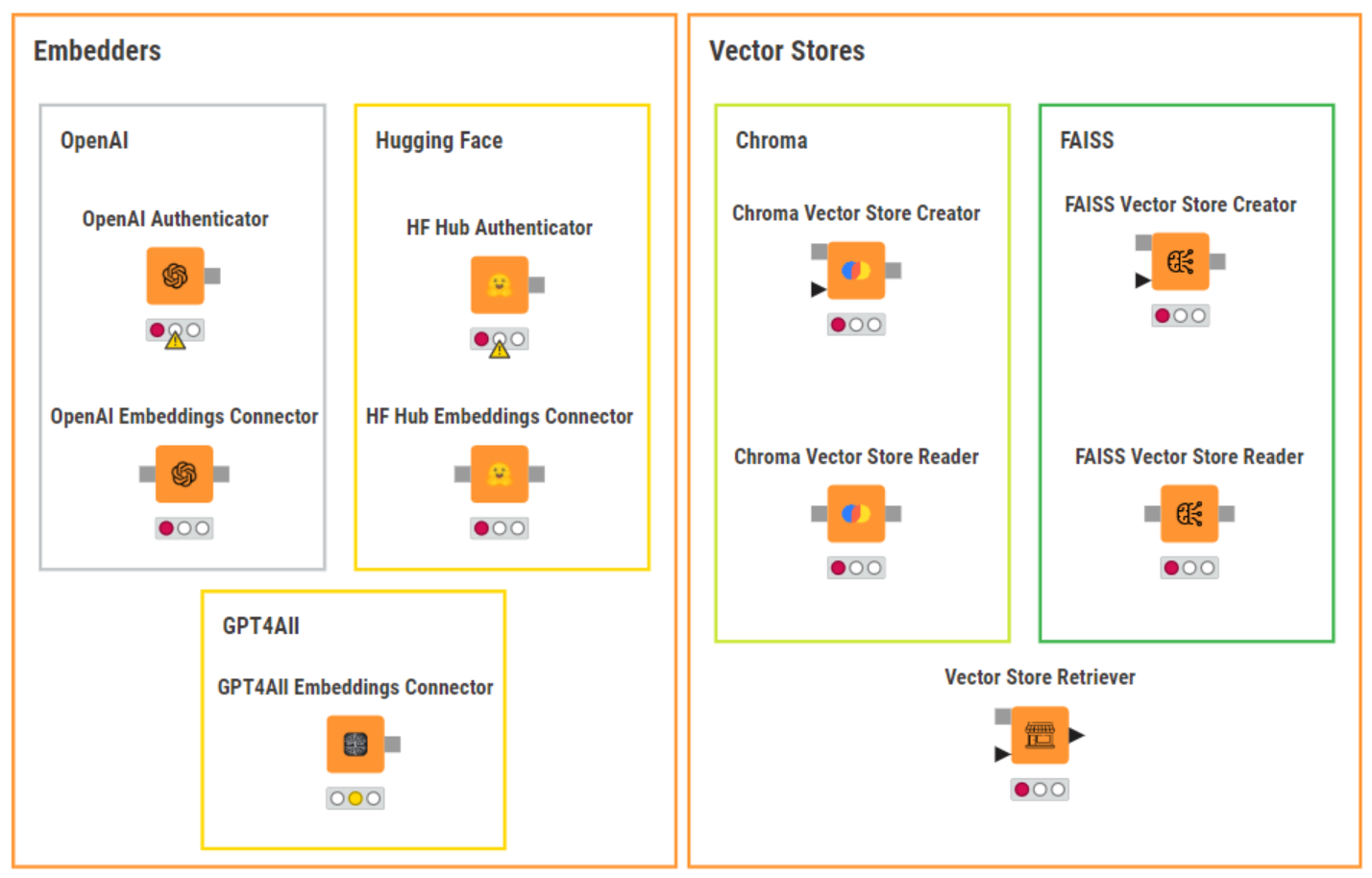
Let’s get started with our workflow to mitigate hallucinations in LLMs, which you can download from the KNIME Community Hub.
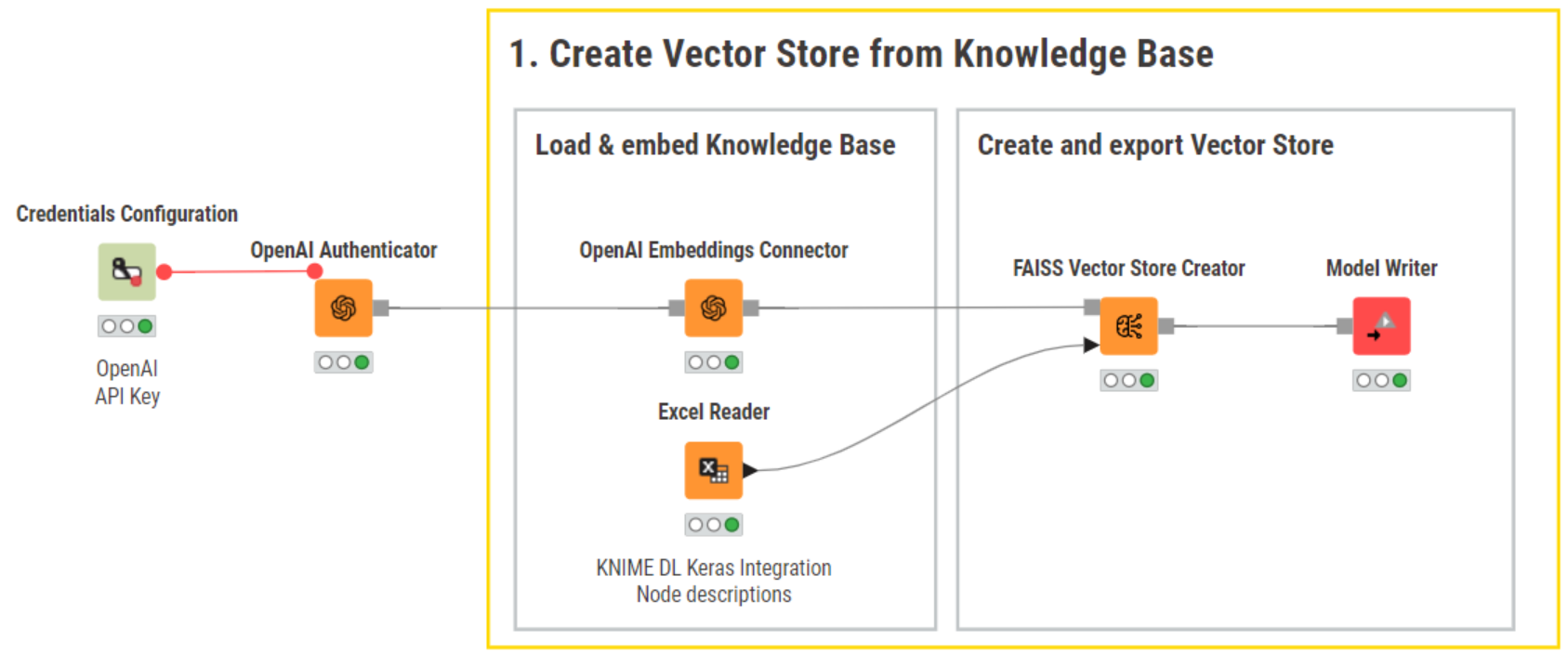
Create a vector store from a knowledge base
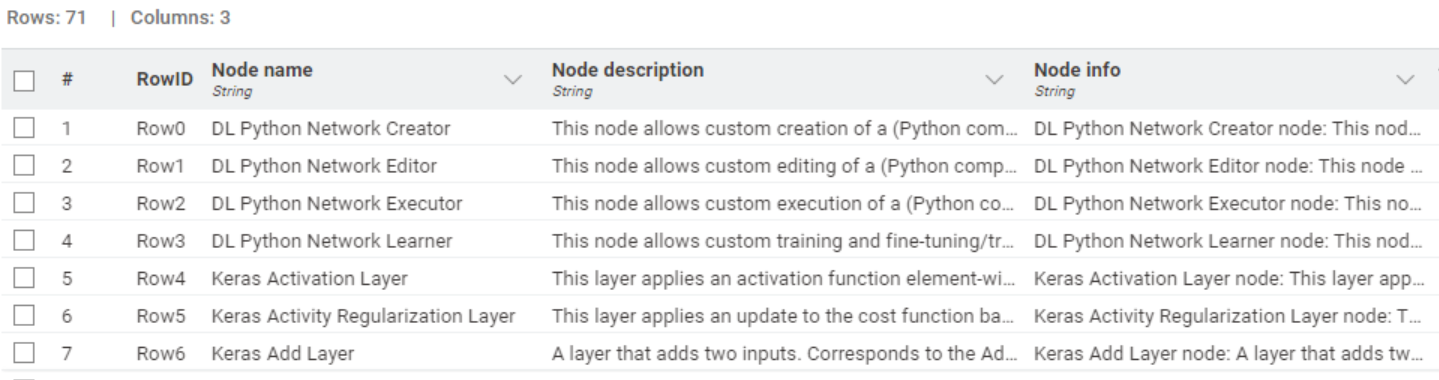
We start off by importing a user-curated knowledge base. This is highly domain-specific, as it contains only the names and descriptions of the nodes in the KNIME Keras integration for deep learning.
You can see below that the column “Node info” combines the node name and description.�
Next, we authenticate to OpenAI’s API, and use the OpenAI Embeddings Connector node to select the “text-emeddings-ada-002” model and generate embeddings of the knowledge base.
We create our vector store using the FAISS Vector Store Creator node. This vector store will store those embeddings for efficient information retrieval. This node requires you to select the main document column to be stored. It can also store other columns as metadata.
Finally, we use the Model Writer node to export the vector store.
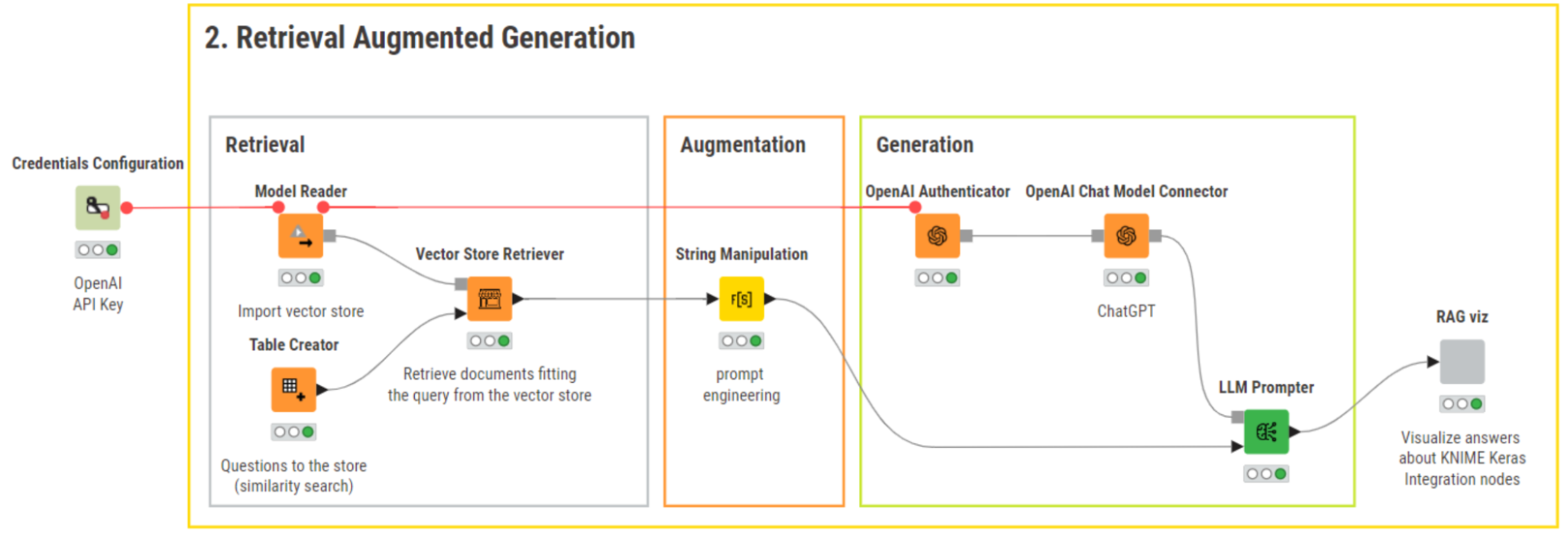
Retrieve, augment and generate a fact-based response
We import the newly created vector store using the Model Writer node.
Let’s now type our initial question into the Table Creator node:
"What KNIME node should I use for transfer learning?"
Retrieve documents
The key node in the “Retrieval” step is the Vector Store Retriever. We feed the vector store and a table with the user’s query in the input ports.
To configure the Vector Store Retriever node, we select the column containing the query(-ies) and define the number of most similar documents to be retrieved for each query. For this example, we set the number of retrieved documents to 5. While this number is arbitrary and can be increased/decreased by the user, the number you choose can affect the generated responses. Let’s have a look at why.
Vector similarity metric explained
In the vector store, a similarity metric determines why the user prompt is more similar to one document over another document.
The similarity metric computes and assigns a score of similarity to each document to find out how similar these are to the user prompt. Next, documents are sorted by their similarity scores from more similar to less similar. Different similarity metrics are used depending on the vector store (e.g., Chroma, FAISS, etc.).
Embeddings (vectors) are complex high-dimensional representations, which makes computations of similarity scores complex and difficult to interpret. This raises several questions. For example, how accurate is the similarity metric? How can we interpret the distance between two different similarity scores –how dissimilar are the two documents from each other and, ultimately, the user prompt? We don’t have crystal clear answers. What we can say is that one score is larger than the other, which implies greater similarity to the user’s prompt.
How we choose the number of retrieved documents also depends on the use case and/or knowledge base. In our example, we set the number of retrieved documents to be five. This means that we will provide the model with five alternative contexts, which might contain meaningful information the model can use to generate its response to the user’s query. We are essentially allowing for the generation of less conservative responses later on, as the model is not restricted to just one piece of context.
It is important to note that the Vector Store Retriever node requires authentication to OpenAI’s API (via a flow variable) to be able to embed the user query and return the most similar documents.
Augment the prompt
Now that the five retrieved documents are available, we can move to the “Augmentation” step.
Here, we engineer a prompt that augments the original question with the retrieved context information. We also provide explicit instructions as to how the model should behave if it is not able to answer a question. We construct the prompt following the general best practices for prompt engineering and use the String Manipulation node to dynamically bring together the user’s query, the retrieved documents, and instructions for the model's behavior via flow variables (see figures below).

Generate responses
The last step is the “Generation” step, where our workflow generates a fact-based response.
We connect to ChatGPT with the OpenAI Chat Model Connector node and prompt the model with the LLM Prompter node to generate a response that takes the augmented query into account.
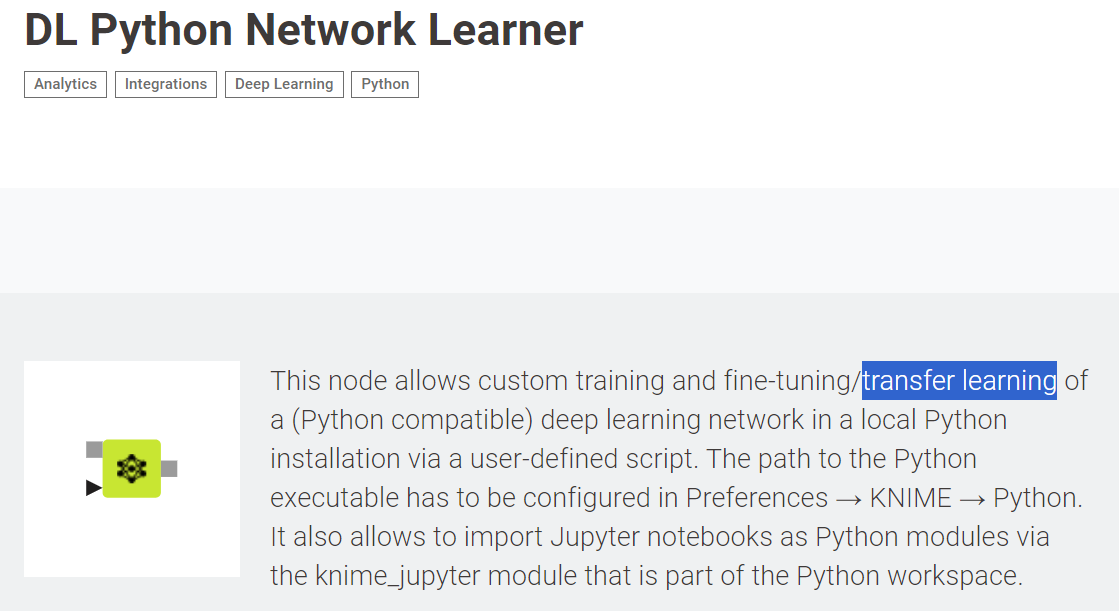
After applying RAG, the model response is wrapped in a component and displayed below. The response is now factually grounded. It points to the DL Python Network Learner node, which does exist. This indicates that we’ve succeeded in mitigating the risk of hallucination by providing the model with domain-specific information.
We can double-check the trustworthiness of the response by reading the documentation of the DL Python Network Learner node directly on the KNIME Community Hub.
Keep LLMs relevant with RAG
Retrieval augmented generation is very effective at injecting sense into LLMs.That’s why we use it in KNIME’s AI Assistant, K-AI to get more relevant responses from the LLMs behind K-AI. With the help of RAG, K-AI delivers responses that are not just accurate but also contextually rich and engaging. This ensures that K-AI not only comprehends user queries with precision but crafts responses that feel intuitive and tailored.