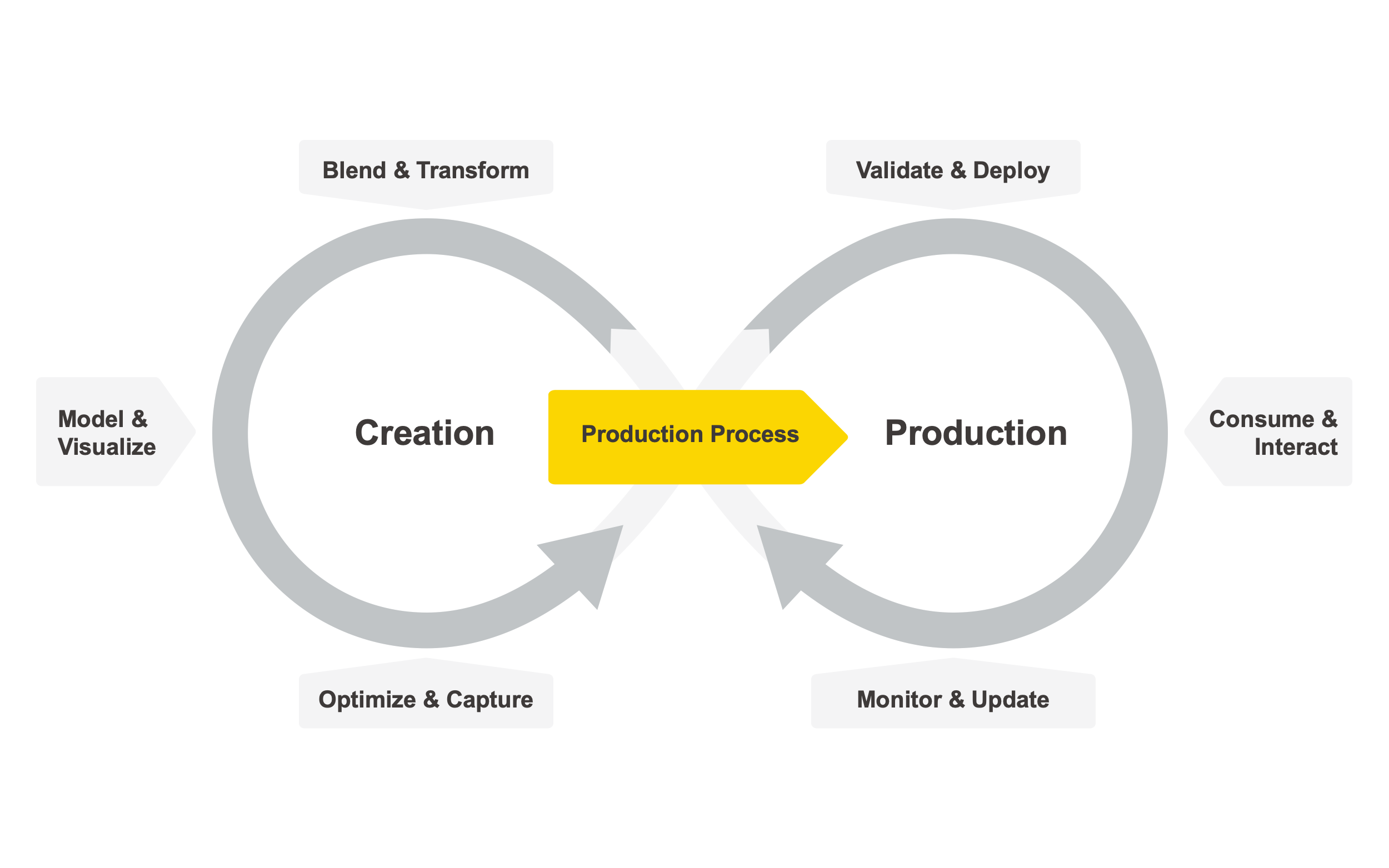
Welcome to our collection of articles about Integrated Deployment Blog, where we focus on solving the challenges around productionizing data science.
Topics include:
- Resolving the challenges of deploying production processes containing models
- Building guided analytics applications to control the training and deployment of machine learning, using KNIME’s component approach to AutoML to collaborate on projects
- Setting up an infrastructure to not only monitor but automatically update production workflows.
The key technique to solving many of these issues is Integrated Deployment and in this article, we explain that concept with practical examples.
Data Scientists, regardless of what package and techniques they use, are used to training models to solve business issues. The classic approaches to creating data science, such as CRISP-DM, support this approach, especially when adopting machine learning techniques. But the reality is that a trained model cannot be deployed by simply moving it from the local environment to the production environment. For a model to work, the data need to be prepared and surfaced to production in exactly the same way as when they were created. And there may be other aspects involved with the use of the model and the surfacing of results in the correct form that the model itself does not intrinsically have in it.
To date, that huge gap in the practice of moving from training to deploying production processes has been left to the user, regardless of whether you are using KNIME or another package such as Python. Effectively you have always needed to manually design two workflows- one to train your model and another to deploy it. With KNIME Analytics Platform 4.2, the production workflow can now be created automatically thanks to a new KNIME Extension: KNIME Integrated Deployment.
You will find an article that discusses the concept of Integrated Deployment, How to Move Data Science into Production. In this article we’d like to dive in a bit deeper for KNIME fans. To do that, we will look at two existing workflow examples of model training and model deployment. We will then redo them so that the first training workflow automatically creates the production workflow.
The training workflow and production workflow
The first workflow is the training workflow , used to access the available data, blending them in a single table, cleaning and removing all missing values as well as any other inconsistencies, applying domain expertise by creating new features, training models, optimizing, and validating them.
The second workflow is the production workflow which not only loads all the settings trained in the training workflow but builds the data preprocessing that the model expects. In many cases, the production workflow is not just a standalone KNIME workflow but is designed so that it can be called via REST API by an external application to create a super simple application to send new data as input and get back the model predictions via an http request.
In this example, we train a model to predict churn of existing customers given the stored data of previous customers. The training workflow accesses the data from a database and joins from an Excel file, the data is prepared by recomputing the domain of each column, converting a few columns from categorical to numerical and partitioning it in two sets, the training and the test set. A missing value imputation model is created based on the distribution of the training set, model optimization is performed to find the optimal parameters for random forest (e.g. number of trees) which is trained right after. The trained model is used to compute churn prediction on the test, which contains customers the model has never seen during training. Via an interactive view the threshold of the model is optimized and applied on the test set. The evaluation of the model is checked both with the former threshold and the new optimized one via confusion matrices. The missing value model and the random forest model are saved for the deployment workflow.
The overall KNIME training workflow is shown in Figure 1.
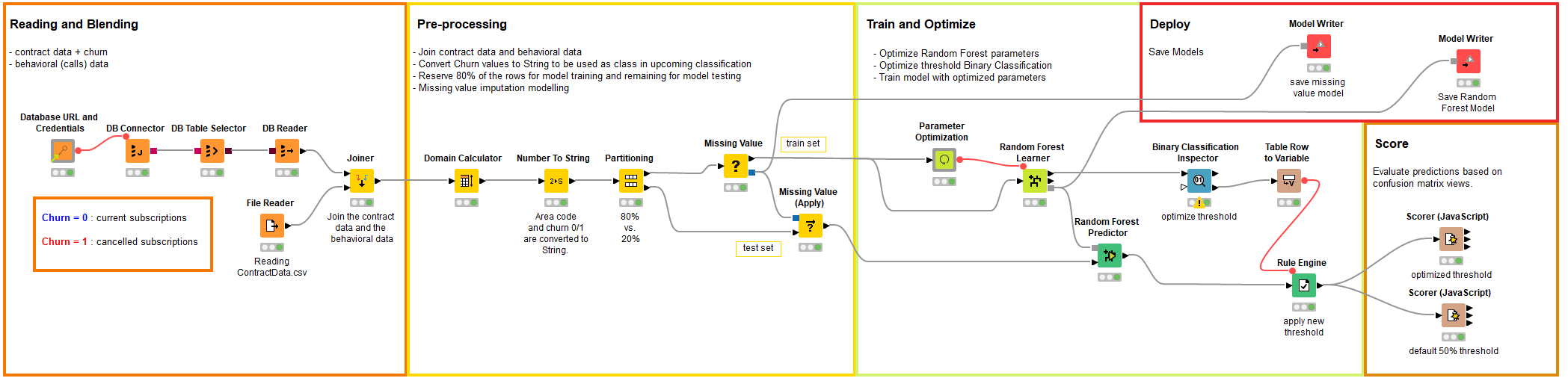
Figure 1 : The training workflow is created node by node by the user from data preparation all the way to model evaluation.
To deploy this simple churn prediction model (before KNIME Analytics Platform 4.2) the data scientists had to manually create a new workflow (Figure 2) and node by node rebuild the sequence of steps including manually duplicating the preparation of the raw data so that the previously created and stored models can be used.
This manual work requires the KNIME user to spend time to drag and drop again the same nodes that were already used in the training workflow . Additionally the user had to make sure the written model files could be found by the production workflow and that new data could come in and out of the production workflow via JSON format required by the REST API framework.
In this special case where the binary classification threshold was optimized, the data scientists even had to even manually type in the new threshold value.
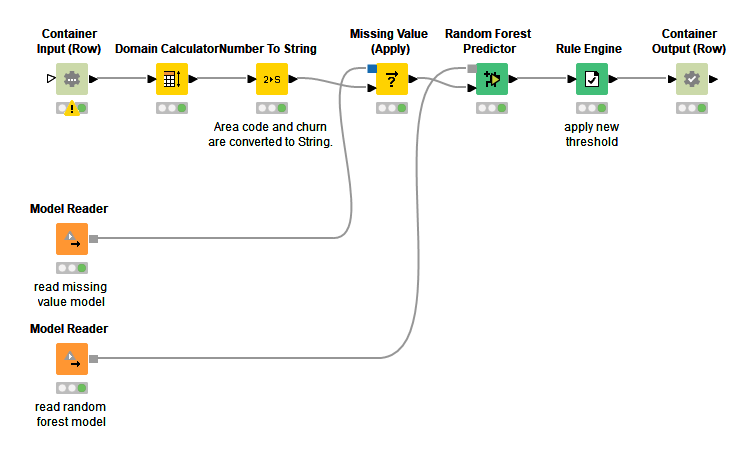
Figure 2. The production workflow created by hand before the release of Integrated Deployment. Again, many nodes are already used in the training workflow.
Integrated Deployment Enables Automatic Deployment from Training Workflow
Deployment using this manual setup was totally customary but time consuming. Whenever something had to be changed in the training workflow , the production workflow had to be updated manually. Consider for example training another model that is not random forest or adding another step in the data preparation part. Retraining the same model and redeploying it was possible, but automatically changing nodes was not.
- Integrated Deployment empowers you to deploy automatically from your training workflow
- How does the churn prediction training workflow look when Integrated Deployment is applied?
In Figure 3 you can see the same workflow as in Figure 1 with the exception that a few new nodes are used. These are the Capture nodes from the KNIME Integrated Deployment Extension. The data scientist can design the production workflow as she builds the training workflow by capturing the segments to be deployed. In this simple example only two segments of workflows are captured to be deployed - the data preparation and the scoring framed in purple in Figure 4. Any node input connection which does not come from the Capture Workflow Start is fixed as a parameter in the Deployment workflow . In this case the only dynamic input and output of the captured nodes is a data port specified in the Capture Workflow Start and End nodes. The two captured workflow segments are then combined via a Workflow Combiner node and the production workflow is automatically written on KNIME Server or in the local repository via a Workflow Writer node.
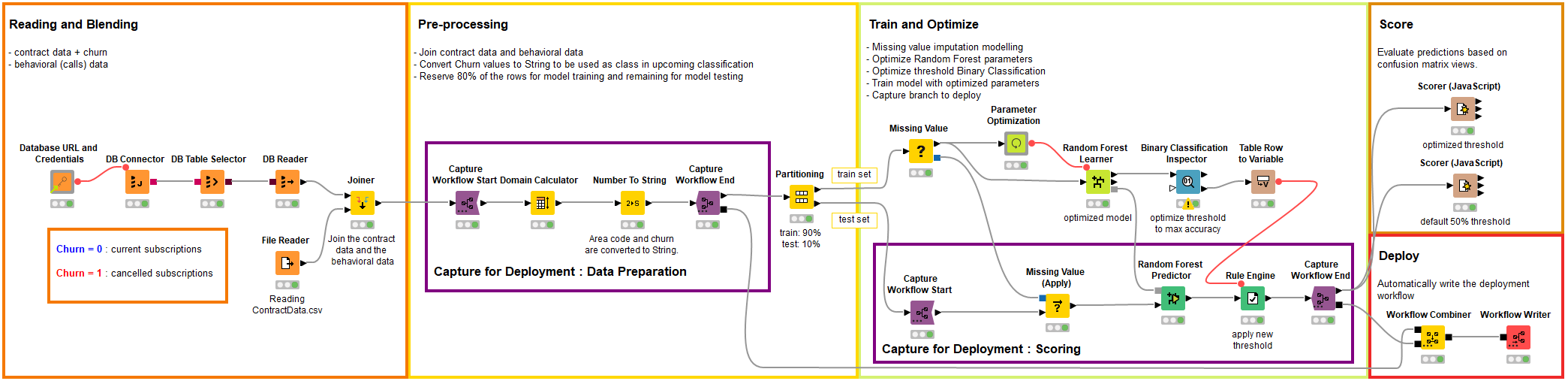
Figure 3: This time, the training workflow is created node by node by the data scientists from data preparation all the way to model deployment but includes the new KNIME Integrated Deployment Extension nodes.
It is important to emphasize that the Workflow Writer node has created a completely configured and functional production workflow.
In Figure 4 you can have a look at the automatically generated production workflow . All the connections that were not defined in the training workflow by the Capture Workflow Start and Capture Workflow End nodes are static and imported by the PortObject Reference Reader nodes. Those are generic reader nodes able to load the connection information of static parameters found during training. In Figure 4 the example production workflow is reading in three parameters: the missing value model, the random forest model and the double value to be used as binary classification threshold.
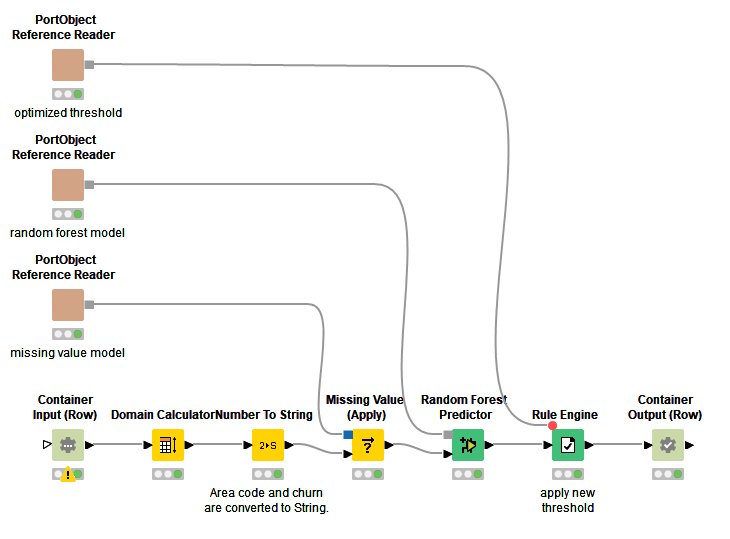
Figure 4: The production workflow automatically generated by Integrated Deployment.
In a scenario where data are prepared and models are trained and deployed in a routine fashion, integrated deployment becomes super useful for flexibly retraining and redeploying on the fly with updated settings. This can be fully automated by using the Deploy Workflow to Server node to generate the production workflows in the KNIME Server repository automatically. You can see an example of the new Deploy Workflow to Server node using a KNIME Server Connection in Figure 6.
In the animation the KNIME Executor is added, the Workflow Object, storing the captured production workflow, is connected to its input and via the dialogue the right amount of input and output ports are created. This setup offers a model agnostic framework necessary for machine learning interpretability applications such as LIME, shapley values, SHAP, etc.
Even if you do not have access to a KNIME Server, the Integrated Deployment Extension can be extremely useful when executing a piece of a workflow over and over again. Just imagine that you would like to test a workflow multiple times without having to copy the entire sequence of nodes on different branches. With the new Workflow Executor node you can reuse a captured workflow on the fly using the black box approach (Figure 5). This comes in extremely handy when working with the KNIME Machine Learning Interpretability Extension.
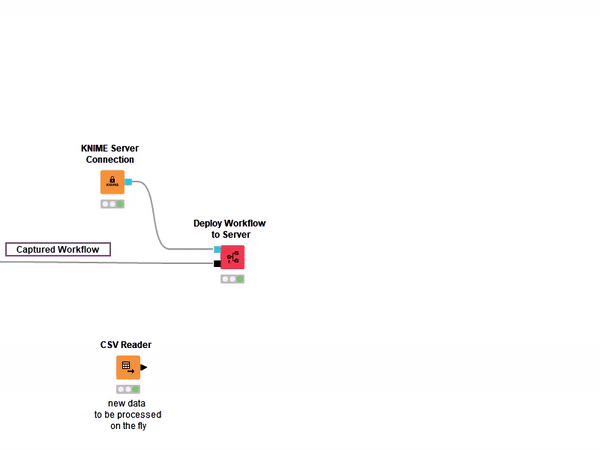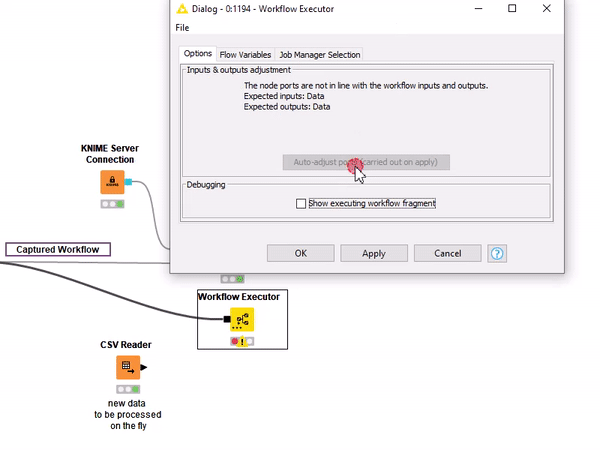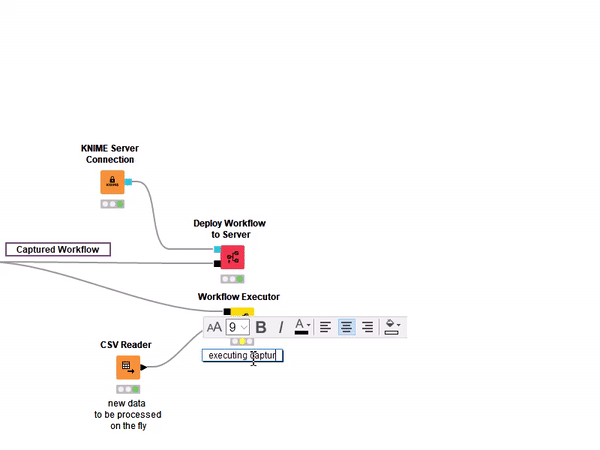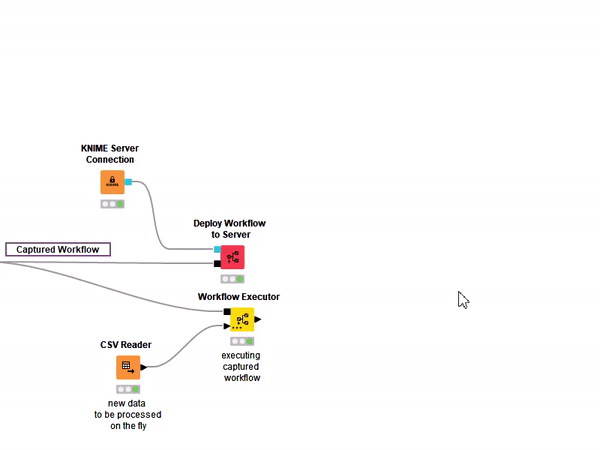
Figure 5: A workflow captured with the Integrated Deployment Extension can be deployed on a remote KNIME Server dependence, but also flexibly executed locally for testing purposes.
This introductory example is of course only a first demonstration of how Integrated Deployment enhances analytics workflows in KNIME. In further episodes we see how this extension empowers a KNIME expert to flexibility train, score, deploy, maintain and monitor machine learning models in an automated fashion!
The Integrated Deployment KNIME Blog Articles
Explore the collection of articles on the topic of Integrated Deployment.