
Marketing Analytics Solutions on the KNIME Hub
Many businesses are currently expanding their adoption of data science techniques to include machine learning. Marketing analytics is one of them. Anything can be reduced to numbers, including customer behavior and color perception, and therefore anything can be analyzed, modeled, and predicted.
Marketing analytics already involves a wide range of data collection and transformation techniques. Social media and web driven marketing have given a big push in the digitalization of the space; counting the number of visits, the number of likes, the minutes of viewing, the number of returning customers, and so on is common practice. However, we can move one level up and apply machine learning and statistics algorithms to the available data to get a better picture of not just the current but also the future situation.
Marketers can capitalize on machine learning techniques to analyze large datasets to identify patterns or perform predictive analytics. Examples include analyzing social media posts to see what customers are saying, analyzing images to extract insight into pictorials and videos, or predicting customer churn – to name just three.
In the Machine Learning and Marketing space on the KNIME Hub, you will find a number of case studies applying machine learning algorithms to classic marketing problems.
In this post, we will describe these case studies, one by one, showing the particularity of each one of them and the insights they bring. So far, we have solutions for:
-
Measuring Sentiment Analysis in Social Media
-
Evaluation of Customer Experience through Topic Models
We will continue to maintain this repository by updating the existing workflows and adding new ones every time a solution from a new project becomes available.
Note. This solution repository has been designed, implemented, and maintained by a mixed team of KNIME users and marketing experts from the KNIME Evangelism Team in Constance (Germany), headed by Rosaria Silipo, and Francisco Villaroel Ordenes, Professor of Marketing at LUISS Guido Carli university in Rome (Italy).
Reference scientific article: F. Villarroel Ordenes & R. Silipo, “Machine learning for marketing on the KNIME Hub: The development of a live repository for marketing applications”, Journal of Business Research 137(1):393-410, DOI: 10.1016/j.jbusres.2021.08.036.
Prediction of Customer Churn
Using existing customer data (e.g., transactional, psychographic, attitudinal), predictive churn models aim to classify customers who have churned or remained, as well as estimate the probability of new customers to churn, all in an automated process. If the churn probability is very high and the customer is valuable, the firm might want to undertake actions to prevent this churn.
The “Churn Prediction” folder in the Machine Learning and Marketing space on the KNIME Hub includes:
-
A workflow training a ML classifier (a random forest in this case) to distinguish customers who have churned and customers who have stayed in the training set.
-
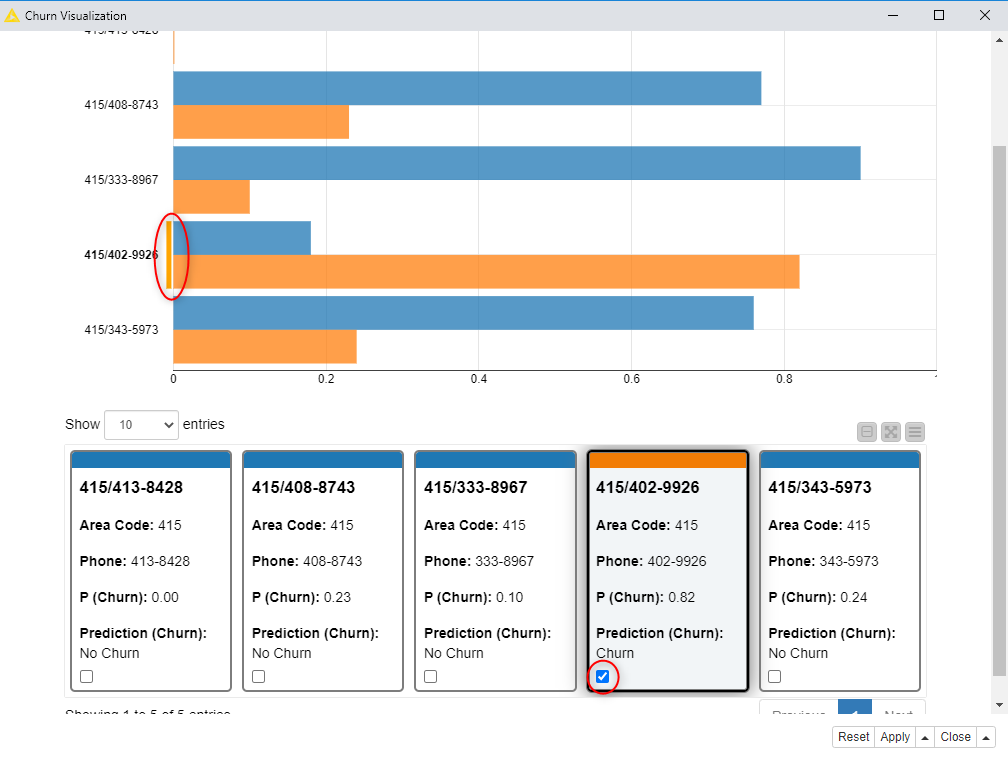
A deployment workflow applying the previously trained model to new customers, estimating their current probability to churn, and displaying the result on a simple dashboard (Fig. 2).
Sentiment Analysis
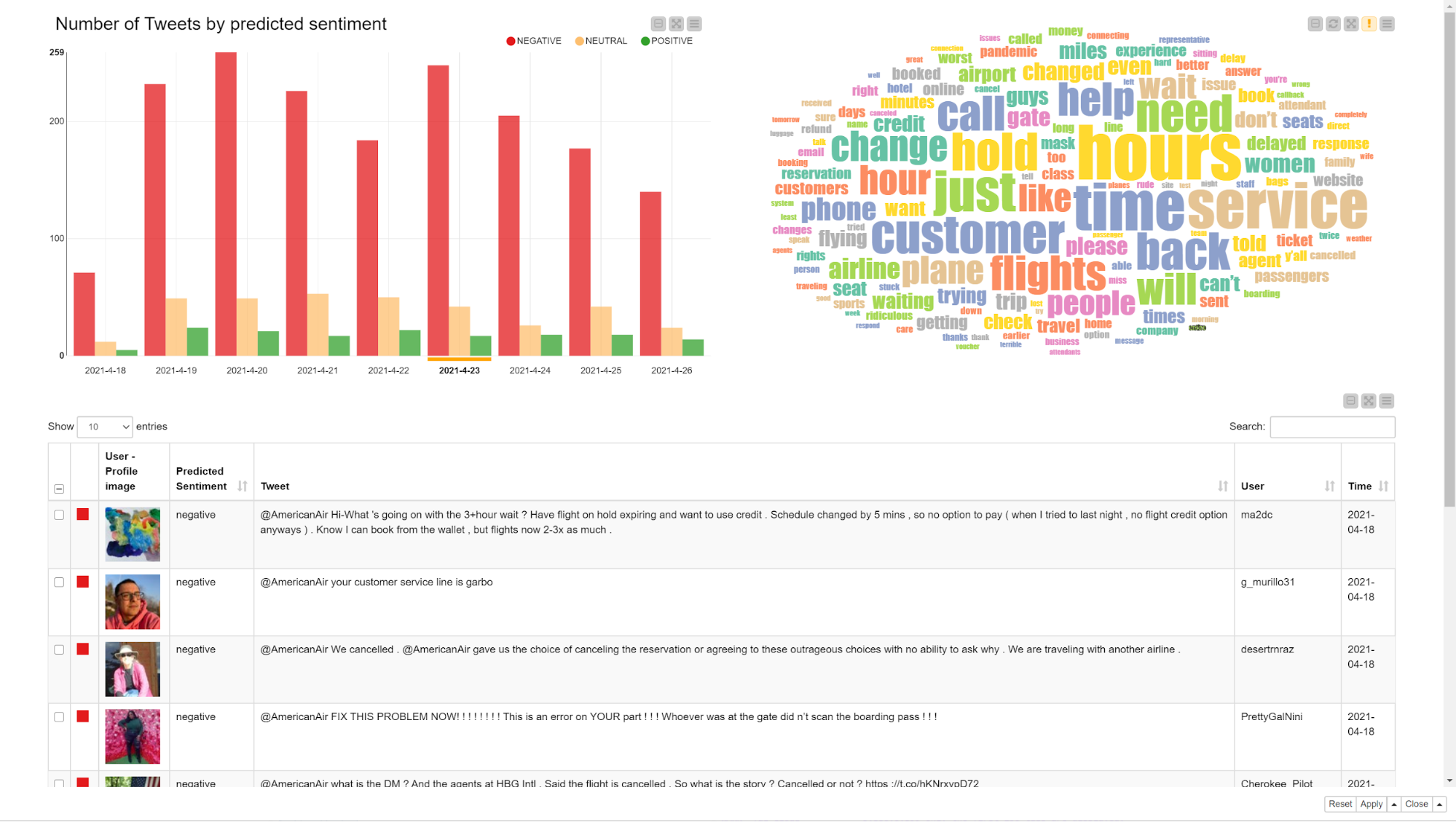
Sentiment is another popular metric used in marketing to evaluate the reactions of users and customers to a given initiative, product, event, etc. Following the popularity of this topic, we have dedicated a few solutions to the implementation of a sentiment evaluator for text documents. Such solutions are contained in the “Sentiment Analysis” folder. All solutions focus on three sentiment classes: positive, negative, and neutral.
There are two main approaches to the problem of sentiment:
-
Lexicon based. Here, a list of positive and a list of negative words (dictionaries), related to the corpus topics, are compiled and grammar rules are applied to estimate the polarity of a given text. Learn how to build a sentiment predictor using lexicon-based sentiment analysis.
-
Machine Learning based. The solutions here rely on no rules, but on machine learning models. Supervised models are trained to distinguish between negative, positive, and neutral texts and then applied to new texts to estimate their polarity.
Machine-learning-based approaches have become more and more popular, mainly because of their capability to bypass all grammar rules that would need hard-coding. Among the machine learning based solutions, a few options are possible:
-
Traditional machine learning algorithms. In this case, texts are transformed into numerical vectors, where each unit represents the presence/absence or the frequency of a given word from the corpus dictionary. After that, traditional machine learning algorithms, such as random forest, Support Vector Machine, or Logistic Regression can be applied to classify the text polarity. Notice that in the vectorization process the order of the word in the text is not preserved. Read more in this tutorial for machine learning for sentiment analysis.
-
Deep Learning based. Deep learning based solutions are becoming more and more popular for sentiment analysis, since some deep learning architectures can exploit the word context (i.e. the sequence history) for better sentiment estimation. In this case, texts are one-hot encoded into vectors, the sequence of such vectors is presented to the neural network, and the network is trained to recognize the text polarity. Often, the architecture of the neural network includes a layer of Long Short Term Memory units (LSTM), since LSTM performs the task by taking into account the order of appearance of the input vectors (the words), that is by taking into account the word context. Explore a tutorial to set up a deep learning approach to sentiment analysis.
-
Language models. They are also referred to as deep contextualized language models, because they reflect the context-dependent meaning of words. It has been argued that these methods are more efficient than recurrent neural networks because they allow parallelized encoding (rather than sequential) of word and sub-word tokens contingent on their context. Recent language model algorithms are ULMFiT, BERT, RoBERTa, XLNet. In the Machine Learning repository, we provide a straightforward implementation of BERT. See how to use BERT with KNIME in this sentiment analysis tutorial.
Find an example of all these solution groups in the “Sentiment Analysis” folder in the Machine Learning and Marketing space.
Topic Detection and Customer Experience
Customer experience management and the customer journey is one of the most popular marketing topics in the marketing industry. A lot of information about customer experience comes from the reviews and feedback and/or from the star-ranking systems on websites and social media.
The popularity of topic models has resulted in a continuous development of algorithms such as Latent Dirichlet Allocation (LDA), Correlated Topic Models (CTM), and Structural Topic Models (STM), among others, all of them already implemented in business research. LDA is available in the KNIME Text Processing extension as a KNIME native node. The LDA node detects m topics in the whole corpus and describes each one of them using n keywords, m and n being some of the parameters required to run the algorithm.
You’ll find an example workflow, showing the usefulness of discovering topics in reviews, in the folder “CX and Topic Models” in the Machine Learning and Marketing space.
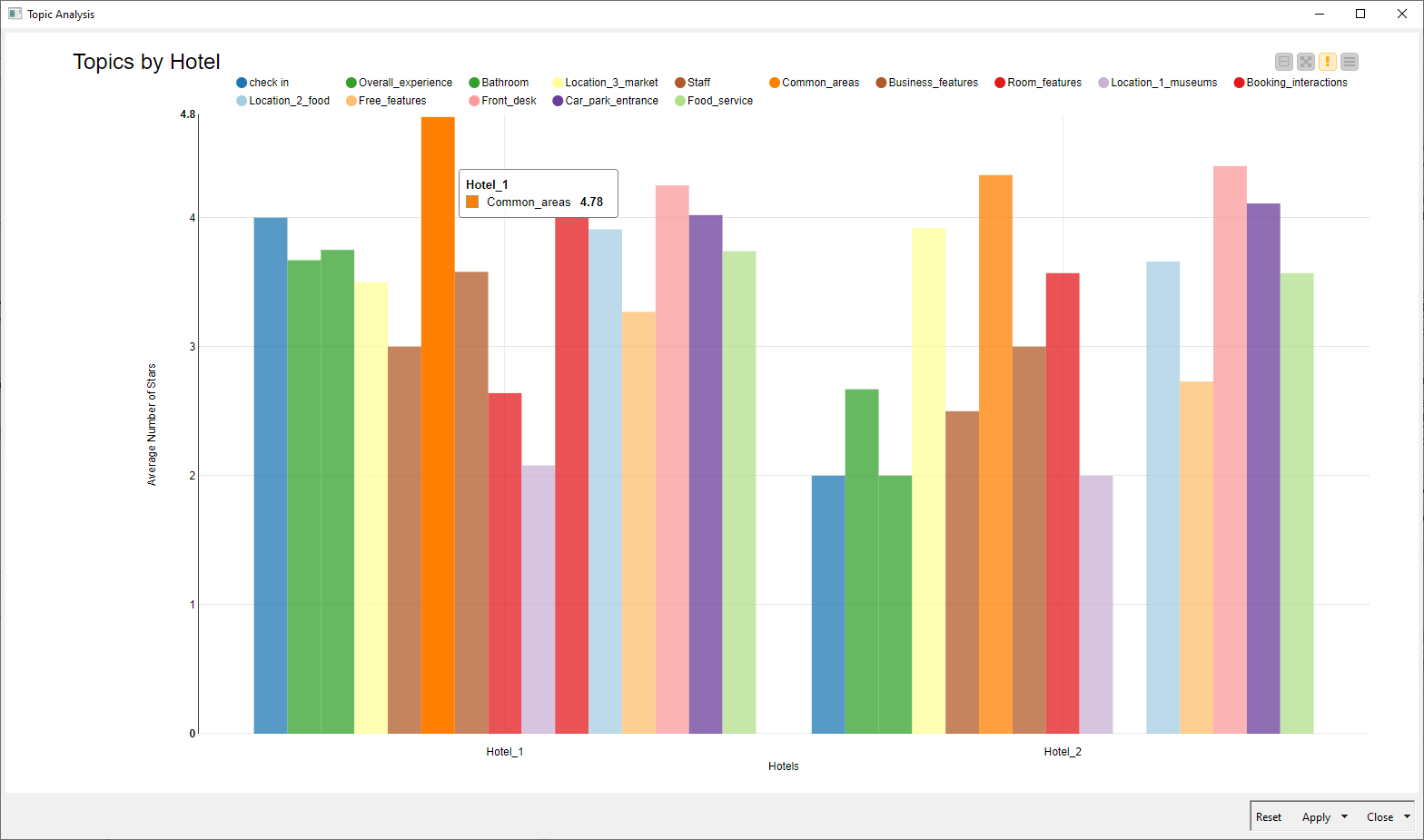
The workflow extracts topics from reviews using the LDA algorithm. After that it estimates the importance of each topic via the coefficients of a linear regression – implemented with a KNIME native node – and via the coefficients of a polynomial regression – implemented in an R script within the KNIME workflow. It then displays the average number of stars for all topics extracted from the reviews for two different hotels (Fig. 4).
In the bar chart for instance, we can see that for hotel 2 the topic “booking Interactions” is never mentioned. We can also notice that while hotel 1 gets great reviews for the “common areas”, hotel 2 excels for the “Front desk”.
Content Marketing and Image Mining
The last ten years have shown an exponential growth of visual data including images and videos. This growth has resulted in an increasing development of technologies to classify and extract relevant insight from images. This phenomenon has had an impact on marketing as well. As both consumers and firms are relying more on pictorials and videos to communicate, researchers need new processes and methods to analyze this type of data.
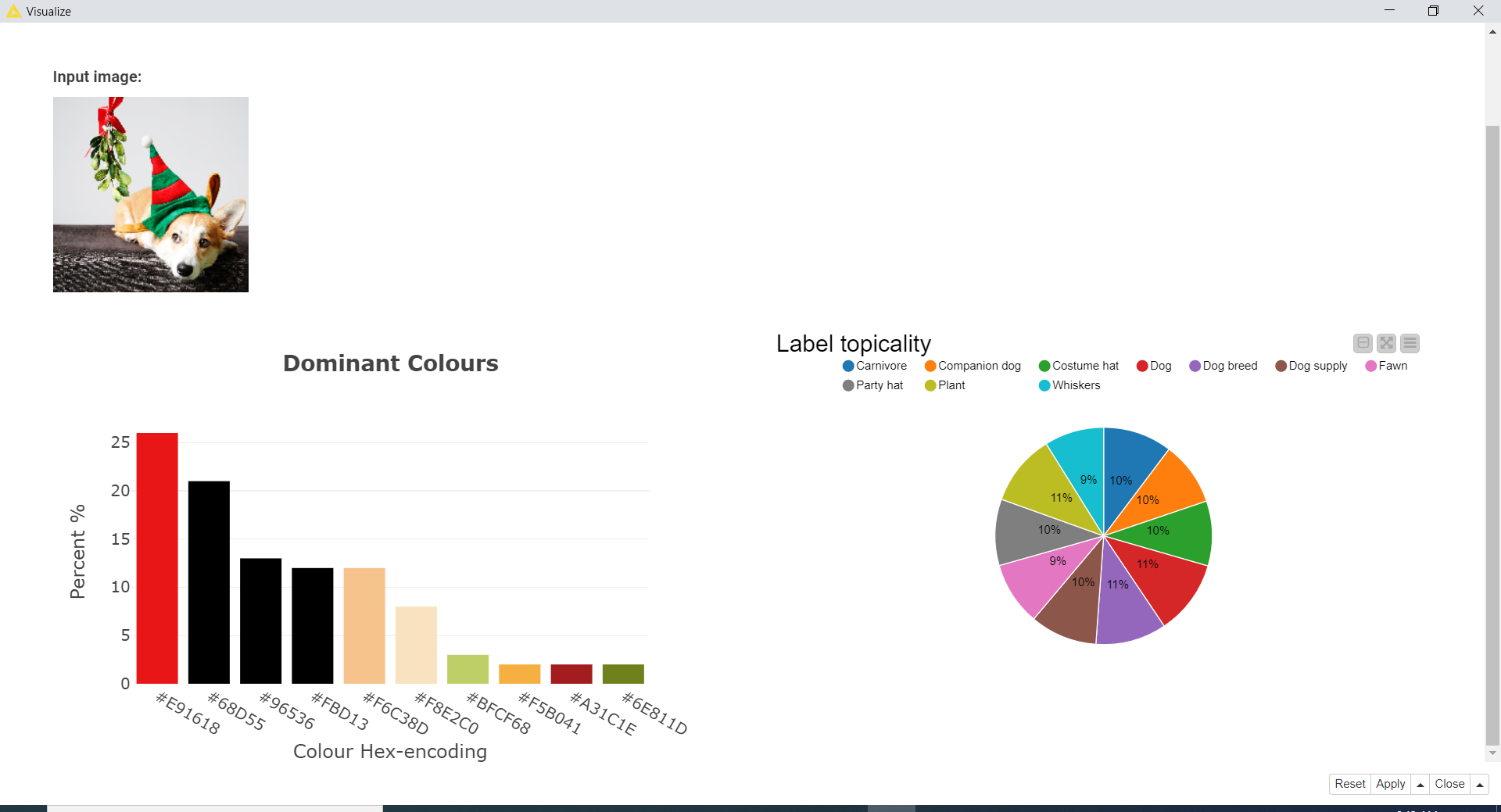
The greater interest in the analysis of visuals and its implications for firm performance, motivated us to develop a workflow that can help with the analysis of visual content. The workflow takes advantage of Google Cloud Vision services (accessed via POST Request), to detect labels (e.g., humans) and extract nuanced image properties such as color concentration.
A second workflow uses deep learning Convolutional Neural Networks to classify images of cats vs. dogs. Changing the image dataset and correspondingly adjusting the network, allows you to implement any other image classification task.
Find both workflows in the folder “Image Analysis” of the Machine Learning and Marketing space. Figure 5 shows the result obtained from the analysis of an image via Google Cloud Vision services.
Keyword Research for SEO
It is known that search engines rank web pages according to the presence of specific keywords or groups of keywords conceptually and/or semantically related. In addition, keywords should be taken from the specialized lingo by experts as well as from the conversational language by neophytes. Popular sources for such keywords are SERP (Search Engine Result Pages) as well as social media.
In the “SEO” folder of the Machine Learning and Marketing space, you’ll find a workflow for semantic keyword research, implemented following the article “Semantic Keyword Research with KNIME and Social Media Data Mining – #BrightonSEO 2015” written by Shapiro in 2015.
The upper branch of the workflow connects to Twitter and extracts the latest tweets around a selected hashtag. The lower branch connects to Google Analytics API and extracts SERPs around a given search term. After that, URLs are isolated, web pages scraped via GET Requests to Boilerpipe API, and keywords are extracted together with their frequencies.
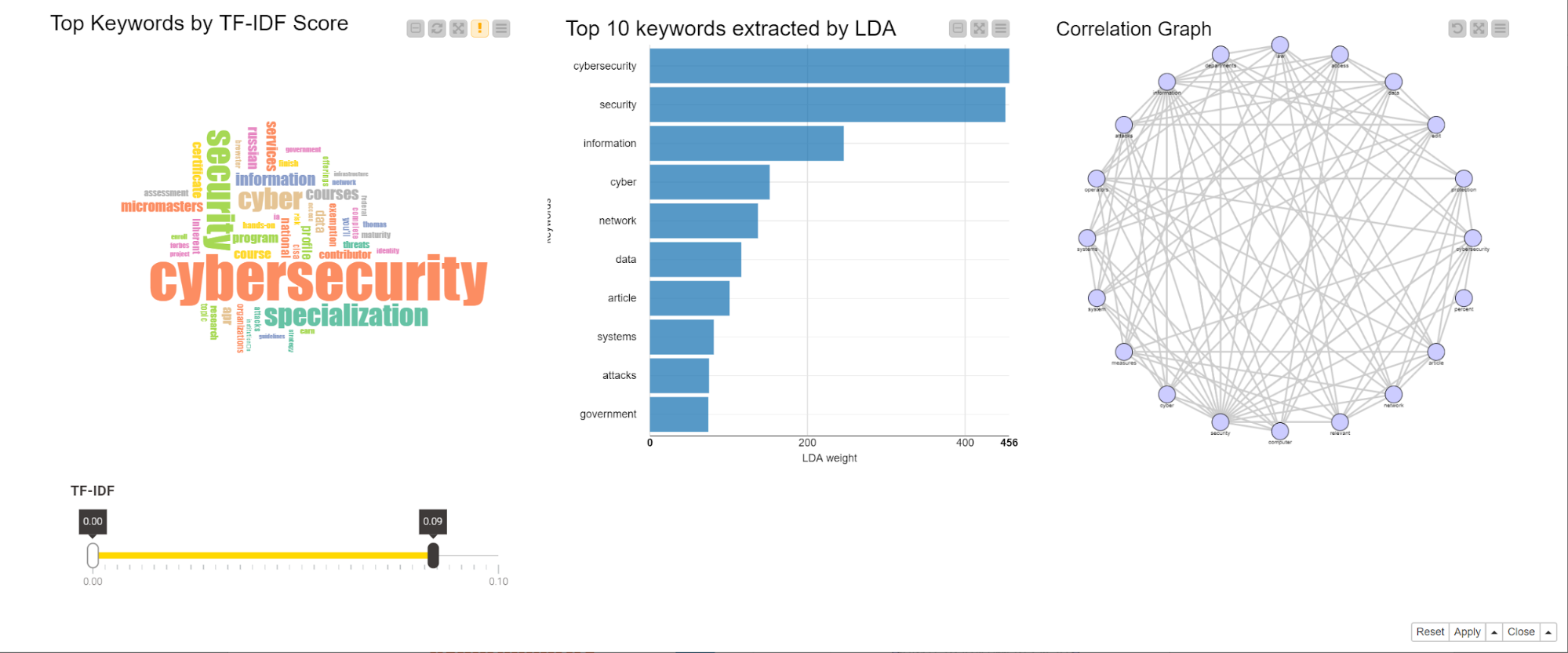
Keywords as: single terms with highest TF-IDF score; co-occurring terms with highest co-occurring frequency; keywords with highest score from topics detected via the Latent Dirichlet Allocation (LDA) algorithm.
As an example, we searched for tweets and Google SERPs around “cybersecurity”. Resulting co-occurring keywords are shown in the word cloud in Fig. 6 If you are working in the field of cybersecurity, then including these words in your web page should increase your page ranking.
Explore Machine Learning and Marketing Examples with KNIME
With this article we wanted to announce the availability of a public repository on the KNIME Hub, named “Machine Learning and Marketing” (Fig. 1), for marketing analysts. A mixed team of KNIME users from industry and academia has created, developed, and maintained, some machine learning based solutions for a few commonly used interesting use cases in marketing analytics: churn prediction, sentiment analysis, topic detection to evaluate customer experience, image mining, and keyword research for Search Engine Optimization.
All workflows are available for free. They represent a first sketch to solve the problem but can of course be downloaded and customized according to your own business requirements and data specs.
Try the free and open source KNIME Analytics Platform and play around with the workflows described in this post. Download KNIME to do so!
--------
Referenced scientific article: F. Villarroel Ordenes & R. Silipo, “Machine learning for marketing on the KNIME Hub: The development of a live repository for marketing applications”, Journal of Business Research 137(1):393-410, DOI: 10.1016/j.jbusres.2021.08.036.