
KNIME Analytics Platform follows a graphical programming paradigm, which, in addition to clearly expressing the steps taken to process your data, also allows rapid prototyping of ideas. The benefit of rapid prototyping is that you can quickly test an idea and prove the business value of that idea practically.
Once you’ve shown that business value, you may deploy the workflow to run regularly on KNIME Business Hub.
Below I’ve highlighted some of the tips and tricks I’ve learned from KNIMErs that might help speed up the execution of some of your workflows. Read on to learn more.
Performance extensions
KNIME provides performance extensions such as the KNIME Big Data Connectors for executing Hive queries on Hadoop, or the KNIME Extension for Apache Spark for training models on Hadoop using Apache Spark. But sometimes it doesn’t make sense to run your analytics on a Big Data cluster. The KNIME Cloud Analytics Platform for Azure, which allows you to execute your KNIME workflows on demand, on an Azure VM with up to 448GB RAM and 32 cores. This is one easy way to boost the performance of some of your workflows.
But there are more tips and tricks that you can use to speed up execution of your workflows!
Optimization tips
Optimize your knime.ini
The knime.ini file sets many options that are used by the Java Virtual Machine when KNIME Analytics Platform is launched. We keep the file deliberately simple in order to maximize compatibility across the wide variety of operating systems, and machine specifications that are used to run KNIME Analytics Platform. However, there are a few special options that you might want to set.
- -Xmx<memory>g: Editing the line that is present in the knime.ini by default allows you to specify how much RAM KNIME Analytics Platform is allowed to use. If you are only using KNIME Analytics Platform and have 8 GB RAM available, then you can probably set this to 6 GB. If, however, you also want to use office applications, a web browser, a code editor and more, you may need to be more conservative and set a lower value to leave some RAM for the other applications.
- By default, all KNIME nodes have the option ‘Keep only small tables in memory’ set.
The default for ‘small tables’ is a table with fewer than 100,000 elements (e.g. fewer than 10 columns, 10,000 rows). The number of cells retained in memory can be modified by altering the knime.ini file by adding the following option to the end of the file - Dorg.knime.container.cellsinmemory=10000000
Increasing the number of elements retained in memory may improve performance by limiting swaps to disk in the case where very large tables are being processed. However, if you have limited the available RAM you may be better to not change this option. Note that KNIME uses an in-built memory monitor and forces tables to disk if memory becomes limited (also for ‘Keep all in memory’). It’s not recommended to keep all data in memory as this will limit the amount that is needed to perform operations and run algorithms such as sorting or model building. There is of course an exception, for nodes that precede nodes requiring multiple scans over the data (such as k-means or neural network learner) can have the “Keep all in Memory” set as the learner nodes will then read from memory as opposed to disk. - KNIME saves temporary data in a compressed format to save disk space. Compression rates vary very much depending on the repetition level in the data and the type of data. You can switch off compression entirely by adding –Dknime.compress.io=false to the knime.ini file. For simple operations such as reading some data, doing some simple processing and outputting the results this may result in good performance gains at the expense of temporary disk space. For more elaborate workflows this impact will be less evident.
Focus your efforts
The ‘Timer Info’ node allows you to see which nodes require the most time to execute. This is of course a great help in deciding which parts of the workflow could benefit the most from some optimization.
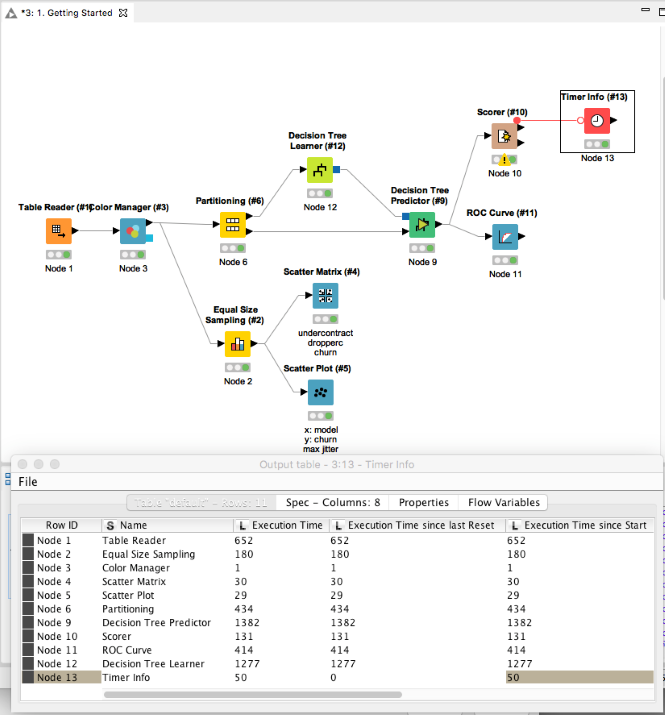
In this example we can see that the decision tree predictor and decision tree learner take the most time 1382 and 1277 ms respectively to execute. This is not unexpected, and here we don’t need to consider any optimization.
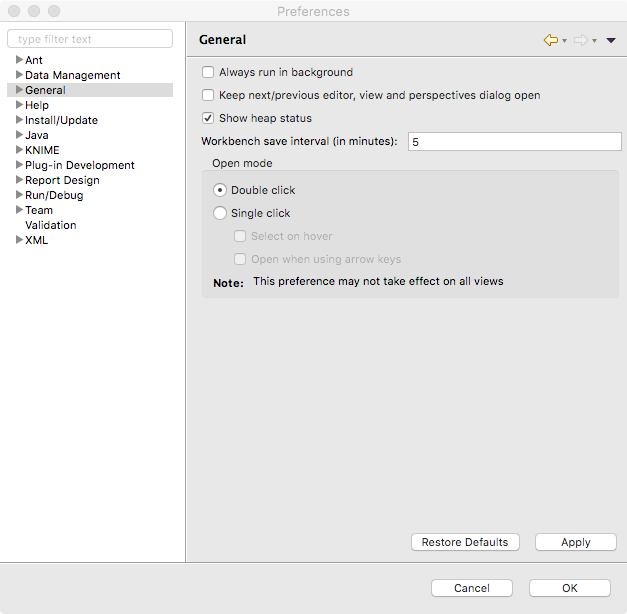
It is also possible to check how much memory KNIME Analytics Platform is using. If you notice that you have heavy memory usage, you may wish to refer to the previous section ‘Optimize your knime.ini’ to learn how to increase the memory available to KNIME Analytics Platform. In order to monitor memory usage, go to File > Preferences, and check the ‘Show heap status’ option.
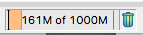
The bottom right-hand corner of the Analytics Platform now shows how much of the available RAM is being used. In this case 161MB of a total 1000MB.
Use the KNIME simple streaming executor
Streaming execution is another way to execute nodes and is different to the default "node-by-node" execution. Benefits are less I/O and faster runtime at the expense of limited ability to inspect intermediate results and traceability. Nodes that are streamable are executed concurrently. There is an example workflow showcasing this functionality in the Node Guide. Furthermore there is a YouTube video on the KNIMETV channel that shows how streaming can be enabled.
Efficient workflow design patterns
Do as much as possible in database
Databases are optimized for performing operations like Row Filters and Joins. KNIME Analytics Platform gives you the flexibility to choose at what point, and where you perform those operations. The database nodes execute SQL queries in database, meaning that complex joins, filters, and sorts can be performed optimally. After these operations the interesting data that remains can be transferred into KNIME Analytics Platform to build your Advanced Analytics models.
In case you’re using Apache Spark (via the KNIME Extension for Apache Spark performance extension), it is even possible to build the models in database, meaning that your data remains in place, and the analytics are brought to it. In many cases this will improve performance by limiting the amount of data that is needed to be transferred from one place to another.
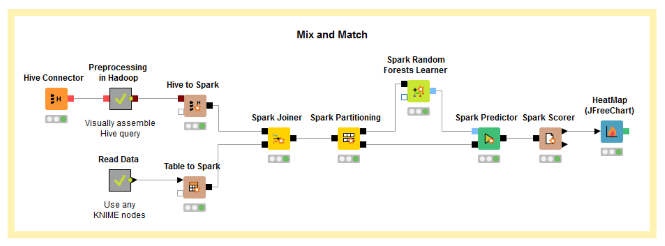
Cache data where possible
In computing, a cache is a store of data so that future requests for that data can be dealt with faster. A typical workflow might train a model, and then use that to make a prediction. Typically, the model training can take a long time in comparison to the application of the model (making a prediction). Therefore, we may choose to split the workflow into two. The first workflow loads the input data, trains a model, and then saves to disk (using e.g. the ‘Model writer’ or ‘PMML writer’ nodes). The second workflow can then read the model file in once, and then the rest of the workflow can be executed multiple times.
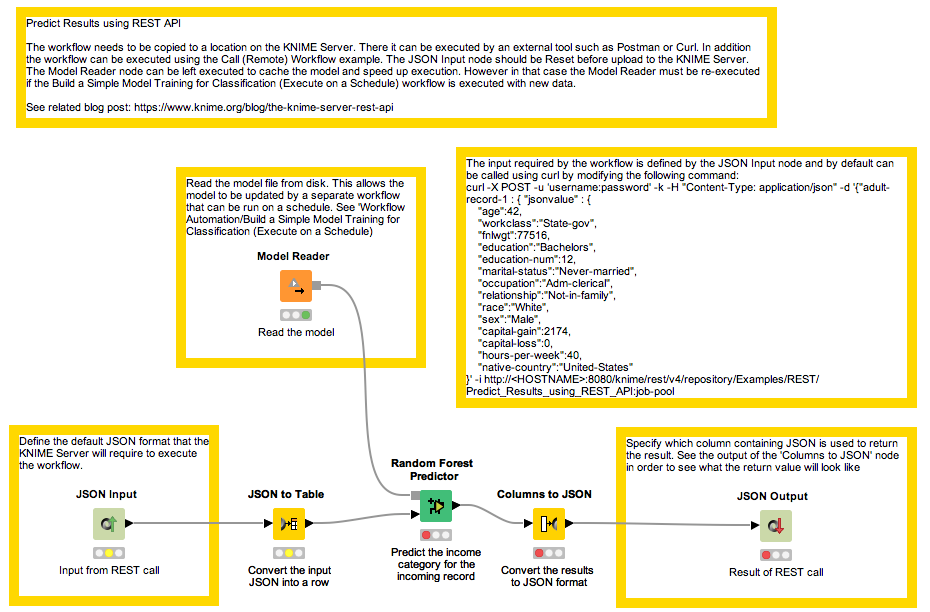
(click on the image to see it in full size)
Use Java snippet instead of Python/R snippet
Using the Python or R snippet nodes in KNIME Analytics Platform allows for hundreds of powerful libraries to be accessed, bringing in even more data analytics power to the Analytics Platform. It also allows the workflow developer to use their preferred programming language. However, there is no escaping that keeping the data within the Java Virtual Machine, and using the Java Snippet node is the most efficient way to process your data programmatically from within KNIME Analytics Platform.
The Python Script (Labs) node, which is part of the KNIME Python Integration (Labs) makes Python just as fast in KNIME as it is anywhere else. The API offered through the Labs extension boosts performance transferring data between KNIME and Python. Find out more in an article about the fast data transfer between KNIME and Python.
Node specific optimizations
The node specific optimization options are limited to a few nodes that are used very frequently, and have the potential to give you some nice performance boosts when used in the right cases.
Avoid repeating operations
Nodes like GroupBy and Pivot sort the data, therefore putting a sorter node immediately afterwards is not necessary.
Enable the 'process in memory' option for GroupBy and Pivot
Enabling the ‘process in memory’ option for GroupBy and Pivot can be memory hungry, but if you’ve got a machine with plenty of RAM, then you’ll be able to see a performance improvement when executing these nodes.
Column Appender and Cell Replacer can be faster than the Joiner
The Column Appender is faster than the joiner if you deactivate the rowids option.
If the row keys in both input tables exactly match (i.e. the row key names, their order, and their number have to match) this option can be checked in order to allow a faster execution with less memory consumption. However, if the row keys (names, order, number) don't match exactly the node execution will fail.
The Cell Replacer is more appropriate for simple replacement tasks than the Joiner.
In a database system you would usually use a ‘join’ to do replacements in a table column. In KNIME this is possible also, though the Cell Replacer node is a faster alternative for the specific use case where you want to replace the content of a column based on a dictionary or lookup table. It will cache the dictionary in memory and perform a single scan on your table.