As a software developer, managing lengthy Jira issue tickets is a tedious but important part of your job. This tutorial shows how you can make an AI summarizer that will automatically extract the specific ticket data you need to address critical ticket issues quickly. Learn how you can automate the generation of clear, concise summaries of issue tickets with GenAI and KNIME Analytics Platform.
KNIME is a data science tool where you use visual workflows to build your applications. It’s open source and free to use.
This blog series on Summarize with GenAI showcases a collection of KNIME workflows designed to access data from various sources (e.g., Box, Zendesk, Jira, Google Drive, etc.) and deliver concise, actionable summaries.
Here’s a 1-minute video that gives you a quick overview of the workflow. You can download the example workflow here, to follow along as we go through the tutorial.
Let’s get started.
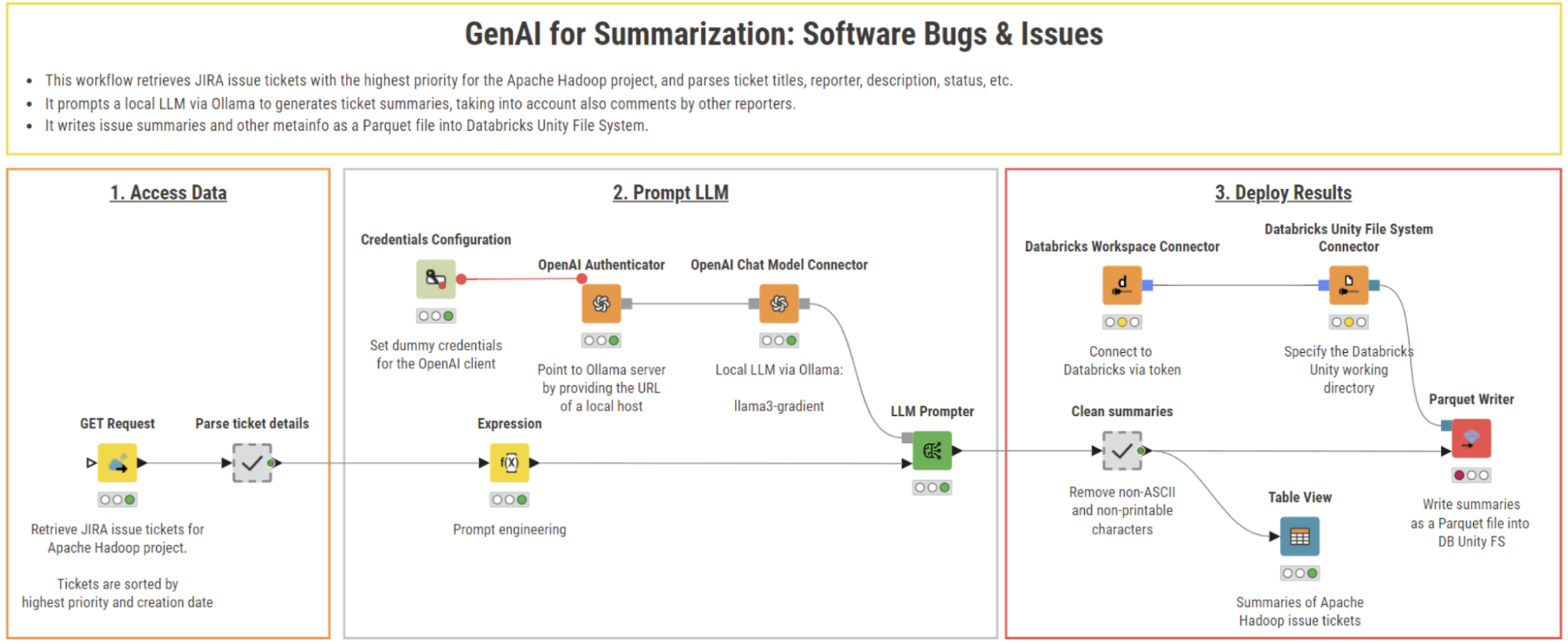
Automate JIRA ticket summarization and storage with a visual workflow
The goal of our solution is to enable you to save time spent on manually reviewing ticket details and ensure that no key information is lost, such as ticket title, date, descriptions, and reporter comments.
We can do this in three steps:
- Retrieve JIRA issue tickets with the highest priority from the Apache Hadoop project
- Summarize them using a local LLM sourced from Ollama
- Store the summaries as a Parquet file into a Databricks Unity File System
This provides an efficient and convenient way to streamline reviewing and storage of software bug tickets.
Step 1. Access data: Retrieve JIRA tickets from Apache Hadoop
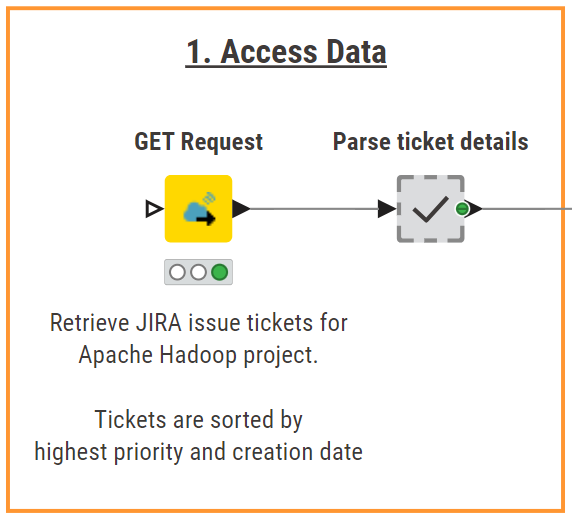
The first step is to retrieve high-priority tickets for the Apache Hadoop project using the JIRA API. To call the API, we use the GET Request node and pass as input the following URL:
This URL allows us to search the tickets listed in the Apache Hadoop project (i.e., project ID: HDFS) and retrieve a max of 50 tickets sorted by priority (critical tickets first) and creation date (more recent first).
Next, in the “Parse ticket details” metanode, we use the JSON Path node to extract relevant details such as the ticket ID, title, type, priority, description, and status. We also filter out tickets, whose status is “Resolved”.
We then perform a second GET request call, this time using the ID of each ticket. In this way, we can retrieve and parse the ticket reporter name and any potential comments to the ticket left by other developers. The final result is a structured and exhaustive dataset that serves as the input for the summarization stage.
Step 2. Prompt LLM: Summarize tickets with a local Gradient’s Llama3-gradient
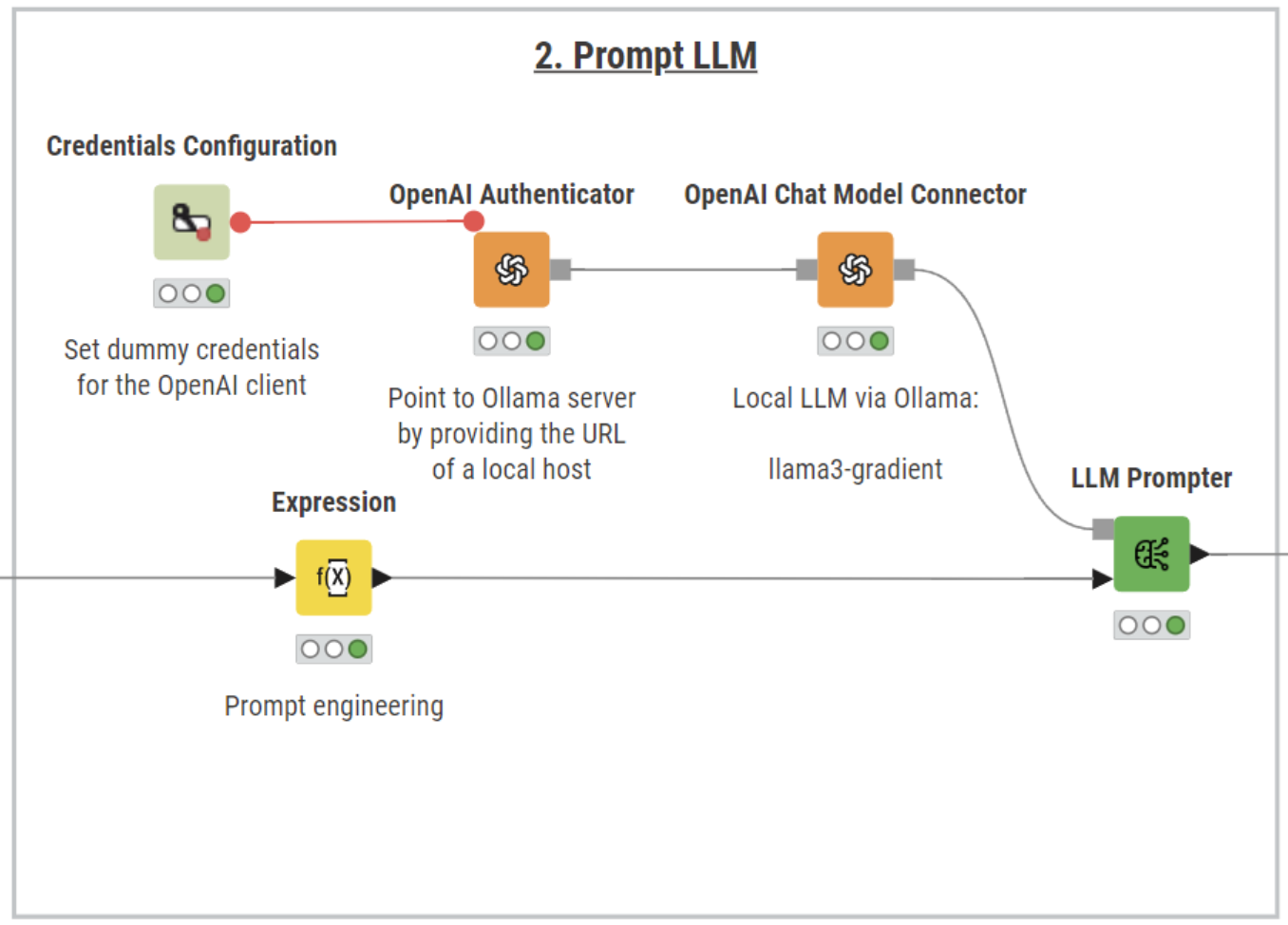
To summarize Hadoop tickets, we’re going to use KNIME’s AI extension and pick the best-fit LLM for the task, balancing costs, performance, and concerns over data privacy. In our example, we connected to Gradient’s Llama3-gradient, which is available for free and can run locally on our machine.
In KNIME, we can leverage Ollama models using the OpenAI nodes.
To set up the connection:
- Download Llama3-gradient from Ollama
- Input dummy credentials in the Credentials Configuration node
- Authenticate to Ollama server with the OpenAI Authenticator node providing the URL of a local host: http://localhost:11434/v1
- Use the OpenAI Chat Model Connector node to connect to Llama3-gradient. Switch to the “All models” tab and select the model in the dropdown menu
Next, we perform prompt engineering using the Expression node. We assign a persona to the LLM, instructing it to act as a developer working with software issues. This technique, combined with clear structuring of ticket details and extensive context, helps the model deliver responses that meet more closely the user’s expectations.
The prompt also leverages the LLM's multilingual capabilities by requesting translations for non-English tickets, ensuring summaries are output consistently in one language and streamlining reviewing. Here’s the prompt we used:
join("\n\n", "Act as a developer who works with software issues. Each ticket contains the following information:",
join("", "-Issue reported by: ", $["reporter_name"]),
join("", "-Ticket title: ", $["title"]), join("", "-Ticket description: ",$["descriptions"]),
join("", "-Comments to ticket: ", $["comments"]),
"Summarize concisely and accurately the issue described in the ticket. Avoid repetitions and do not exceed the allocated number of tokens.
If the information in the ticket is not in English, translate it first and then summarize it concisely.")
Lastly, the LLM Prompter node queries the model to generate concise and informative summaries, combining ticket descriptions and metadata with key insights from reporters’ comments for a complete overview of each issue.
Step 3. Deploy results: Write ticket summaries as a Parquet file to Databricks

Databricks, ensuring efficient storage and scalability for further analysis.
The final stage involves cleaning and storing the summarized ticket data.
The “Clean Summaries” metanode prepares the data for display by removing non-ASCII and non-printable characters, and wrapping text, ensuring summaries are clearly formatted and easy to read. Additionally, each summary includes the link to the full ticket on JIRA for deeper reading and investigation.
Next, we store the ticket summaries as a Parquet file on Databricks using the KNIME Extension for Big Data File Formats and the KNIME Databricks Integration. Parquet is a columnar storage file format optimized for big data processing, offering efficient compression and faster query performance compared to row-based formats. By storing summaries as a Parquet file, we ensure the data is compact, easy to query, and scalable for advanced analytics.
To connect to a Databricks workspace, we drag and drop the Databricks Workspace Connector node, providing a workspace URL and an access token. In the Databricks Unity File System Connector, we then specify the working directory where the output will be stored.
The last step is to write the ticket summaries and their metadata using the Parquet Writer node directly to Databricks Unity File System, making the data available for further processing or reporting.
The result: Simplified bug tracking
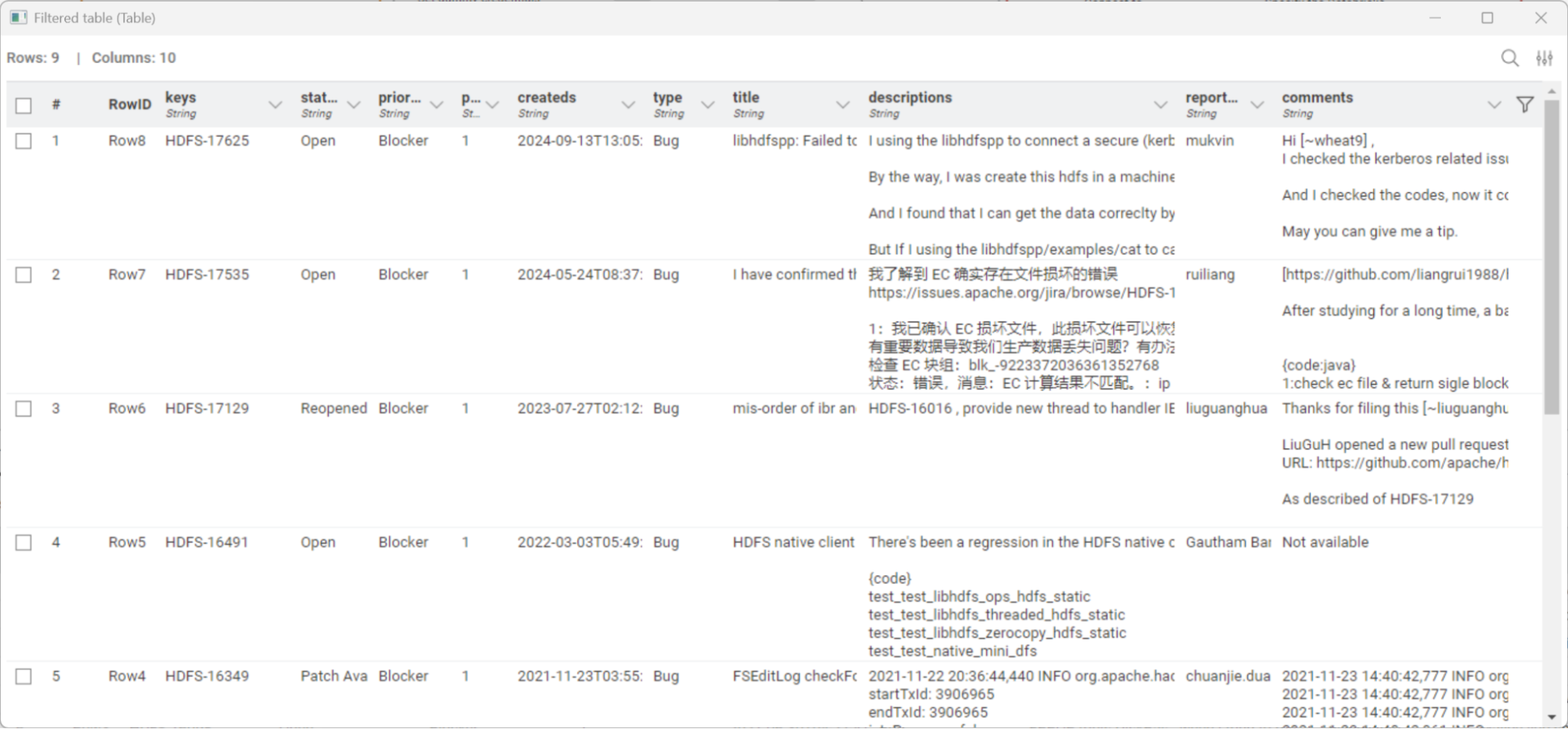
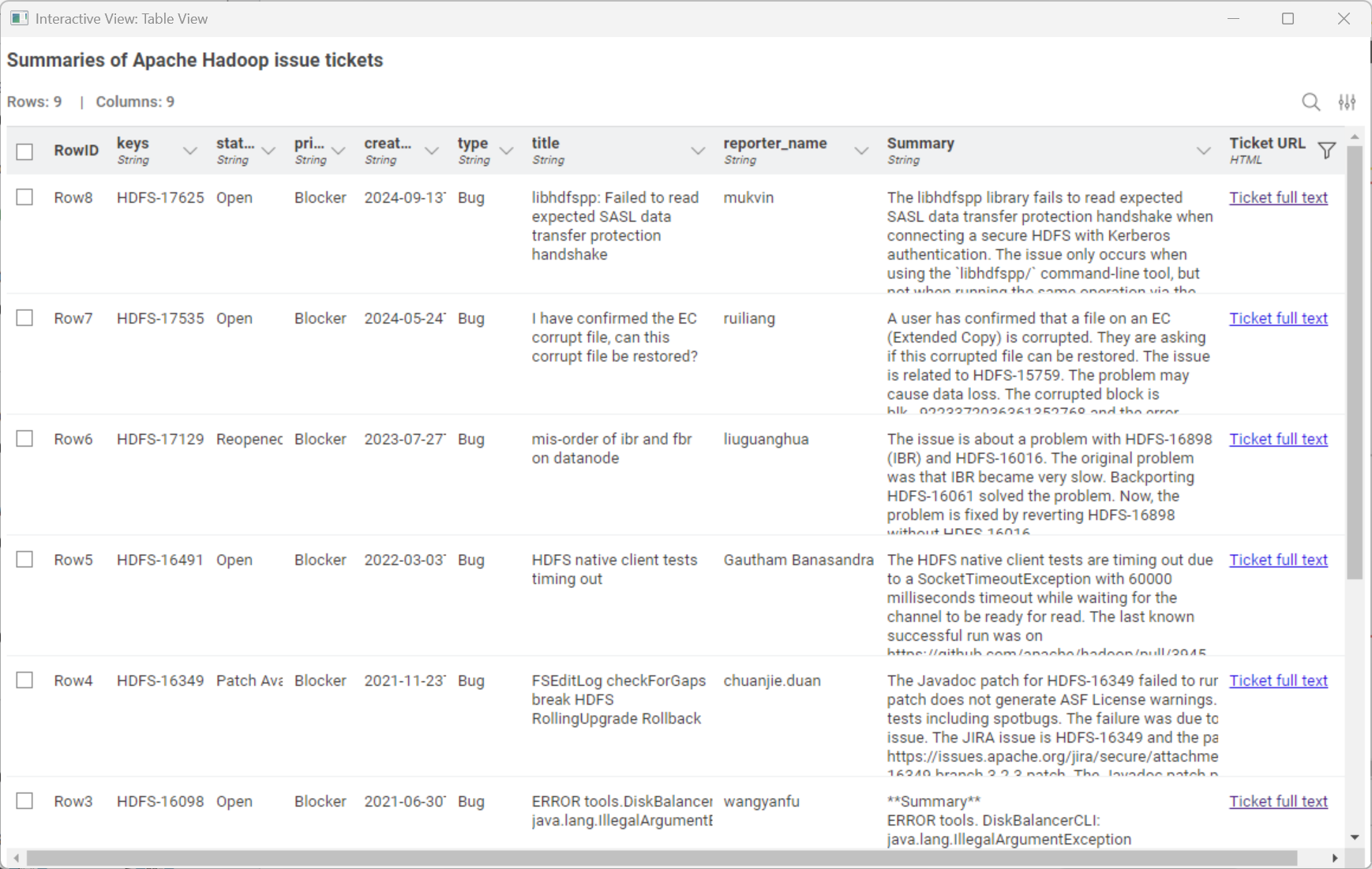
This workflow delivers clear, concise summaries of high-priority JIRA issue tickets for the Apache Hadoop project.
In addition to the summaries, the final table includes ticket titles, dates, priorities, statuses, and hyperlinks, providing a structured overview for decision-making. We can preview the result in the Table View node.
The Parquet output file ensures efficient storage into Databricks and scalability for additional analysis or visualization.
GenAI for summarization in KNIME
In this article from the Summarize with GenAI series, we explored how you can use KNIME and GenAI to automate the summarization of software bug reports in order to increase ticket management efficiency, save time, and ultimately improve software quality.
You learned how to:
- Automatically retrieve and parse Apache Hadoop issue tickets from Jira
- Use the KNIME AI extension to generate accurate ticket summaries
- Write the results as a Parquet file into Databricks