
April 4, 2021: Update: The Will They Blend ebook has just been updated again and the 3rd Edition of the book is available via the yellow Download button on the right. The update involved reviews of workflows to include more recent features of KNIME software.
Data often reside on different dislocated data sources: on your machine, in the cloud, in a remote database, on a web service, on social media, on hand-written notes (sigh…), in pdf documents - the list goes on and on.
One challenge all data scientists therefore encounter is accessing data of different types from different data sources and blending them together in a single data table to pass on to the next steps of the data analysis. Once the data have been collected and blended and are ready for pre-processing, analysis, and visualization, it is time to choose the technique for the particular task.
Which technique will it be?
One that is already embedded in KNIME Analytics Platform or a technique available in an external tool like Google API, Amazon ML Services, or Tableau, for example? Does part of your workflow need to run in R or Python? Do you need a combination of everything?
Seems like tool blending is another challenge that data scientists can encounter. But are data blending and tool blending really challenges? We argue that, for KNIME Analytics Platform, blending is not challenging at all.
To prove that, the “Will They blend?” e-book gathers together a variety of stories answering the questions on how to access data from different sources, how to blend them, and analyze using a variety of instruments.The first edition of the “Will They blend?” e-book was written in 2018. In terms of data storage and data science technology this is already quite a long time ago. Therefore, we have now updated and expanded the blending stories in it to the newest KNIME nodes and features as of KNIME Analytics Platform 4.2.
Eleven new chapters describe connectors to more than 20 additional data sources, web services, and external tools, as introduced in the most recent versions of KNIME Analytics Platform and KNIME Server.

Jump to summaries of the new chapters in the book by clicking the links below:
- The latest additions: Sharepoint, SAP, DynamoDB
- Cloud sources: Amazon S3, MS BlobStorage, Snowflake, Google BigQuery, Databricks.
- Databases: SQL and NoSQL
- Special Files: Zip archives, web crawling, Google Sheets, MDF, and more
- Web Services and Social Media: Google API, Amazon ML Services, Azure Cognitive Services, Twitter
- Data Science Tools and Reporting Tools: R, Python, Tableau, BIRT
The latest additions: Sharepoint, SAP, DynamoDB
Sharepoint
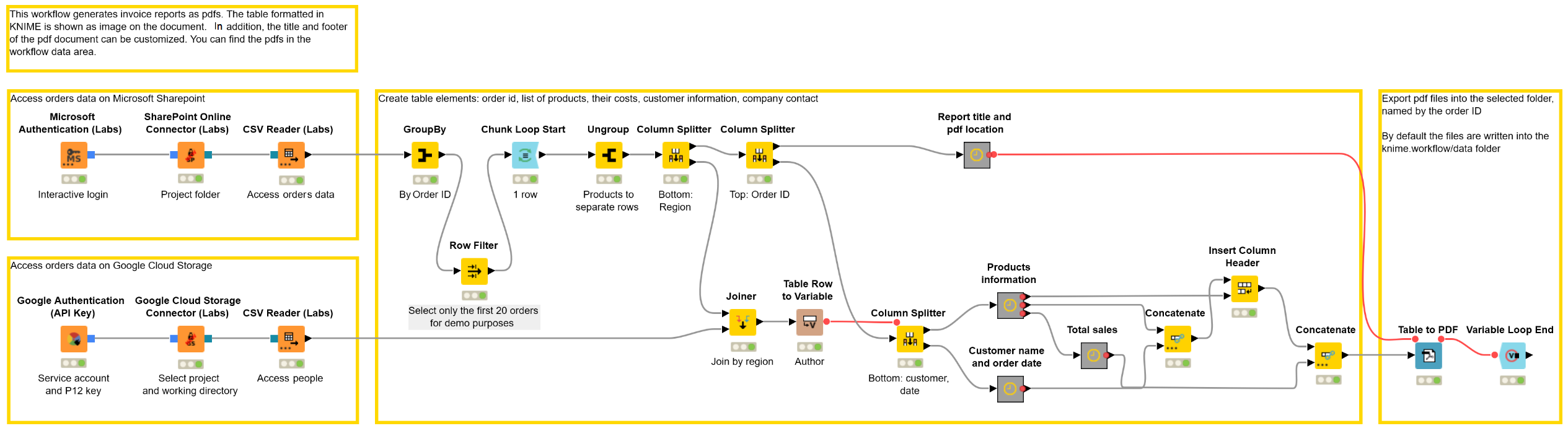
SharePoint is one of the latest integrations in the new File Handling Framework. The chapter “Microsoft Sharepoint meets Google Cloud Storage” shows an example workflow that connects to Sharepoint using the new SharePoint Online Connector node and connects to Google Cloud Storage to subsequently generate personalized invoices. Here you can see how the SharePoint Online Connector node manages, reads, and writes files to/from SharePoint within KNIME Analytics Platform (Fig. 1).
This example workflow, Microsoft Sharepoint meets Google Cloud Storage, blends the data, preprocesses the table into a shape that fits an invoice report, and exports the table into a pdf document with a custom title and footer. The procedure is automatically repeated for all orders in the data.
SAP
As of KNIME Analytics Platform 4.2, you need just one dedicated node - the SAP Reader (Theobald) to extract data from various SAP systems. In order to develop such a node, KNIME partnered with Theobald Software, one of the world’s leading experts in SAP integration. In the chapter “Theobald meets SAP HANA”, we access features of the ordered items using the new node and blend them with submitted orders data retrieved using a sequence of traditional DB nodes. After blending, we build an interactive KPI dashboard.
DynamoDB
The Amazon DynamoDB nodes allow you to seamlessly access and manipulate your data and tables in Amazon DynamoDB. The chapter “Amazon S3 Meets DynamoDB. Combining AWS Services to Access and query data” accesses data on Amazon S3, loads them directly to Amazon DynamoDB and performs various ETL operations using dedicated DynamoDB nodes..
Cloud sources: Amazon S3, MS BlobStorage, Snowflake, Google BigQuery, Databricks
Do you store your data on the cloud? Which of the many cloud options do you use?
Amazon S3 and MS BlobStorage
If you keep your data in Amazon S3 or in Microsoft Azure Blob Storage, the story “Amazon S3 meets MS Azure Blob Storage. A Match made in the Clouds.” blends data from both sources to analyze commuting time of workers.
Snowflake
Another option is Snowflake – a Software as a Service (SaaS) cloud data platform that can be deployed on Azure, AWS, or GCP globally. The updated story “Snowflake meets Tableau. Data warehouse in an hour?” is a detailed guide on how to start with Snowflake, download and register the JDBC driver and connect using the generic DB Connector node.
Google BigQuery & Databricks
If you want to access publicly available datasets from such rich storage platforms as Google BigQuery, you should definitely check the new story “Google BigQuery meets Databricks. Shall I rent a bike with this weather?”. First, it is environmentally friendly because it inspects the influence of weather on bike sharing usage. Second, it is also user friendly because it provides tips for connecting to Google BigQuery with the Google Authentication (API Key) and dedicated Google BigQuery Connector nodes and to Databricks – another cloud-based analytics tool for big data – with the Create Databricks Environment node.
Vendor neutral big data nodes
If you are interested in more opportunities to access, transform, and analyze big data, the stories, “Hadoop Hive meets Excel. Your Flight is boarding now!” and “SparkSQL meets HiveQL. Women, Men, and Age in the State of Maine” will guide you through. We use the Local Big Data Environment node for simplicity. It is very easy to use and play with if you want to quickly implement a prototype with various Spark nodes. But when you store big data, for example, on a Cloudera cdh5.8 cluster running on the Amazon cloud, you can simply replace the Local Big Data Environment node with the dedicated Hive Connector node. Or other KNIME Big Data connectors.
Databases: SQL and NoSQL
The joke that database admins couldn’t find a table in a NoSQL bar wouldn’t be that funny if its authors knew what KNIME Analytics Platform is capable of when it comes to blending. In the story “Blending Databases. A Database Jam Session.”, KNIME handles not only blending five SQL databases (PostgreSQL, MySQL, MariaDB, MS SQL Server and Oracle) but also one NoSQL database (MongoDB). As a result, the different customer data are aggregated in a single KNIME table that is then ready for further analysis. Could we blend even more databases? Sure. Just look for a dedicated connector node! If you can’t find one – download the JDBC driver for your favorite database, register it in KNIME Analytics Platform and use the generic nodes from the DB section in the Node Repository.
Special files: ZIP archives, web crawling, Google Sheets, MDF and more
Local and Remote ZIP files
Sometimes you need to blend data where some files are remote and some are saved locally. The story “Local vs. Remote Files. Will Blending Overcome the Distance?” blends remote and local ZIP archives to blend flight data from different periods of time in one bar chart for comparison.
Web Crawling & MS Word
Another close example is blending unstructured text data from the web and from a MS Word file. “MS Word meets Web Crawling. Identifying the Secret Ingredient.” is definitely our tastiest story – it successfully blends different Christmas cookies recipes to discover the secret ingredient! We know it is summer now, but who said that you can’t use this workflow to hunt for some hot summer lemonade secret ingredient?
Excel Files and Google Sheets
It probably should go without saying that such a powerful data analytics tool as KNIME can easily blend Excel files and Google Sheets, but, just in case, we have an example of this too! Check the “A Recipe for Delicious Data: Mashing Google and Excel Sheets”.
Text and Images
You might think that these formats are not that difficult to blend. Then, let’s take up something more challenging and blend something really different! For example, an image and a text. “Kindle epub meets Image JPEG. Will KNIME make peace between the Capulets and the Montagues?” The workflow described in this chapter blends one of the saddest books in the world (in our case, in epub format) with the photos from the Romeo and Juliet play into a network that shows a clear separation between the two families (they are the only ones in our book who don’t blend).
Handwritten Notes and Semantic Web
Another challenging story is “OCR on Xerox Copies meets Semantic Web. Have Evolutionary Theories Changed?”. It again successfully blends text data: one is stored in the pdf file and other – in the Semantic Web. The first is achieved by performing Optical Character Recognition with the Tess4J node, the second – with SPARQL Endpoint and SPARQL query nodes. If you want to learn more about querying Semantic Web OWL (Web Ontology Language) files, the new story “KNIME Meets the Semantic Web. Ontologies – or let’s see if we can serve pizza via the semantic web and KNIME Analytics Platform” will teach you how Triple File Reader node can help pizza experts extract some yummy data!
Apache Kafka and MDF
Excel, Word, PDF… tough automotive industry engineers may have gotten bored already… They probably think: “How about sensor measurements data, for example, for new engines testing?” Don’t get bored – KNIME has a solution for that too! The new story “MDF meets Apache Kafka. How’s the engine doing?” shows how to read MDF file format with the MDF Reader node, how to access the measurements data stored in a Cluster of the streaming platform Apache Kafka with Kafka Connector and Kafka Consumer nodes, and, of course, how to blend the measurements into the line chart for efficient testing of the new engine.
Web Services and Social Media: Google API, Amazon ML Services, Azure Cognitive Services, Twitter
Google API
Google API are very popular web services. You can get all sorts of information from them, like news, translations, youtube analytics, or pure search results.
We already mentioned Google API for retrieving public data from Google BigQuery and news from Google News. Another four stories involving Google API are:
-
- “Open Street Maps meets CSV Files & Google Geocoding API”,
- “YouTube Metadata Meet WebLog Files. What Will it be Tonight – a Movie or a Book?”
- “Finnish Meets Italian and Portuguese through Google Translate API. Preventing Weather from Getting Lost in Translation.”
- “IBM Watson meets Google API”.
Amazon ML Services
By the way, as for automatic translation, one possible alternative to Google Translate API is Amazon Machine Learning (ML) Services which include a translation service. The new story “Amazon ML Services meets Google Charts. Travel Risk Guide for Corporate Safety” estimates travel risks: first, on a global level by visualizing the risks for each country on a Google world map using the Choropleth World Map component; and then, by analyzing local news for a particular country of interest. This is where Amazon Authentication and Amazon Translate nodes come into play: they help to translate local news to the desirable language. But it is not all: the workflow also applies Amazon Comprehend nodes to estimate the sentiment of the news alerts and extract key phrases, for example. As a result, Google charts and Amazon ML Services blend in one travel risk guide (Fig. 2).
Azure Cognitive Services and Twitter
We’ve also got a story for those who prefer to conduct their sentiment analysis with Microsoft Azure instead of Amazon. The new story “Twitter and Azure. Sentiment Analysis via API.” extracts tweets with Twitter API Connector and Twitter Search nodes and passes them into Azure Cognitive Services using POST Request node. By the way, since Twitter only allows your to extract recent tweets, you might be interested in the “Twitter meets PostgreSQL. More Than Idle Chat?” story, which blends recent data from Twitter with the older data stored in, for example, a PostgreSQL database.
Data Science Tools and Reporting Tools: R, Python, Tableau, BIRT
Tableau and BIRT
The Tableau integration has also been updated and now builds on the new Tableau Hyper API to ensure better compatibility and easy installation. Check the new node Tableau Writer in the updated “BIRT meets Tableau and JavaScript. How Was The Restaurant?” story.
Python and R
Of course, we could not pass by fans of writing a piece of code themselves. In our story “A Cross-Platform Ensemble Model. R Meets Python and KNIME. Embrace Freedom in the Data Science Lab!”, we easily integrate two programming languages most beloved by data scientists into the KNIME Analytics Platform to train classical machine learning classification models on R, Python and KNIME. For that, we just need dedicated Python Learner, Python Predictor, R Learner and R Predictor nodes. We then ensemble predictions obtained from three different platforms using just one Prediction Fusion node. Isn’t it a fantastic blending?
Stay tuned!
To sum up, the second edition of the “Will They Blend” e-book is now available for download after updating and expanding it for KNIME Analytics Platform 4.2.
The updating procedure was quite a massive amount of work. We replaced deprecated and legacy nodes (even though all deprecated and legacy nodes still work and process your data without any changes), replaced deprecated services, and replaced the public data that disappeared from the web within 2 years.
We expanded the e-book with new stories including those with the latest nodes: SharePoint Online Connector, SAP Reader (Theobald), Amazon DynamoDB and Tableau Writer. One of the stories we are aiming to write next is about newly created dedicated Salesforce nodes. What could we blend them with… ?
Like all e-books in KNIME Press, Will They Blend? is a live e-book. Every time a connector to a new data source is made available in a new release of KNIME Analytics Platform and an example workflow is created, the respective story is added to the PDF document.