
Data science is one of the fastest-growing fields today, with a projected job growth rate of 35% from 2022 to 2032. But what exactly is it, why does it matter — and how is it changing in the era of AI?
In this guide, we explain the fundamentals of data science, and how artificial intelligence (AI) is changing the way data science work gets done — from exploration to modeling to decision-making.
We also look at how the data science process is changing — combining classic methods with AI, for example, to take care of more routine tasks, and in some cases, relying on AI alone. For instance, instead of writing custom summaries of results for stakeholders, a data scientist might use AI to generate a narrative report based on the analysis automatically.
You’ll see how data science is applied in real-world use cases across industries, from retail to healthcare to manufacturing. We’ll share examples of how data scientists can integrate AI into their processes to enhance, streamline, or even rethink certain steps.
Table of contents:
What is data science?
Classic data science is an interdisciplinary field that concentrates on extracting knowledge from datasets, applying this knowledge to solve problems, and drawing conclusions that inform business decisions.
It uses concepts and techniques from statistics, mathematics, programming, artificial intelligence (AI), and machine learning (ML) to extract knowledge and insights from both structured and unstructured data. It involves collecting, cleaning, analyzing, visualizing, and interpreting complex datasets to inform decision-making, solve business problems, and drive innovation.
Data science aims to use insights gained from analyzing past data to create models and train algorithms that forecast future outcomes and drive actionable recommendations. This approach is often structured as a repeatable cycle that guides how data science projects are carried out.
The version below outlines the classic cycle. We’ll walk through the updated process in the section “What do data scientists do?”
The classic data science cycle:
- Import the data: Define the problem
- Clean the data and prepare the data: Collect and structure the inputs
- Explore the data: Analyze and model
- Test & Optimize model: Evaluate performance and refine
- Communicate insights: Share findings in the right context
- Automate and deploy solutions: Operationalize the workflow
- Continue learning and experimenting: Adapt and improve over time
Each step in the cycle contributes to answering core business questions. In addition to answering questions like “What happened?” and “Why did it happen?”, data science goes further to ask “What will happen next?” and “How can we make it happen?” It integrates historical analysis and forward-looking techniques.
Four different types of analytics
In practice, this progression plays out across different types of analytics — each aligned with a specific kind of question and role:
- Descriptive analytics looks at what happened. It analyzes past trends and events, often led by data analysts, though data scientists may also use these insights as a starting point.
- Diagnostic analytics asks why it happened. This involves identifying causes and correlations, typically handled by data analysts, with data scientists stepping in for deeper investigation.
- Predictive analytics focuses on what will happen next based on what happened. Here, data scientists apply statistical models and machine learning to forecast future outcomes.
- Prescriptive analytics explores how to make it happen. This is where data scientists combine modeling, simulation, and business knowledge to recommend specific actions.
Each layer builds on the last, moving from historical understanding toward insight and action.
Before we look deeper into the data science process, it’s useful to distinguish it from a closely related field: data analytics. While the two are often mentioned together, they serve different purposes in the data space.
The table below highlights the key differences between data analytics and data science. While data analytics focuses on understanding what has already occurred using statistical methods and visualization, data science goes a step further by leveraging advanced techniques to predict future outcomes and guide strategic decisions. Together, these disciplines complement each other to provide a comprehensive approach to making data-driven decisions.
| Aspect | Data Analytics (DA) | Data Science (DS) |
| Focus | Understanding past events and trends | Integrating historical insights with predictive and prescriptive methods |
| Methods | Statistical analysis, reporting, visualization | Machine learning, predictive modeling, selecting and applying suitable algorithms |
| Main Questions | Explain what happened and why it happened | Forecast future outcomes and recommend data-driven actions |
| Approach | Retrospective analysis | Proactive and experimental, often incorporating real-time data |
| Role of GenAI | Helps speed up reporting and surface insights from large datasets | Supports model development, ideation, and workflow acceleration |
What is AI's role in data science?
Artificial intelligence is becoming an integral part of data science. It can support various stages of the data science process — from automating tasks and detecting anomalies to preparing, cleaning, and analyzing datasets. AI also helps generate code, summarize results, build quick prototypes or query data in natural language. These technologies introduce new ways to work with data by making the process faster, more accessible, and more iterative.
But even as AI becomes more capable, it still builds on the same foundations data science has always relied on: clean inputs, reproducible workflows, and clearly defined problems. When AI handles tasks like data exploration or forecasting, core principles like transparency, structure, and domain understanding continue to shape the outcome.
AI introduces new interfaces, such as natural language prompts or auto-generated code, that streamline early steps in the process and accelerate experimentation. Agentic AI goes a step further: instead of assisting with individual tasks, it can coordinate and automate multiple stages in a workflow to achieve a defined objective. Depending on how it's configured, it can pull in the right data, models, and tools — and execute them with varying levels of autonomy.
This shift in technology also introduces a shift in mindset. Data scientists increasingly move from manually coding every step to working alongside intelligent systems — guiding, refining, and iterating through collaboration. Whether using traditional methods, AI-powered technology, or a combination of both, the goal remains the same: generating reliable insights that support better decisions.
With AI now part of the toolkit, the steps in a typical data science project are also evolving. The process now includes an additional step: evaluating the trustworthiness of AI-supported outputs.
This step is especially important with the introduction of generative and autonomous AI systems. These models can produce outputs that are difficult to verify, may introduce hallucinated or biased results, and often lack transparency in how conclusions are reached. Because of this, data scientists need to evaluate not just the performance of the model, but also the reliability and explainability of AI-generated outputs — particularly when those outputs influence downstream decisions.
That’s why trustworthiness is no longer just a best practice — it’s a requirement for responsible, AI-integrated data science.
The modern data science cycle:
- Import the data: Define the problem
- Clean the data and prepare the data: Collect and structure the inputs
- Explore the data: Analyze and model
- Test & Optimize model: Evaluate performance and refine
- Ensure trustworthiness: Validate results and processes
- Communicate insights: Share findings in the right context
- Automate and deploy solutions: Operationalize the workflow
- Continue learning and experimenting: Adapt and improve over time
This updated cycle reflects that shift and will be explored step by step in the section, “What do data scientists do.”
Why is data science important?
Data science is essential for making sense of the growing volumes of data generated across industries. It helps organizations uncover patterns, make evidence-based decisions, and respond to change with greater speed and accuracy. By combining domain expertise with statistical and computational techniques, data science turns raw information into practical insight.
Its value lies not only in understanding what happened but in anticipating what’s likely to happen next and determining the best course of action.
For example, a car manufacturer might use data science to detect quality issues on the production line, predict when equipment needs maintenance, or optimize inventory across suppliers. These insights can reduce costs, prevent delays, and improve product quality. The same principles apply across fields, from healthcare to finance to logistics.
Data science use cases
The applications of data science are vast, spanning nearly every industry that relies on data to inform decision-making. While the specifics vary by field, the fundamental role remains the same: transforming raw data into actionable insights. Whether it’s optimizing operations, predicting future trends, or automating complex tasks, data science helps organizations make smarter, more informed decisions.
These capabilities are now being extended with generative models — particularly in areas involving unstructured data, such as text or images, and in automating routine analysis and reporting tasks. Its usefulness still depends on well-framed questions, clear objectives, and reliable data.
The most common examples of what data science can help provide in use cases include:
- Forecasting sales revenue, market demand, or equipment failures – Typically achieved through time series analysis and predictive modeling .
- Segmenting customers, products, or behaviors into meaningful groups – Done using classification models or clustering techniques, including traditional machine learning and neural networks.
- Recommending products, services, or content to users – Powered by a recommendation engine that analyzes past behavior. GenAI adds value by generating personalized content, such as dynamic product descriptions or messaging.
- Detecting fraud, cybersecurity threats, or operational anomalies – Achieved through anomaly detection models, increasingly combined with real-time monitoring supported by large language models (LLMs).
- Extracting insights from text, chatbots, or voice interactions – Enabled by natural language processing (NLP). GenAI extends this by supporting summarization, topic extraction, and automated content creation from prompts.
- Enhancing quality control or diagnostics through image recognition – Deep learning models are used for tasks like facial recognition or detecting defects. Generative tools can also create synthetic training data.
- Designing experiments and evaluating business strategies – A/B testing, impact measurement, and validation processes are supported by statistical analysis and, in some cases, GenAI-generated test variants.
- Understanding customer sentiment across channels – Sentiment analysis tools help parse opinions, tone, and intent. LLMs can detect more nuanced expressions such as sarcasm or shifting sentiment.
- Interpreting spoken language for assistants or support systems – Voice and speech recognition systems, often powered by foundation models fine-tuned for specific domains.
The combinations of scalable infrastructure, traditional machine learning, and now generative models are expanding what’s possible. These advances are showing up in real-world applications across industries.
Industry-specific data science applications
Since data science is fundamentally about making sense of vast amounts of data, its value extends across industries. Generative AI is enhancing some of these use cases — especially where automation, personalization, or language processing is involved. It helps make automation faster and more flexible by generating code or content on demand. It improves personalization by enabling scalable, dynamic responses tailored to individual user behavior. It advances language processing by handling more complex queries, generating summaries, or adapting to tone and context in a way traditional systems often can’t.
Here are some common examples of how businesses apply data science to drive efficiency and innovation:
- Finance and banking – Banks use machine learning models to assess loan risks, flag fraudulent transactions, and optimize investment strategies. Credit scoring systems evaluate factors like credit history and income levels to determine a borrower's likelihood of repayment.
- Healthcare and life sciences – Hospitals use data science to detect early signs of disease and optimize treatments. GenAI is now being tested for tasks like clinical note summarization or generating research literature reviews, though regulatory caution remains high.
- Retail and e-commerce – Online retailers leverage customer purchase history, browsing behavior, and demographic data to personalize shopping experiences, recommend products, and optimize pricing strategies. Inventory forecasting also helps prevent stockouts and overstocking.
- Supply chain and logistics – Companies like FedEx and Amazon use data science to optimize delivery routes, reduce fuel costs, and manage warehouse inventory. Predictive analytics helps forecast demand and prevent supply chain disruptions.
- Media and entertainment – Streaming platforms like Netflix and Spotify analyze user preferences to suggest movies, TV shows, or music. By identifying patterns in viewing behavior, they can create highly personalized recommendations.
- Manufacturing and quality control – Factories implement predictive maintenance to monitor equipment and prevent costly breakdowns. Computer vision technology ensures quality control by detecting defects in products before they reach consumers.
Many industries that now rely on data science existed long before it became a defined discipline. But the combination of cloud computing, AI, and now generative models is expanding what’s possible. From enabling non-technical teams to interact with data through natural language, to generating new content or test scenarios, GenAI is extending the reach of data science — not replacing it.
What remains unchanged is the need for structured thinking, well-prepared data, and clear alignment with business goals. Companies that integrate data science thoughtfully — and treat GenAI as an accelerator, not a shortcut — are better positioned to innovate, adapt, and stay competitive.
What is a data scientist?
Data scientists are professionals who use techniques from statistics, mathematics, AI, machine learning (ML), and related fields — combined with domain expertise — to extract valuable insights from data. They uncover patterns and trends that inform business decisions, improve products and services, and drive innovation.
As generative AI becomes more integrated into the analytics toolkit, the role of the data scientist is evolving. Routine tasks like writing code, summarizing data, or even generating first-draft reports are becoming more automated. Rather than making data scientists obsolete, automation allows them to focus on what matters more: clarifying objectives, ensuring ethical model use, and validating insights in real-world contexts.
What do data scientists do?
Data scientists transform raw data into actionable intelligence through a systematic process known as the data science life cycle. These steps reflect the updated cycle — one that integrates AI, where useful, while still relying on structured thinking, clean data, and human oversight. It’s a repeatable structure, but flexible enough to adapt to unique challenges in different domains.
Let’s take a closer look at how the modern data science process works in practice:
Step 1: Import the data — Define the problem
Before diving into data, a data scientist collaborates with business stakeholders to define the problem at hand. This step is critical, as it ensures that the analysis aligns with organizational goals. By understanding the business context, data scientists can ask the right questions that drive meaningful insights.
How AI can help
AI can help explore early hypotheses and reframe vague business needs into structured analytical questions — but this process still depends on clear context and communication.
For example:
- Business problem: Why is there a sudden drop in sales for a specific product?
- Data science question: What factors influence the sales trends for this product, and can we predict when sales will bounce back?
AI can support this step by suggesting relevant questions, refining problem statements, or helping map business challenges to potential data solutions. It can also offer guidance on what data may be needed based on similar problem types, helping teams get started faster.
Step 2: Clean and prepare the data — Collect and structure the inputs
Raw data is often messy, incomplete, or stored in multiple systems. A significant part of a data scientist's job involves data collection and cleaning. This may involve gathering data from various internal and external sources, such as databases , APIs , or even web scraping .
Once the data is collected, it needs to be cleaned and transformed into a usable format. This can include:
- Handling missing values
- Removing outliers
- Normalizing data for consistency
- Combining data from multiple sources
This process, known as data wrangling, ensures that the data is accurate, complete, and ready for analysis. While large language models can suggest SQL queries or flag schema issues, they still depend on human judgment to assess data quality, handle bias, and resolve inconsistencies across sources.
How AI can help
AI can assist with routine preparation tasks like identifying duplicates, handling missing values, or suggesting transformations. It can also detect outliers or recommend ways to merge datasets. Automating parts of this step frees up time for more complex decision-making around data quality and relevance.
Step 3: Explore the data — Analyze and model
Once the data is ready, data scientists apply statistical analysis, machine learning algorithms, and AI models to analyze the data and extract insights. This is where they use their technical skills.
- Exploratory data analysis (EDA): Data scientists first explore the data visually and statistically to uncover patterns, correlations, and distributions. This helps inform the next steps in modeling.
- Building predictive models: Data scientists use machine learning algorithms (e.g., regression, classification, and clustering) to build models that can predict future trends or outcomes. For instance, a model might predict future sales based on past trends and seasonality.
- GenAI support in modeling: Generative tools may assist in generating boilerplate code or suggesting modeling approaches, but selecting the appropriate algorithm — and interpreting its output — still depends on the data scientist’s judgment. This is especially important when working with generative models, which can introduce risks like hallucinated outputs, hidden bias, or poor explainability if not carefully validated.
- Evaluating models: After building the models, data scientists evaluate their performance using metrics such as accuracy, precision, recall, and R-squared. This helps determine how well the model is performing and whether it can be trusted for decision-making.
How AI can help
AI can speed up this stage by generating initial model code, suggesting algorithms based on the dataset, or automatically evaluating model performance. AI systems can also manage parts of the modeling workflow, such as testing approaches or optimizing parameters — while keeping the data scientist in control.
Step 4: Test and optimize the model — Evaluate performance and refine
Once a model has been built, it needs to be evaluated against real-world conditions and business goals. This includes selecting relevant metrics (such as accuracy, precision, recall, or RMSE), comparing models, and fine-tuning parameters to improve results. Testing ensures that the model performs well not only on historical data but also generalizes to new, unseen data.
Model optimization may involve hyperparameter tuning, feature selection, or rebalancing training data. In regulated environments, this step also plays a role in documenting model performance for audits or compliance.
How AI can help
AI can assist with model evaluation by automating metric calculation, flagging performance gaps, or even suggesting hyperparameter configurations. It can also surface explainability concerns or identify overfitting by comparing multiple training runs. This allows data scientists to focus on refining strategy, not just tweaking code.
Step 5: Ensure trustworthiness – Validate results and processes
Validation is key to building confidence in the results. This includes checking data quality, evaluating model performance, and documenting processes. With AI entering the workflow, ensuring trust becomes a central concern. Trustworthiness includes reproducibility, transparency, and the ability to explain results — not just from models, but also from AI-generated suggestions.
Why is this important?
Generative and agentic systems can introduce complexity or opacity into the workflow. It’s critical to track how insights are derived, validate outputs, and ensure that every step, whether AI-assisted or not, is auditable.
Step 6: Communicating insights — Share findings in the right context
A key responsibility of a data scientist is communicating their findings to non-technical stakeholders. This step involves turning complex analyses and technical jargon into understandable insights that can guide business decisions.
Data scientists often create:
- Data visualizations: Charts, graphs, and dashboards that visually represent data insights.
- Reports and presentations: Summarizing key findings, explaining models, and offering actionable recommendations.
How AI can help
AI can summarize findings, generate visualizations, and even draft report text based on results. It can tailor insights to different audiences or recommend the most relevant points to highlight. While AI can support communication, the final message still benefits from human insight and context.
AI can help draft summaries or generate natural language descriptions of findings, but effective communication still requires tailoring the message to specific audiences and business contexts.
For example, a data scientist might present a predictive model that forecasts a rise in customer churn and, based on the findings, suggests strategies for retention.
Step 7: Automating and deploying solutions — Operationalize the workflow
Once insights are extracted, data scientists often build automated solutions that can continuously analyze new data. This involves creating models that automatically update and adapt as new data comes in, enabling real-time decision-making without manual intervention.
- Model deployment: The final models are often deployed into production environments where they can be integrated into business systems, such as customer recommendation engines or fraud detection systems. This allows the business to act on insights instantly.
How AI can help
AI can monitor data pipelines, trigger retraining workflows, or automate deployment tasks. It can also track model performance and alert teams to changes or degradation. This allows for more responsive and scalable deployments with less manual oversight.
Step 8: Continuous learning and experimentation — Adapt and improve over time
With tools like GenAI reshaping how data work gets done, staying curious is one of the most valuable habits a data scientist can build. New platforms, faster methods, and shifting business needs mean there’s always something worth exploring. That doesn’t mean chasing every new trend, it’s about experimenting, asking better questions, and building on what you already know. That’s what keeps the work sharp, relevant, and rewarding.
Many teams are experimenting with how to integrate AI into their workflows — not as a replacement, but as a way to iterate faster and explore alternative strategies.
How AI can help
AI can support learning and experimentation by helping data scientists test hypotheses faster, simulate variations, or explore unfamiliar methods with lower effort. It can generate alternative approaches to a problem, suggest new variables to consider, or summarize learnings from past experiments. By lowering the barrier to trying new things, AI encourages a mindset of continuous improvement.
How to become a data scientist
Data science is a lucrative career, not only because it's one of the fastest-growing occupations — with demand consistently outpacing supply — but also because it pays well. According to Glassdoor, the average data scientist salary in the US is $118,281 per year, with total average compensation reaching $164,241.
So, what skills and qualifications do you need to pursue this career?
Traditionally, many data scientists have come from backgrounds in software engineering, mathematics, statistics, or computer science. While it’s common to have at least a bachelor’s degree — and many have master’s or PhDs — the field doesn’t require a specific academic background. With the field becoming more democratized, it’s increasingly possible for individuals without these specialized backgrounds to enter data science through alternative learning paths.
Skills in programming, statistics, and machine learning are still valuable, but they’re no longer the only entry points. The rise of visual, low-code platforms like KNIME is lowering technical barriers while expanding what learners can try, test, and deploy. In this new landscape, curiosity, problem-solving, and an ability to frame analytical questions are just as important as writing code.
That said, generative AI is also changing the expectations for data professionals. Some routine steps — like scripting or summarizing — are now quicker to complete. At the same time, expectations for interpretation, bias detection, and ethical oversight are rising.
In practice, many data scientists begin as analysts, building foundational skills in data wrangling, visualization, and business problem-solving. From there, they may move into advanced areas like machine learning, artificial intelligence, or data engineering — depending on their interests and team needs.
Ultimately, while technical fluency is still a strength, there are now more pathways than ever to build a meaningful data science career — especially for those willing to learn continuously and adapt to new tools. Getting started is often as simple as completing a certification or following a structured learning path.
How to get started applying data science
One way data scientists can speed up their process — and ensure quality — is by using a low-code tool like KNIME Analytics Platform. If you start visual workflows, you can dive right into the concepts without needing to learn the basics of coding first.
KNIME’s visual approach reduces the barrier to entry, but integrating code is also possible for those who want it.
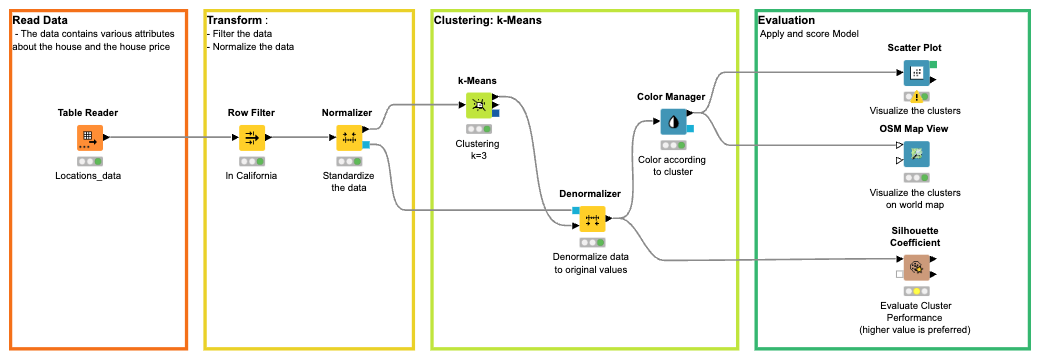
If you're just getting started, you can take data science courses and follow the data scientist learning path with KNIME. These hands-on courses take you from data access basics through to building and deploying your own code-free ML model.
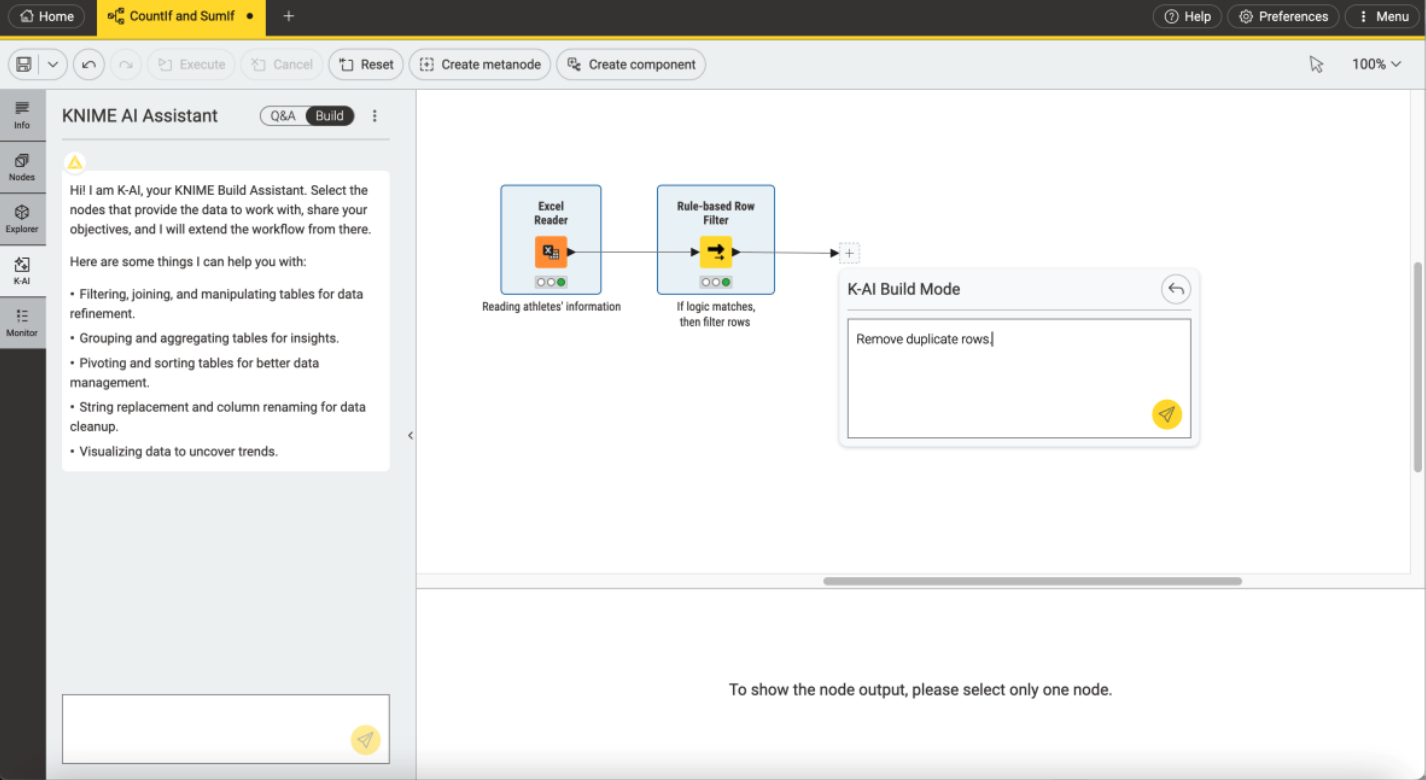
KNIME has a built-in AI assistant — K-AI which makes it easier to learn as you go. You can chat with K-AI, ask it for help, and make suggestions for the next steps, how to deal with errors, and more. Because it’s embedded in your workflow, it provides support that’s both timely and specific.
Find out what type of data scientist you might be
By now, you’ve seen that data science isn’t one-size-fits-all. From wrangling messy data to deploying machine learning models or building interactive dashboards, the role varies widely depending on your strengths and interests. Knowing your working style can help you focus your learning — and make smarter decisions about the tools, methods, and roles that suit you best.
Curious about where you might fit in?
Take this short quiz to see what kind of data scientist you might be:
Learn data science with a tool that lets you grow
One of the great benefits of KNIME is its flexibility. It doesn’t lock you into a particular way of working, it grows with your needs. As you progress from beginner to advanced, KNIME allows you to go from drag-and-drop exploration to building reusable components, deploying models, or integrating AI into your workflows. This means that whether you're just starting out or are ready to tackle more challenging projects, KNIME adapts to support your evolving skill set and career path in data science.
Explore courses, learning paths, and certification programs to start building real workflows and solving real problems with data.